

Label-free detection of cellular drug responses by high-throughput bright-field imaging and machine learning
- PMID: 28963483
- PMCID: PMC5622112
- DOI: 10.1038/s41598-017-12378-4
Label-free detection of cellular drug responses by high-throughput bright-field imaging and machine learning
Abstract
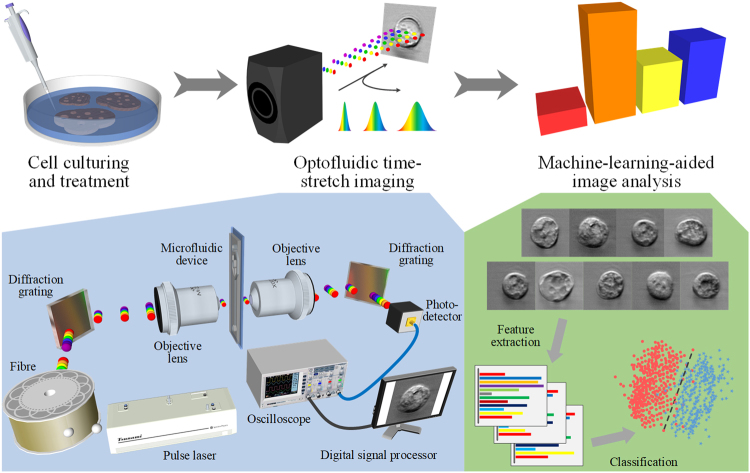
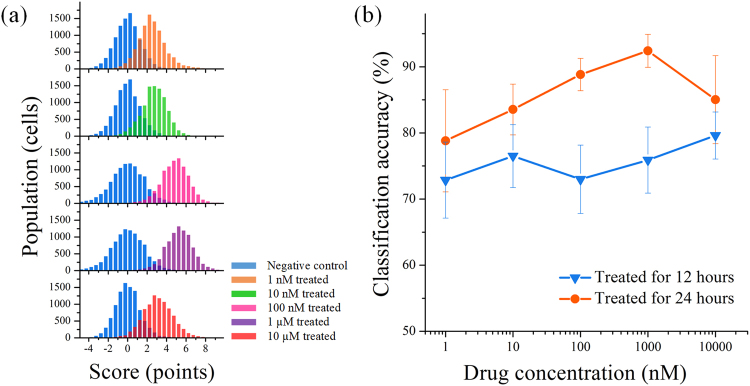
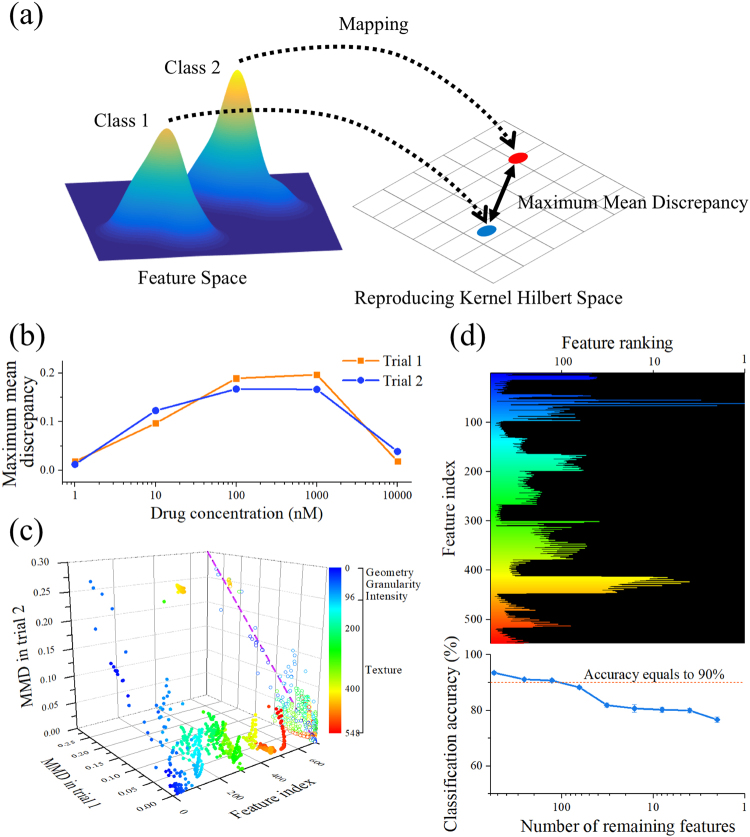
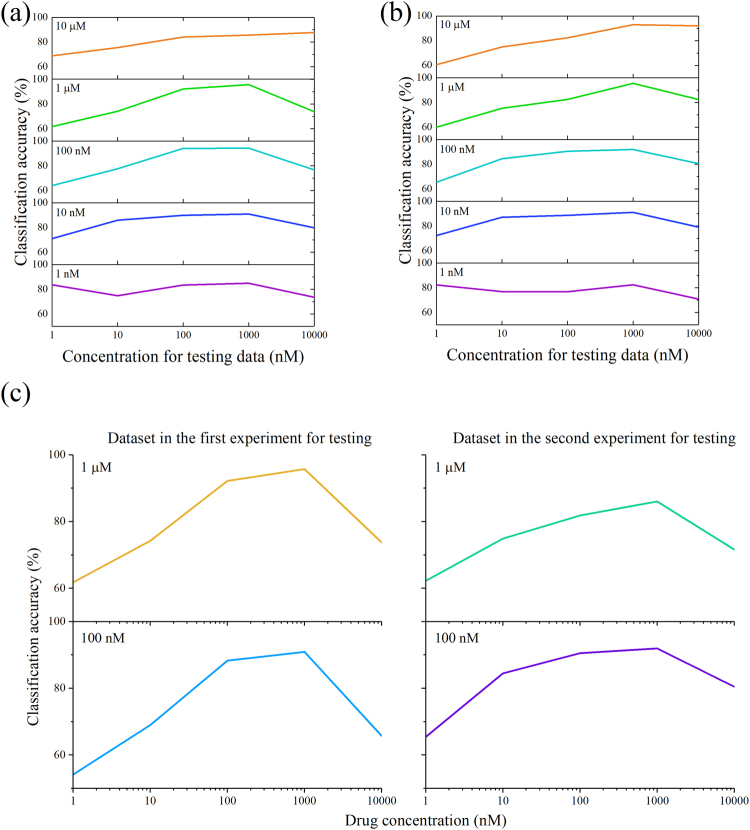
In the last decade, high-content screening based on multivariate single-cell imaging has been proven effective in drug discovery to evaluate drug-induced phenotypic variations. Unfortunately, this method inherently requires fluorescent labeling which has several drawbacks. Here we present a label-free method for evaluating cellular drug responses only by high-throughput bright-field imaging with the aid of machine learning algorithms. Specifically, we performed high-throughput bright-field imaging of numerous drug-treated and -untreated cells (N = ~240,000) by optofluidic time-stretch microscopy with high throughput up to 10,000 cells/s and applied machine learning to the cell images to identify their morphological variations which are too subtle for human eyes to detect. Consequently, we achieved a high accuracy of 92% in distinguishing drug-treated and -untreated cells without the need for labeling. Furthermore, we also demonstrated that dose-dependent, drug-induced morphological change from different experiments can be inferred from the classification accuracy of a single classification model. Our work lays the groundwork for label-free drug screening in pharmaceutical science and industry.
Conflict of interest statement
The authors declare that they have no competing interests.
Figures

References
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
