

Systematic identification of feature combinations for predicting drug response with Bayesian multi-view multi-task linear regression
- PMID: 28881998
- PMCID: PMC5870540
- DOI: 10.1093/bioinformatics/btx266
Systematic identification of feature combinations for predicting drug response with Bayesian multi-view multi-task linear regression
Abstract
Motivation: A prime challenge in precision cancer medicine is to identify genomic and molecular features that are predictive of drug treatment responses in cancer cells. Although there are several computational models for accurate drug response prediction, these often lack the ability to infer which feature combinations are the most predictive, particularly for high-dimensional molecular datasets. As increasing amounts of diverse genome-wide data sources are becoming available, there is a need to build new computational models that can effectively combine these data sources and identify maximally predictive feature combinations.
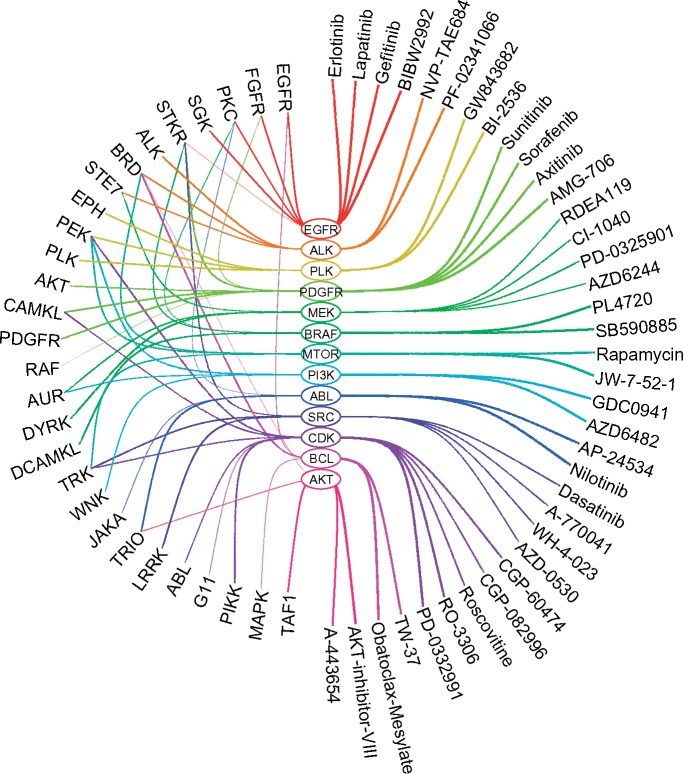
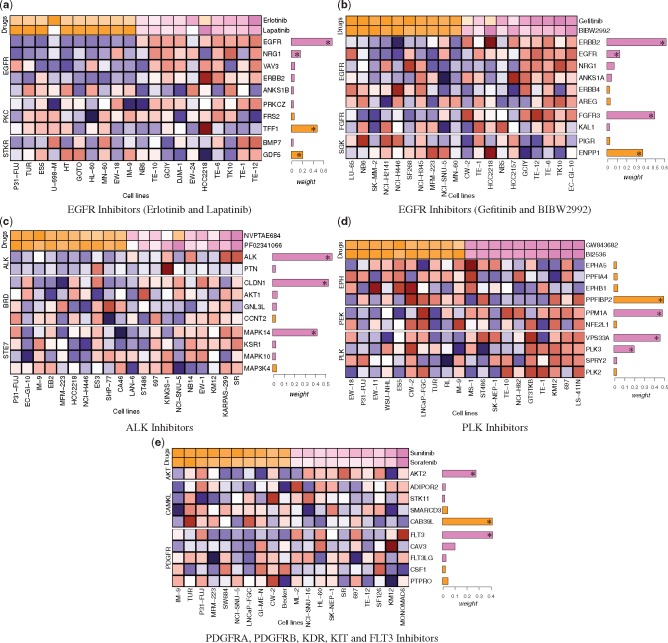
Results: We present a novel approach that leverages on systematic integration of data sources to identify response predictive features of multiple drugs. To solve the modeling task we implement a Bayesian linear regression method. To further improve the usefulness of the proposed model, we exploit the known human cancer kinome for identifying biologically relevant feature combinations. In case studies with a synthetic dataset and two publicly available cancer cell line datasets, we demonstrate the improved accuracy of our method compared to the widely used approaches in drug response analysis. As key examples, our model identifies meaningful combinations of features for the well known EGFR, ALK, PLK and PDGFR inhibitors.
Availability and implementation: The source code of the method is available at https://github.com/suleimank/mvlr .
Contact: muhammad.ammad-ud-din@helsinki.fi or suleiman.khan@helsinki.fi.
Supplementary information: Supplementary data are available at Bioinformatics online.
© The Author 2017. Published by Oxford University Press. All rights reserved. For Permissions, please e-mail: journals.permissions@oup.com
Figures
References
-
- Ammad-Ud Din M. et al. (2014) Integrative and personalized QSAR analysis in cancer by Kernelized Bayesian matrix factorization. J. Chem. Inf. Model, 54, 2347–2359. - PubMed
-
- Ammad-Ud Din M. et al. (2016) Drug response prediction by inferring pathway-response associations with Kernelized Bayesian matrix factorization. Bioinformatics, 32, i455–i463. - PubMed
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
Miscellaneous
