

Noise correlations in the human brain and their impact on pattern classification
- PMID: 28841641
- PMCID: PMC5589258
- DOI: 10.1371/journal.pcbi.1005674
Noise correlations in the human brain and their impact on pattern classification
Abstract
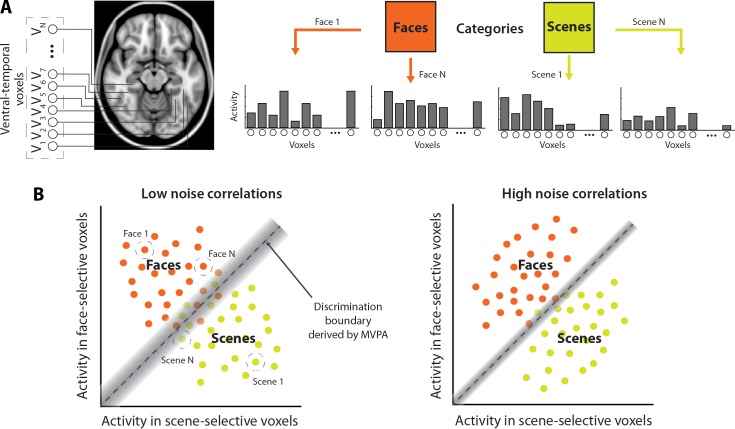
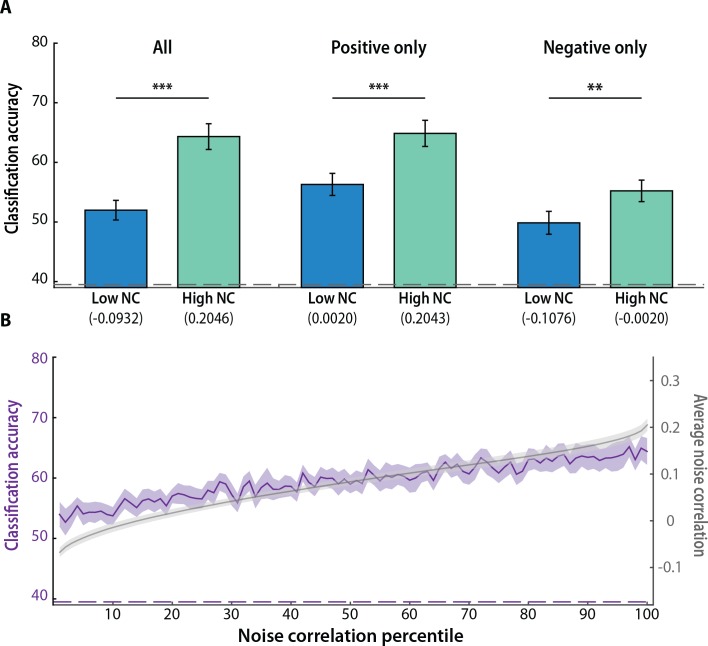
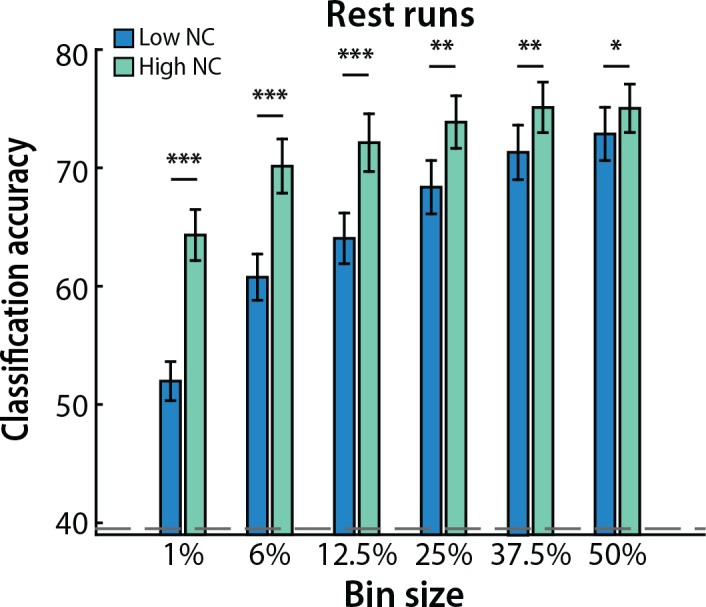
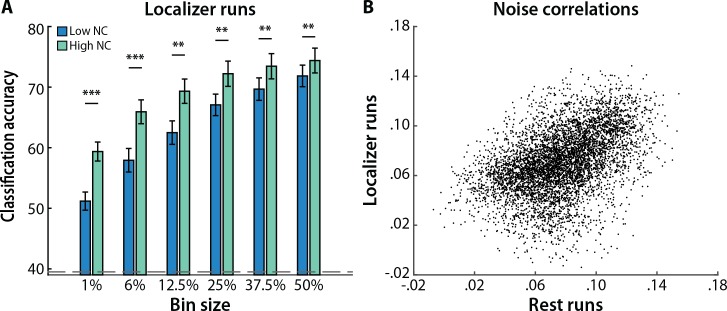
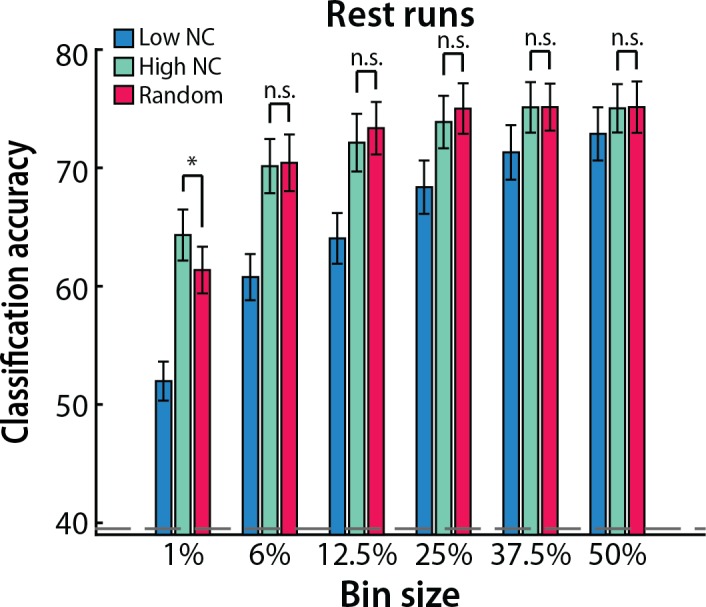
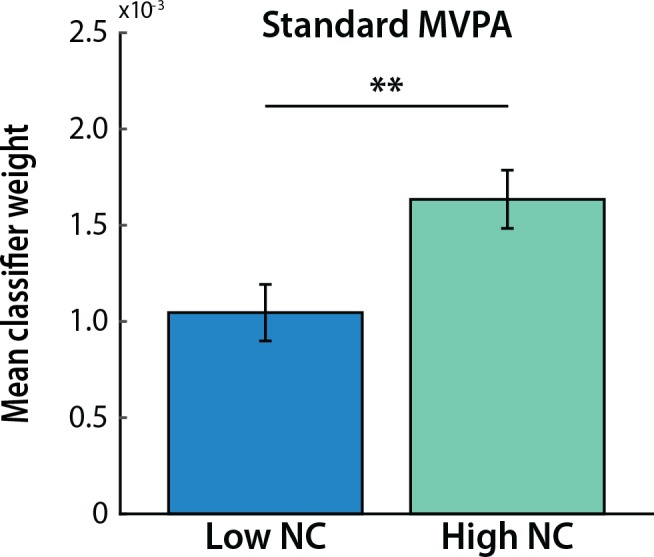
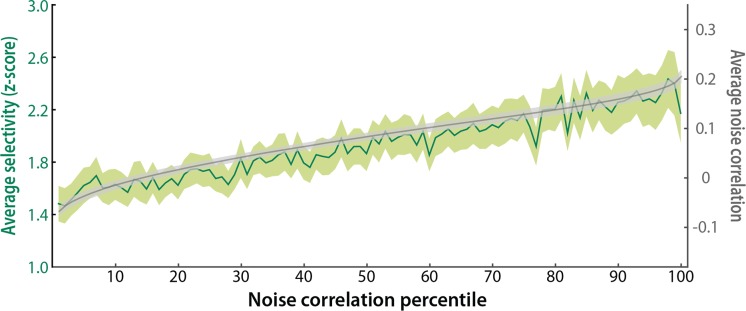
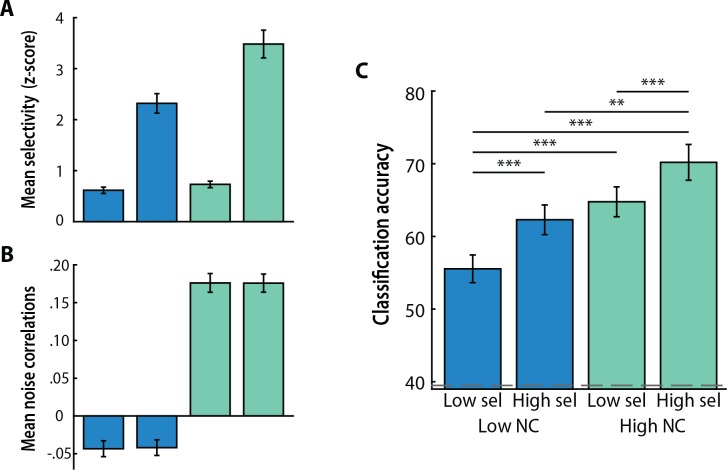
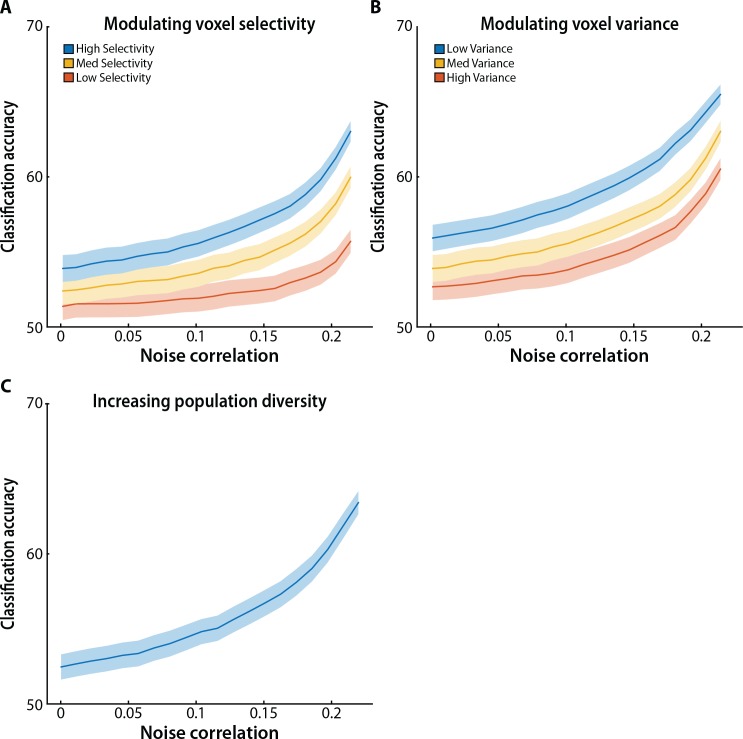
Multivariate decoding methods, such as multivoxel pattern analysis (MVPA), are highly effective at extracting information from brain imaging data. Yet, the precise nature of the information that MVPA draws upon remains controversial. Most current theories emphasize the enhanced sensitivity imparted by aggregating across voxels that have mixed and weak selectivity. However, beyond the selectivity of individual voxels, neural variability is correlated across voxels, and such noise correlations may contribute importantly to