

See You See Me: the Role of Eye Contact in Multimodal Human-Robot Interaction
- PMID: 28966875
- PMCID: PMC5618804
- DOI: 10.1145/2882970
See You See Me: the Role of Eye Contact in Multimodal Human-Robot Interaction
Abstract
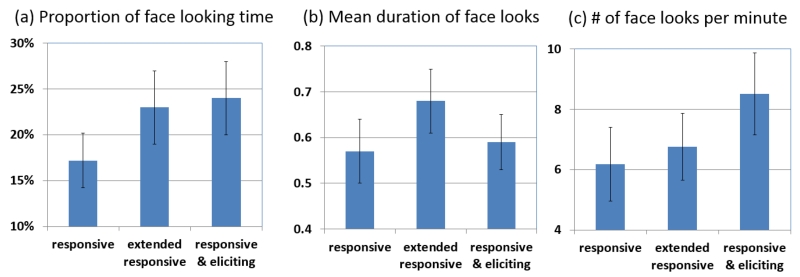
We focus on a fundamental looking behavior in human-robot interactions - gazing at each other's face. Eye contact and mutual gaze between two social partners are critical in smooth human-human interactions. Therefore, investigating at what moments and in what ways a robot should look at a human user's face as a response to the human's gaze behavior is an important topic. Toward this goal, we developed a gaze-contingent human-robot interaction system, which relied on momentary gaze behaviors from a human user to control an interacting robot in real time. Using this system, we conducted an experiment in which human participants interacted with the robot in a joint attention task. In the experiment, we systematically manipulated the robot's gaze toward the human partner's face in real time and then analyzed the human's gaze behavior as a response to the robot's gaze behavior. We found that more face looks from the robot led to more look-backs (to the robot's face) from human participants and consequently created more mutual gaze and eye contact between the two. Moreover, participants demonstrated more coordinated and synchronized multimodal behaviors between speech and gaze when more eye contact was successfully established and maintained.
Keywords: Gaze-Based Interaction; Human-Robot Interaction; Multimodal Interface.
Figures









References
-
- ADMONI HENNY, DATSIKAS CHRISTOPHER, SCASSELLATI BRIAN. Speech and Gaze Conflicts in Collaborative Human-Robot Interactions; Proceedings of the 36th Annual Conference of the Cognitive Science Society (CogSci 2014); 2014.
-
- ADMONI HENNY, HAYES BRADLEY, FEIL-SEIFER DAVID, ULLMAN DANIEL, SCASSELLATI BRIAN. Are you looking at me?: perception of robot attention is mediated by gaze type and group size; Proceedings of the 8th ACM/IEEE international conference on Human-robot interaction; IEEE Press. 2013.pp. 389–396.
-
- ANDRIST SEAN, TAN XIANGZHI,, GLEICHER MICHAEL, MUTLU BILGE. Conversational gaze aversion for humanlike robots; Proceedings of the 2014 ACM/IEEE international conference on Human-robot interaction; ACM. 2014.pp. 25–32.
-
- ARGYLE M. Bodily communication. Methuen; New York, NY: 1988.
-
- ARGYLE MICHAEL, GRAHAM JEANANN. The central Europe experiment: Looking at persons and looking at objects. Journal of Nonverbal Behavior. 1976;1:6–16.
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources