

Estimation and evaluation of linear individualized treatment rules to guarantee performance
- PMID: 28960239
- PMCID: PMC5874184
- DOI: 10.1111/biom.12773
Estimation and evaluation of linear individualized treatment rules to guarantee performance
Abstract
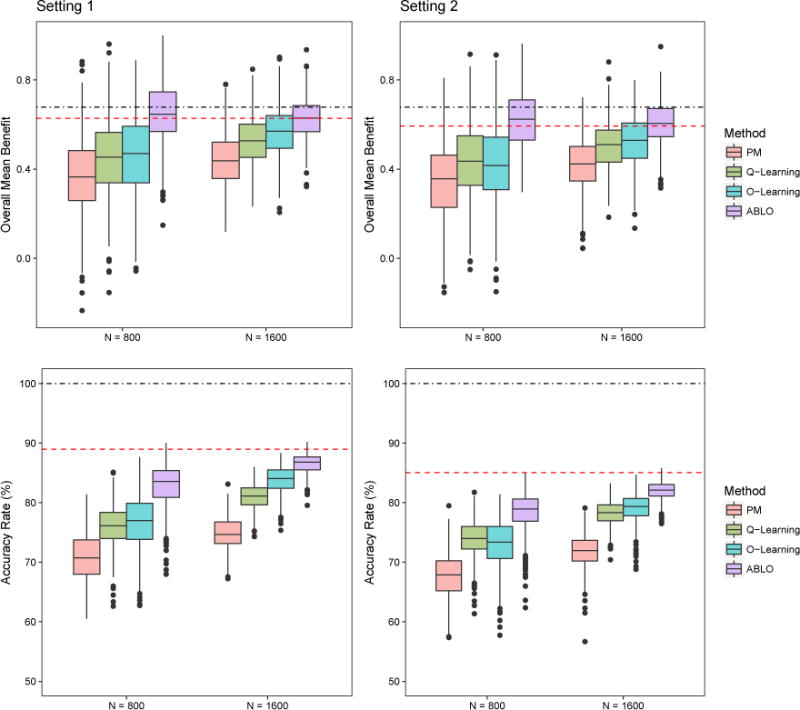
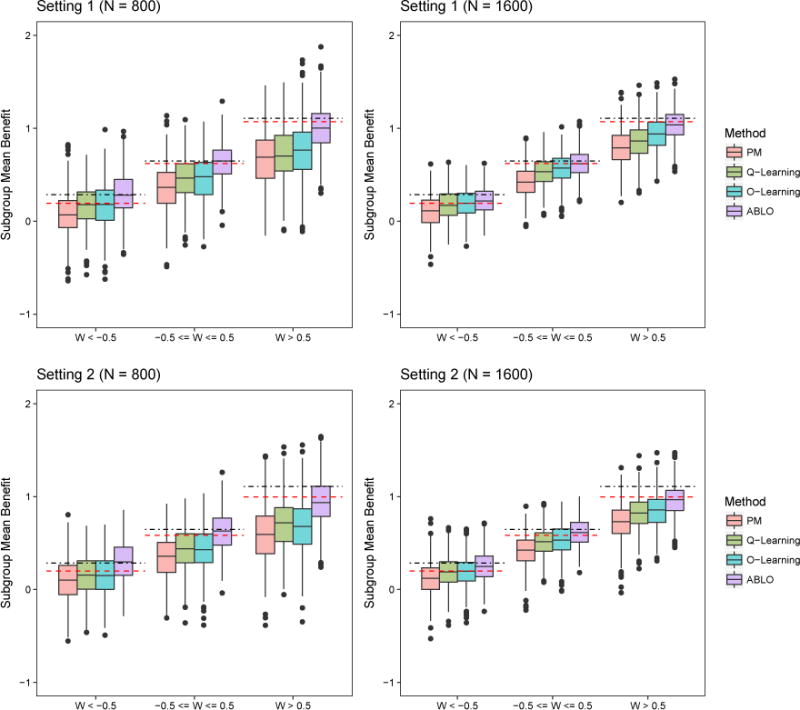
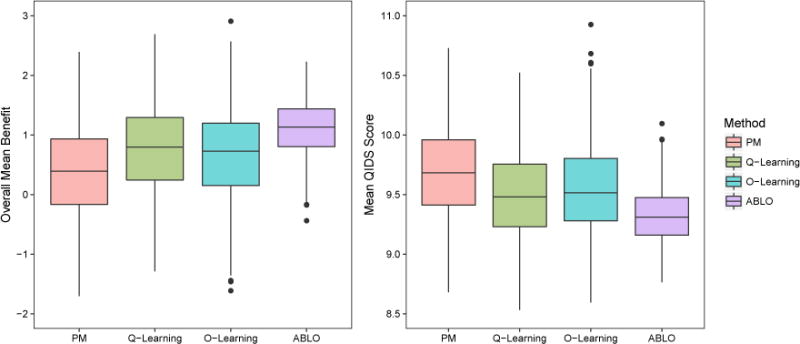
In clinical practice, an informative and practically useful treatment rule should be simple and transparent. However, because simple rules are likely to be far from optimal, effective methods to construct such rules must guarantee performance, in terms of yielding the best clinical outcome (highest reward) among the class of simple rules under consideration. Furthermore, it is important to evaluate the benefit of the derived rules on the whole sample and in pre-specified subgroups (e.g., vulnerable patients). To achieve both goals, we propose a robust machine learning method to estimate a linear treatment rule that is guaranteed to achieve optimal reward among the class of all linear rules. We then develop a diagnostic measure and inference procedure to evaluate the benefit of the obtained rule and compare it with the rules estimated by other methods. We provide theoretical justification for the proposed method and its inference procedure, and we demonstrate via simulations its superior performance when compared to existing methods. Lastly, we apply the method to the Sequenced Treatment Alternatives to Relieve Depression (STAR*D) trial on major depressive disorder and show that the estimated optimal linear rule provides a large benefit for mildly depressed and severely depressed patients but manifests a lack-of-fit for moderately depressed patients.
Keywords: Dynamic treatment regime; Machine learning; Qualitative interaction; Robust loss function; Treatment response heterogeneity.
© 2017, The International Biometric Society.
Figures
References
-
- An LTH, Tao PD, Muu LD. Numerical solution for optimization over the efficient set by D.C. optimization algorithms. Operations Research Letters. 1996;19:117–128.
-
- Blatt D, Murphy S, Zhu J. A-learning for approximate planning. The Methodology Center, Pennsylvania State University, State College; 2004. (Technical Report 04-63).
-
- Carini C, Menon SM, Chang M. Clinical and Statistical Considerations in Personalized Medicine. CRC Press; 2014.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