accurate decoding. Indeed, a recent computational theory proposed that noise correlations enhance multivariate decoding from heterogeneous neural populations. Here we extend this theory from the scale of neurons to functional magnetic resonance imaging (fMRI) and show that noise correlations between heterogeneous populations of voxels (i.e., voxels selective for different stimulus variables) contribute to the success of MVPA. Specifically, decoding performance is enhanced when voxels with high vs. low noise correlations (measured during rest or in the background of the task) are selected during classifier training. Conversely, voxels that are strongly selective for one class in a GLM or that receive high classification weights in MVPA tend to exhibit high noise correlations with voxels selective for the other class being discriminated against. Furthermore, we use simulations to show that this is a general property of fMRI data and that selectivity and noise correlations can have distinguishable influences on decoding. Taken together, our findings demonstrate that if there is signal in the data, the resulting above-chance classification accuracy is modulated by the magnitude of noise correlations.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
References
-
- Norman KA, Polyn SM, Detre GJ, Haxby JV. Beyond mind-reading: multi-voxel pattern analysis of fMRI data. Trends in cognitive sciences. 2006;10(9):424–30. doi: 10.1016/j.tics.2006.07.005 - DOI - PubMed
-
- Turk-Browne NB. Functional interactions as big data in the human brain. Science. 2013;342(6158):580–4. doi: 10.1126/science.1238409 - DOI - PMC - PubMed
-
- Yarkoni T, Poldrack RA, Nichols TE, Van Essen DC, Wager TD. Large-scale automated synthesis of human functional neuroimaging data. Nat Methods. 2011;8(8):665–70. doi: 10.1038/nmeth.1635 - DOI - PMC - PubMed
-
- Kanwisher N. Functional specificity in the human brain: A window into the functional architecture of the mind. PNAS. 2010;107(25):11163–70. doi: 10.1073/pnas.1005062107 - DOI - PMC - PubMed
-
- Kim H. Neural activity that predicts subsequent memory and forgetting: A meta-analysis of 74 fMRI studies. Neuroimage. 2011;54(3):2446–61. doi: 10.1016/j.neuroimage.2010.09.045 - DOI - PubMed
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
