

HUMA: A platform for the analysis of genetic variation in humans
- PMID: 28967693
- PMCID: PMC5722678
- DOI: 10.1002/humu.23334
HUMA: A platform for the analysis of genetic variation in humans
Abstract
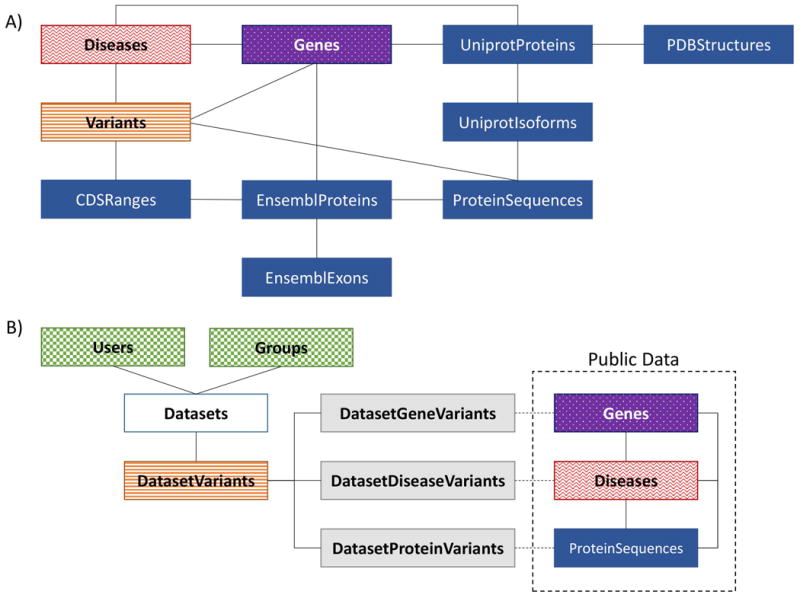
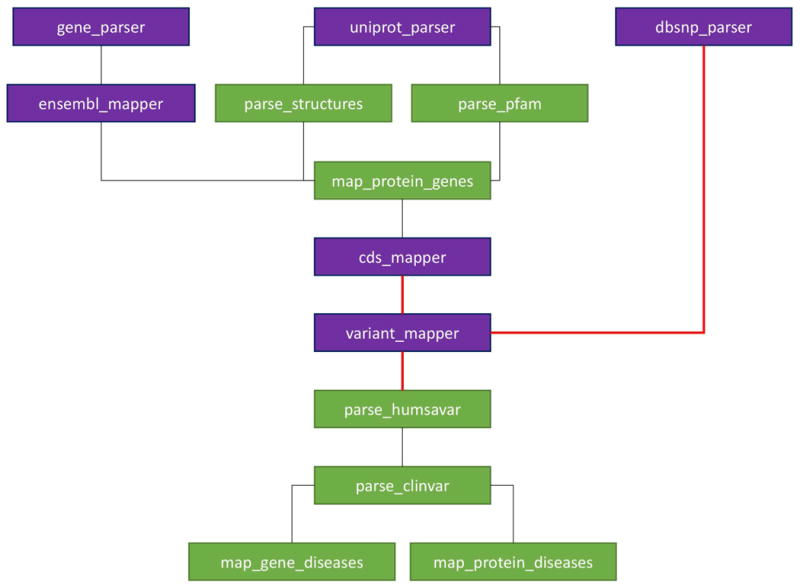
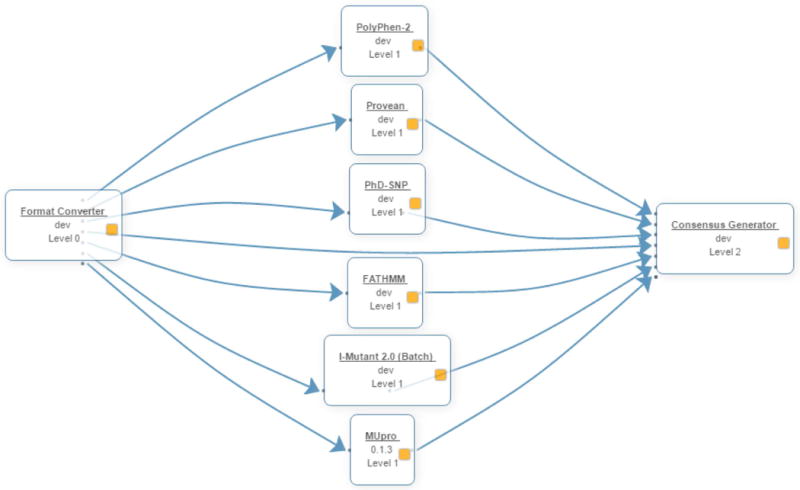
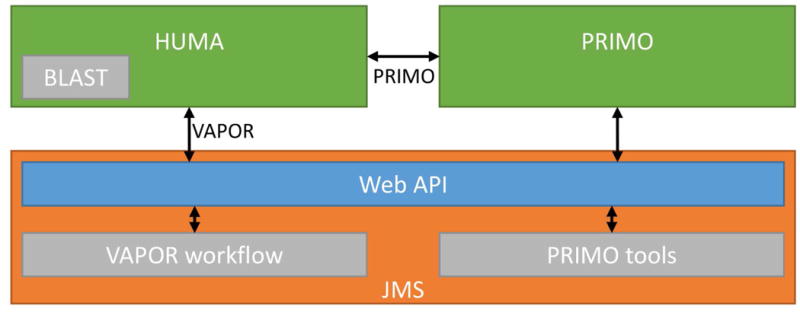
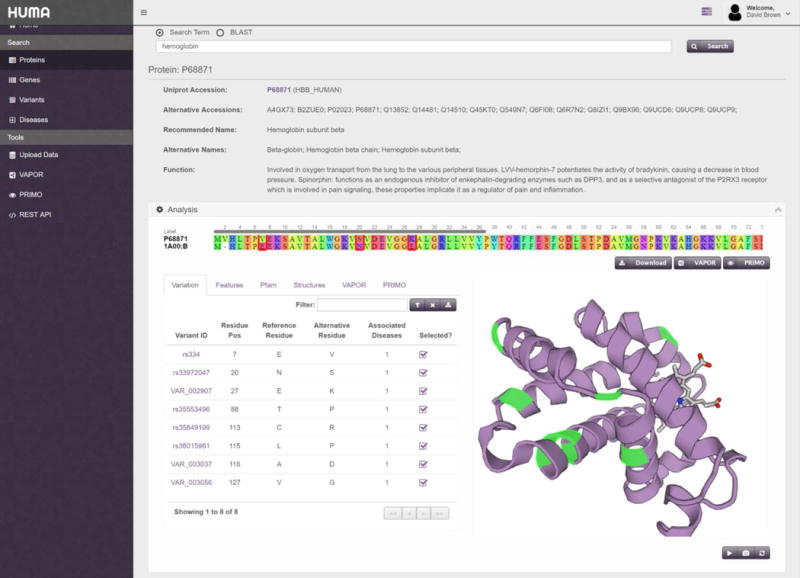
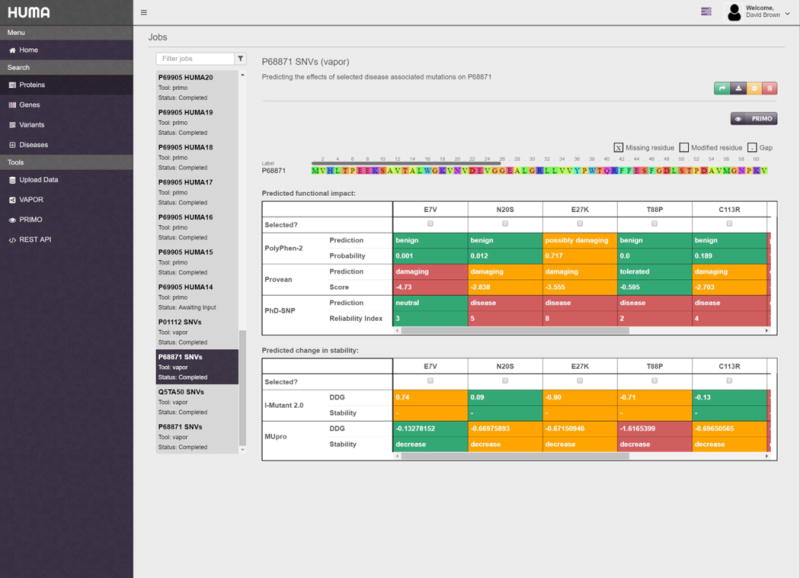
The completion of the human genome project at the beginning of the 21st century, along with the rapid advancement of sequencing technologies thereafter, has resulted in exponential growth of biological data. In genetics, this has given rise to numerous variation databases, created to store and annotate the ever-expanding dataset of known mutations. Usually, these databases focus on variation at the sequence level. Few databases focus on the analysis of variation at the 3D level, that is, mapping, visualizing, and determining the effects of variation in protein structures. Additionally, these Web servers seldom incorporate tools to help analyze these data. Here, we present the Human Mutation Analysis (HUMA) Web server and database. HUMA integrates sequence, structure, variation, and disease data into a single, connected database. A user-friendly interface provides click-based data access and visualization, whereas a RESTful Web API provides programmatic access to the data. Tools have been integrated into HUMA to allow initial analyses to be carried out on the server. Furthermore, users can upload their private variation datasets, which are automatically mapped to public data and can be analyzed using the integrated tools. HUMA is freely accessible at https://huma.rubi.ru.ac.za.
Keywords: HUMA; SNP; downstream variant analysis; protein variants; structural bioinformatics; variation database.
© 2017 Wiley Periodicals, Inc.
Figures
References
-
- Béroud C, Letovsky SI, Braastad CD, Caputo SM, Beaudoux O, Bignon YJ, Bressac-De Paillerets B, Bronner M, Buell CM, Collod-Béroud G, Coulet F, Derive N, et al. BRCA Share: A Collection of Clinical BRCA Gene Variants. Hum Mutat. 2016;37:1318–1328. - PubMed
-
- Bouaoun L, Sonkin D, Ardin M, Hollstein M, Byrnes G, Zavadil J, Olivier M. TP53 Variations in Human Cancers: New Lessons from the IARC TP53 Database and Genomics Data. Hum Mutat. 2016;37:865–876. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
