

Comprehensive benchmarking and ensemble approaches for metagenomic classifiers
- PMID: 28934964
- PMCID: PMC5609029
- DOI: 10.1186/s13059-017-1299-7
Comprehensive benchmarking and ensemble approaches for metagenomic classifiers
Erratum in
-
Correction to: Comprehensive benchmarking and ensemble approaches for metagenomic classifiers.Genome Biol. 2019 Apr 5;20(1):72. doi: 10.1186/s13059-019-1687-2. Genome Biol. 2019. PMID: 30953547 Free PMC article.
Abstract
Background: One of the main challenges in metagenomics is the identification of microorganisms in clinical and environmental samples. While an extensive and heterogeneous set of computational tools is available to classify microorganisms using whole-genome shotgun sequencing data, comprehensive comparisons of these methods are limited.
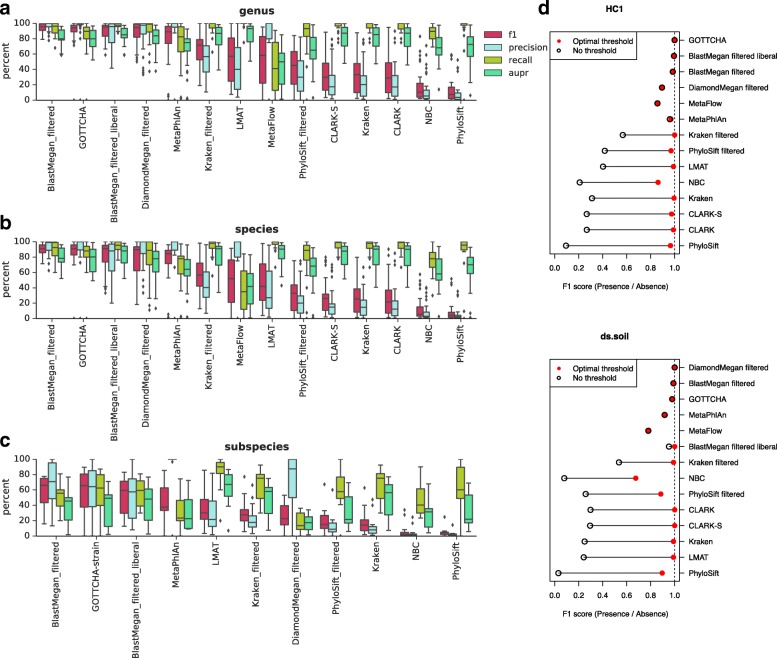
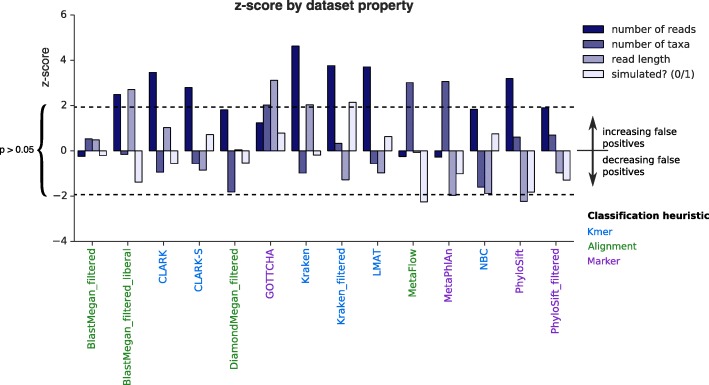
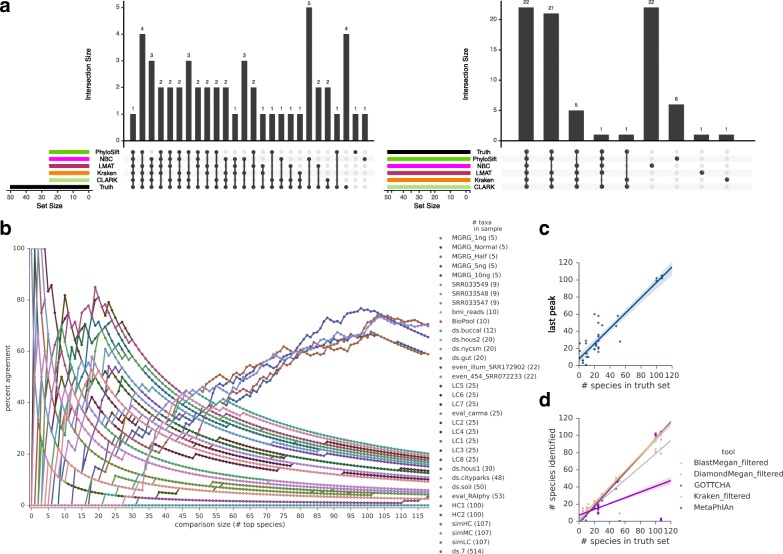
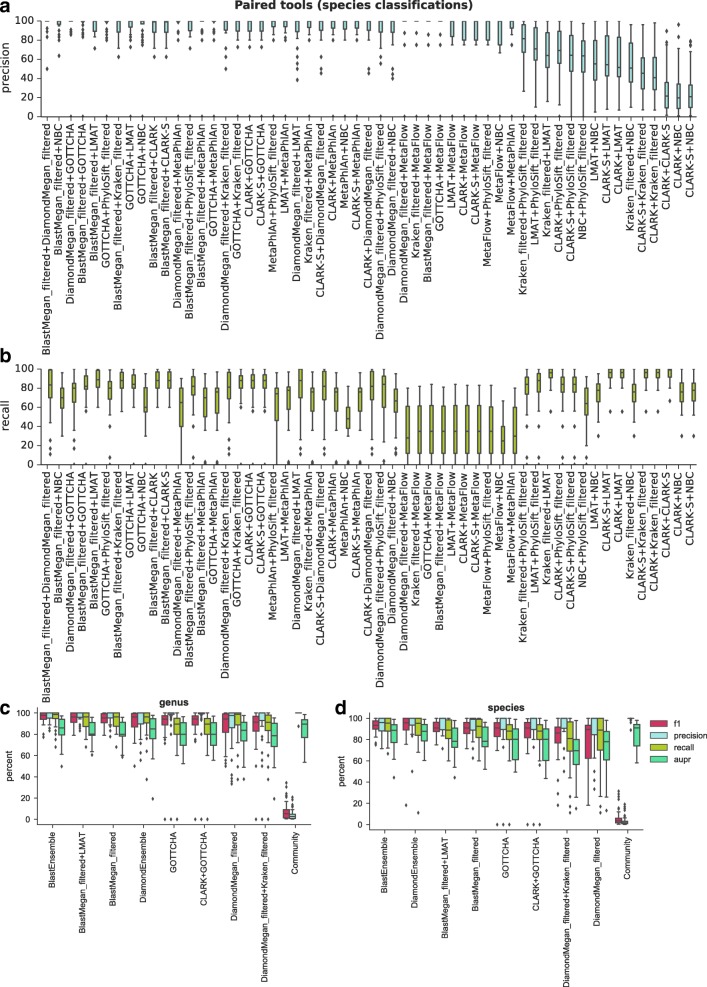
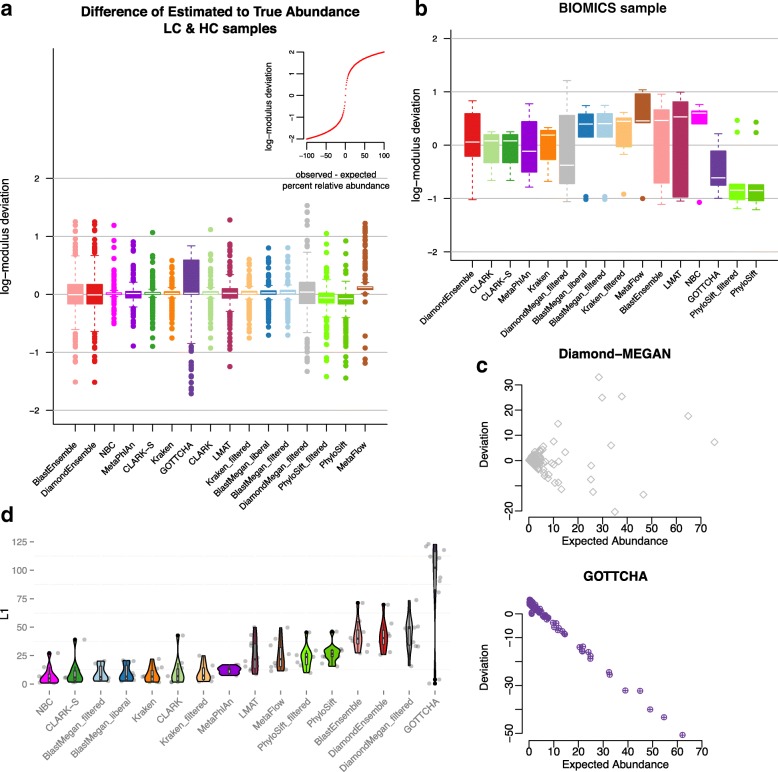
