

SPRINT: an SNP-free toolkit for identifying RNA editing sites
- PMID: 29036410
- PMCID: PMC5870768
- DOI: 10.1093/bioinformatics/btx473
SPRINT: an SNP-free toolkit for identifying RNA editing sites
Abstract
Motivation: RNA editing generates post-transcriptional sequence alterations. Detection of RNA editing sites (RESs) typically requires the filtering of SNVs called from RNA-seq data using an SNP database, an obstacle that is difficult to overcome for most organisms.
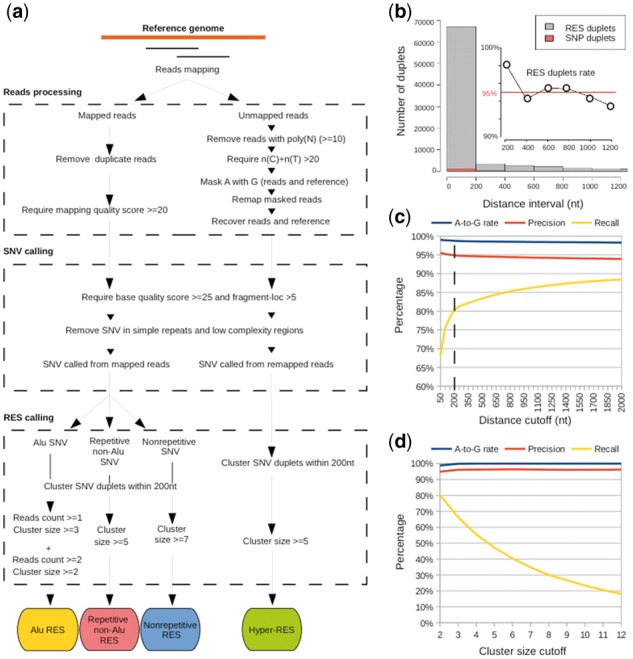
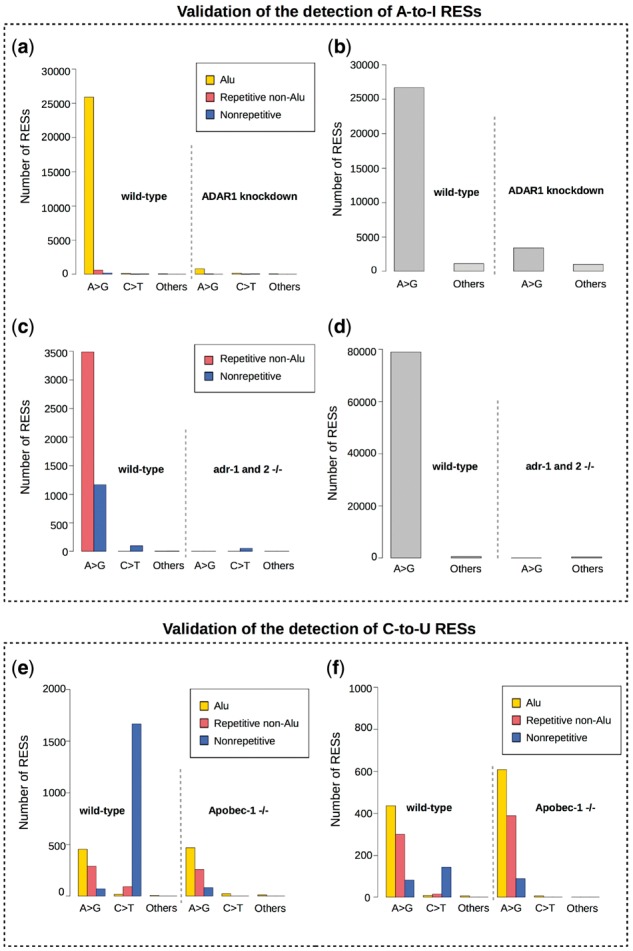
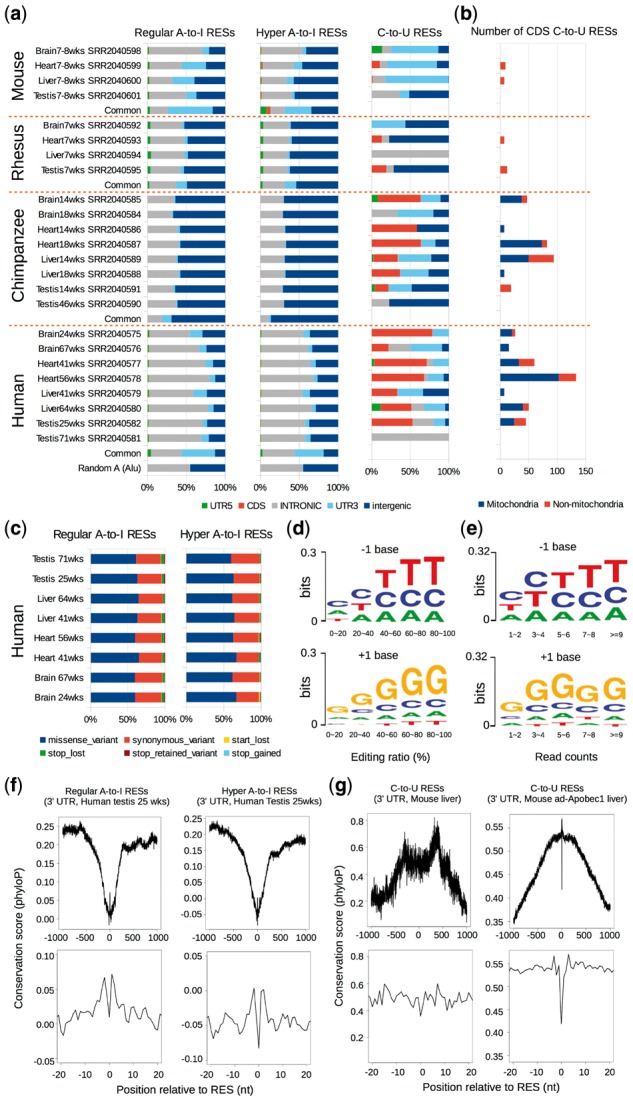
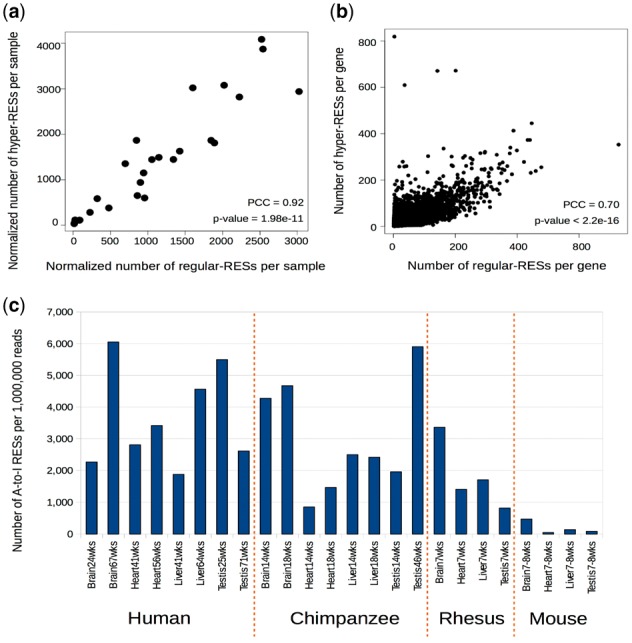
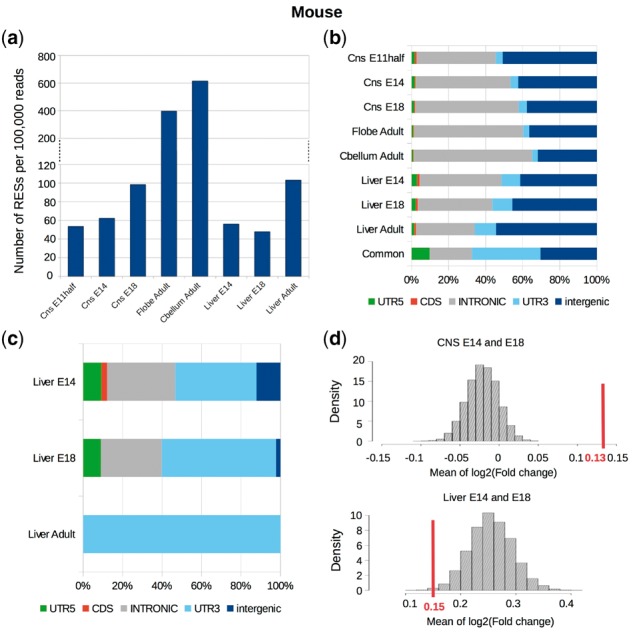
Results: Here, we present a novel method named SPRINT that identifies RESs without the need to filter out SNPs. SPRINT also integrates the detection of hyper RESs from remapped reads, and has been fully automated to any RNA-seq data with reference genome sequence available. We have rigorously validated SPRINT's effectiveness in detecting RESs using RNA-seq data of samples in which genes encoding RNA editing enzymes are knock down or over-expressed, and have also demonstrated its superiority over current methods. We have applied SPRINT to investigate RNA editing across tissues and species, and also in the development of mouse embryonic central nervous system. A web resource (http://sprint.tianlab.cn) of RESs identified by SPRINT has been constructed.
Availability and implementation: The software and related data are available at http://sprint.tianlab.cn.
Contact: weidong.tian@fudan.edu.cn.
Supplementary information: Supplementary data are available at Bioinformatics online.
© The Author 2017. Published by Oxford University Press.
Figures
References
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
