

Predicting novel substrates for enzymes with minimal experimental effort with active learning
- PMID: 29030274
- PMCID: PMC7055960
- DOI: 10.1016/j.ymben.2017.09.016
Predicting novel substrates for enzymes with minimal experimental effort with active learning
Abstract
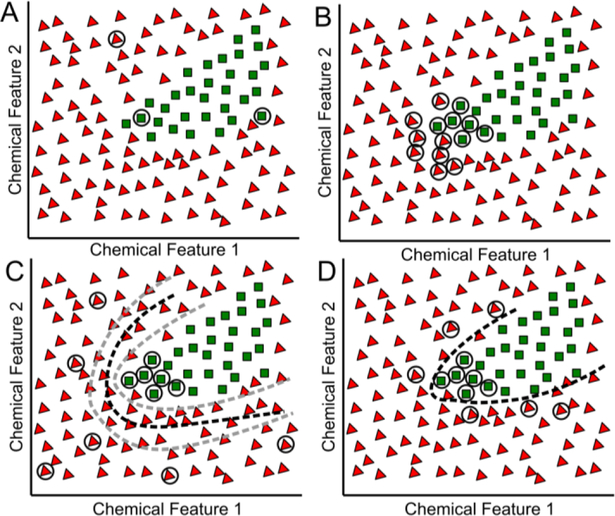
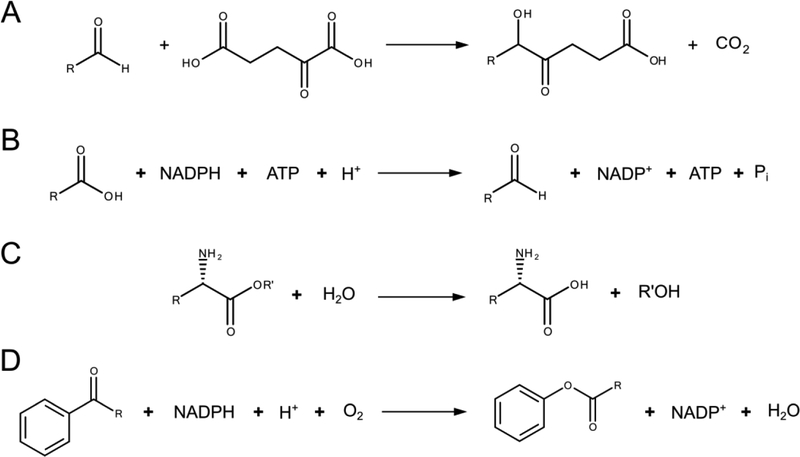
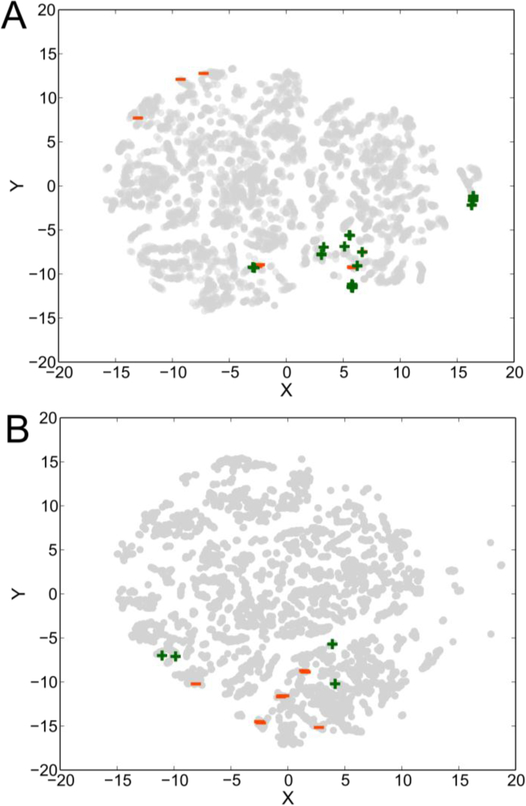
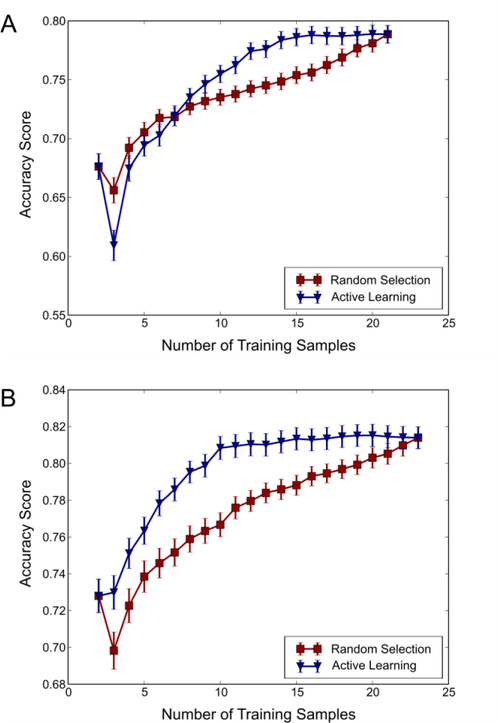
Enzymatic substrate promiscuity is more ubiquitous than previously thought, with significant consequences for understanding metabolism and its application to biocatalysis. This realization has given rise to the need for efficient characterization of enzyme promiscuity. Enzyme promiscuity is currently characterized with a limited number of human-selected compounds that may not be representative of the enzyme's versatility. While testing large numbers of compounds may be impractical, computational approaches can exploit existing data to determine the most informative substrates to test next, thereby more thoroughly exploring an enzyme's versatility. To demonstrate this, we used existing studies and tested compounds for four different enzymes, developed support vector machine (SVM) models using these datasets, and selected additional compounds for experiments using an active learning approach. SVMs trained on a chemically diverse set of compounds were discovered to achieve maximum accuracies of ~80% using ~33% fewer compounds than datasets based on all compounds tested in existing studies. Active learning-selected compounds for testing resolved apparent conflicts in the existing training data, while adding diversity to the dataset. The application of these algorithms to wide arrays of metabolic enzymes would result in a library of SVMs that can predict high-probability promiscuous enzymatic reactions and could prove a valuable resource for the design of novel metabolic pathways.
Keywords: Active learning; Enzyme promiscuity; Machine learning.
Copyright © 2017 International Metabolic Engineering Society. Published by Elsevier Inc. All rights reserved.
Conflict of interest statement
Conflict of Interest Statement
The authors declare that they have no conflict of interest.
Figures
References
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