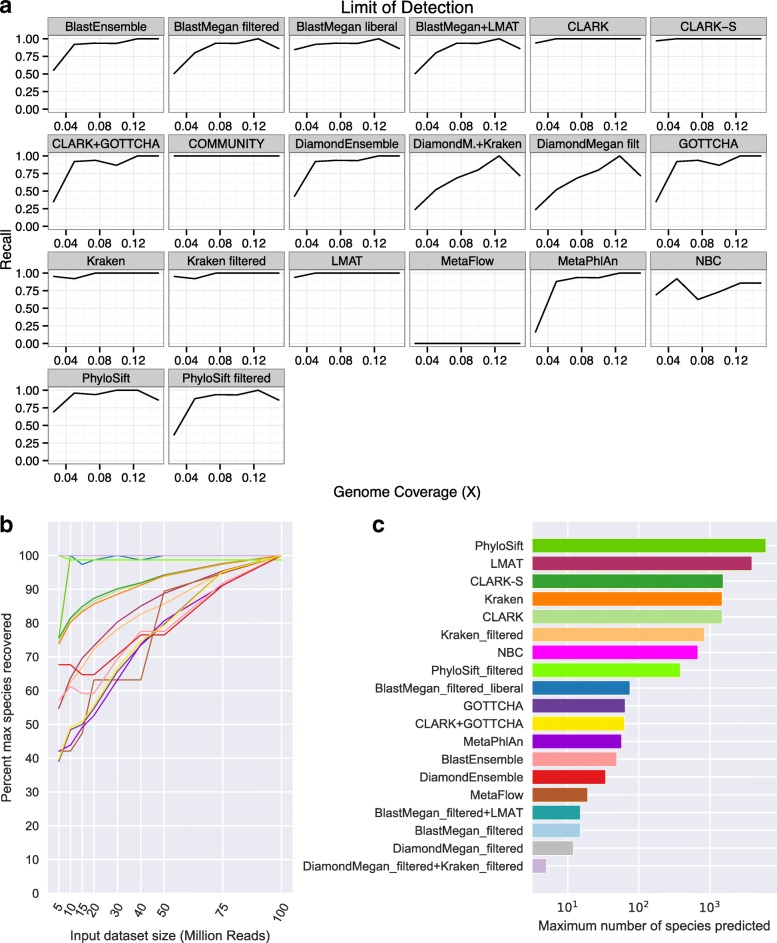
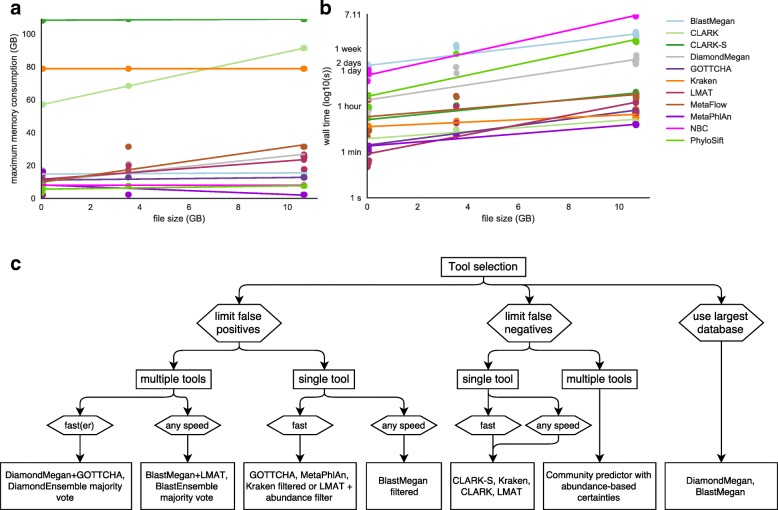
Results: In this study, we use the largest-to-date set of laboratory-generated and simulated controls across 846 species to evaluate the performance of 11 metagenomic classifiers. Tools were characterized on the basis of their ability to identify taxa at the genus, species, and strain levels, quantify relative abundances of taxa, and classify individual reads to the species level. Strikingly, the number of species identified by the 11 tools can differ by over three orders of magnitude on the same datasets. Various strategies can ameliorate taxonomic misclassification, including abundance filtering, ensemble approaches, and tool intersection. Nevertheless, these strategies were often insufficient to completely eliminate false positives from environmental samples, which are especially important where they concern medically relevant species. Overall, pairing tools with different classification strategies (k-mer, alignment, marker) can combine their respective advantages.
Conclusions: This study provides positive and negative controls, titrated standards, and a guide for selecting tools for metagenomic analyses by comparing ranges of precision, accuracy, and recall. We show that proper experimental design and analysis parameters can reduce false positives, provide greater resolution of species in complex metagenomic samples, and improve the interpretation of results.
Keywords: Classification; Comparison; Ensemble methods; Meta-classification; Metagenomics; Pathogen detection; Shotgun sequencing; Taxonomy.
Conflict of interest statement
Consent for publication
All NA12878 human data are consented for publication.
Competing interests
Some authors (listed above) are members of commercial operations in metagenomics, including IBM, CosmosID, Biotia, and One Codex.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Figures
References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
