

Learning a Talker or Learning an Accent: Acoustic Similarity Constrains Generalization of Foreign Accent Adaptation to New Talkers
- PMID: 28890602
- PMCID: PMC5589144
- DOI: 10.1016/j.jml.2017.07.005
Learning a Talker or Learning an Accent: Acoustic Similarity Constrains Generalization of Foreign Accent Adaptation to New Talkers
Abstract
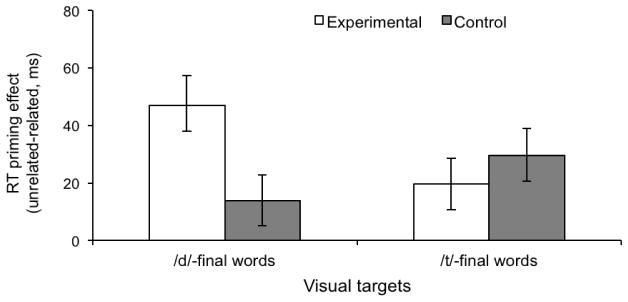
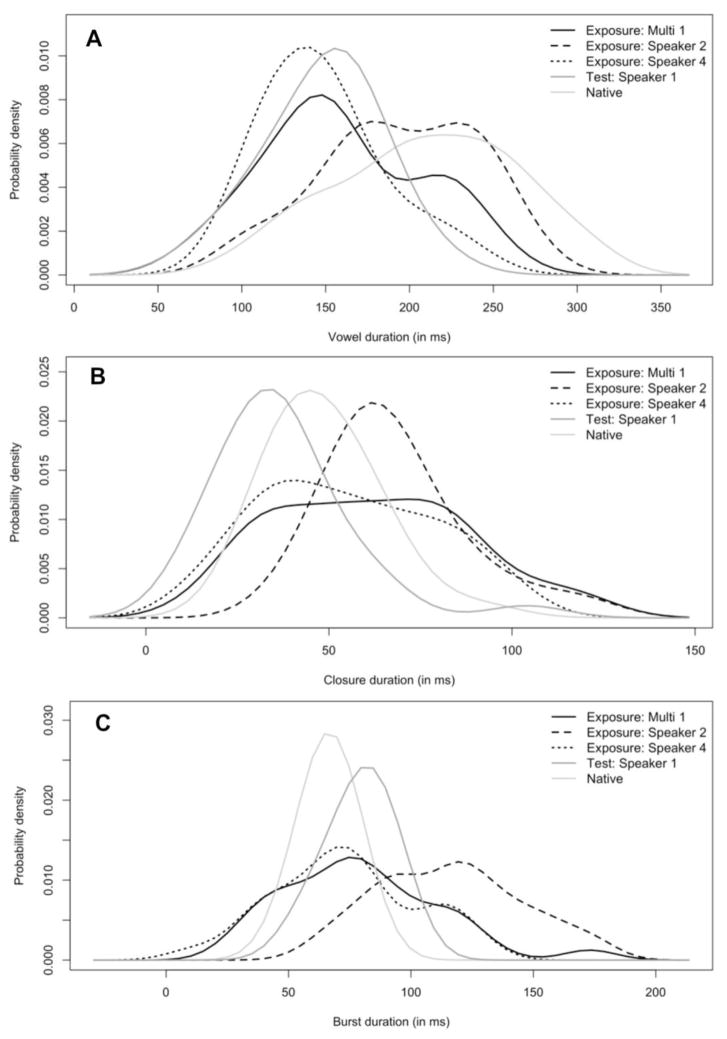
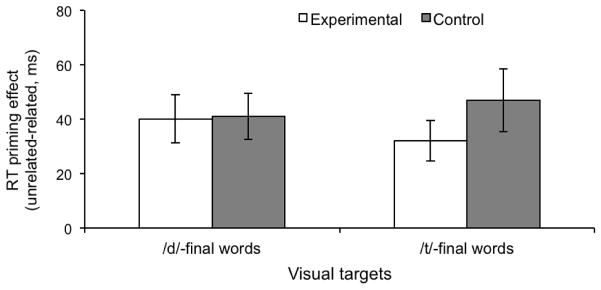
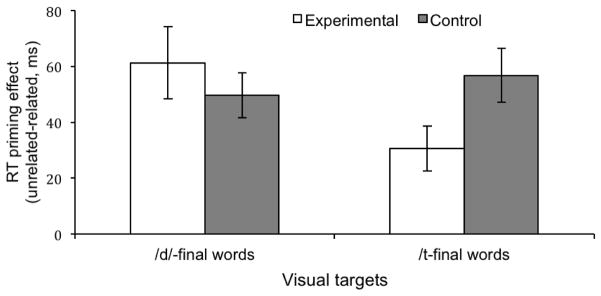
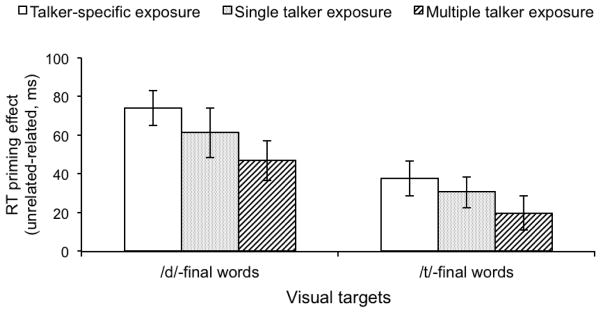
Past research has revealed that native listeners use top-down information to adjust the mapping from speech sounds to phonetic categories. Such phonetic adjustments help listeners adapt to foreign-accented speech. However, the mechanism by which talker-specific adaptation generalizes to other talkers is poorly understood. Here we asked what conditions induce crosstalker generalization in talker accent adaptation. Native-English listeners were exposed to Mandarin-accented words, produced by a single talker or multiple talkers. Following exposure, adaptation to the accent was tested by recognition of novel words in a task that assesses online lexical access. Crucially, test words were novel words and were produced by a novel Mandarin-accented talker. Results indicated that regardless of exposure condition (single or multiple talker exposure), generalization was greatest when the talkers were acoustically similar to one another, suggesting that listeners were not developing an accent-wide schema for Mandarin talkers, but rather attuning to the specific acoustic-phonetic properties of the talkers. Implications for general mechanisms of talker generalization in speech adaptation are discussed.
Keywords: adaptation; foreign-accented speech; generalization; perceptual learning; spoken word recognition; talker specificity.
Figures
References
-
- Allen JS, Miller JL, DeSteno D. Individual talker differences in voice-onset-time. Journal of the Acoustical Society of America. 2003;113:544–552. - PubMed
-
- Allen JS, Miller JL. Listener sensitivity to individual talker differences in voice-onset-time. Journal of the Acoustical Society of America. 2004;115:3171–3183. - PubMed
-
- Baayen RH, Davidson DJ, Bates DM. Mixed-effects modeling with crossed random effects for subjects and items. Journal of Memory and Language. 2008;59:390–412.
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous