

Development of a Bayesian Estimator for Audio-Visual Integration: A Neurocomputational Study
- PMID: 29046631
- PMCID: PMC5633019
- DOI: 10.3389/fncom.2017.00089
Development of a Bayesian Estimator for Audio-Visual Integration: A Neurocomputational Study
Abstract
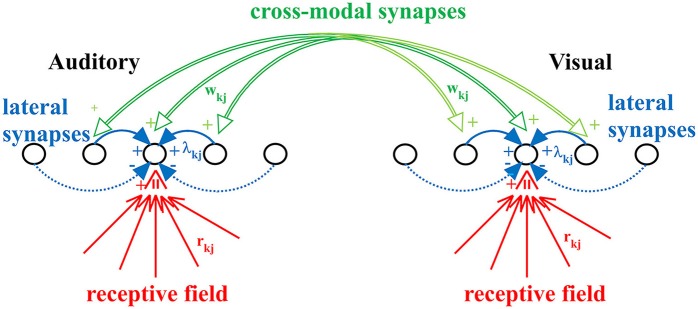
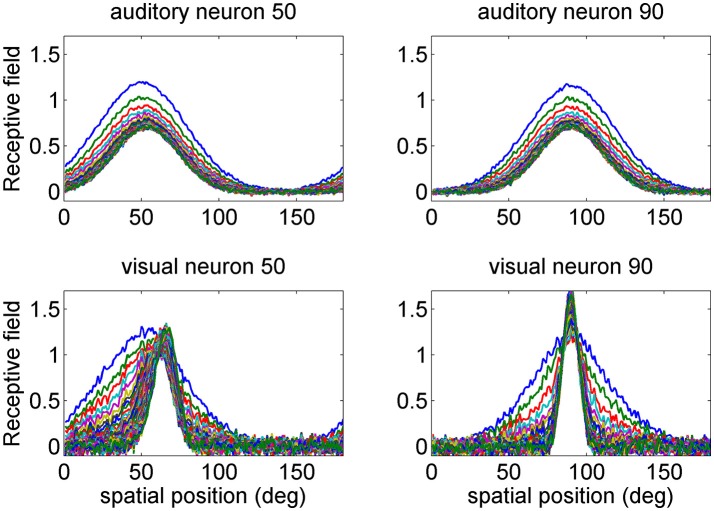
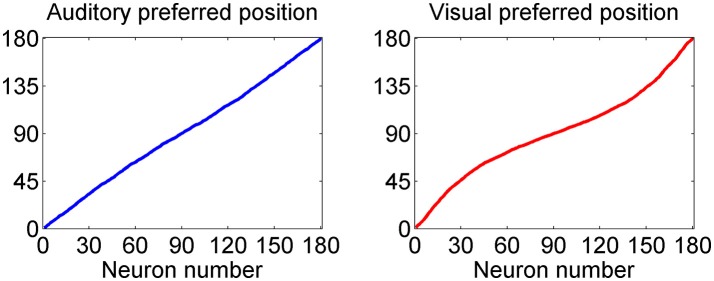
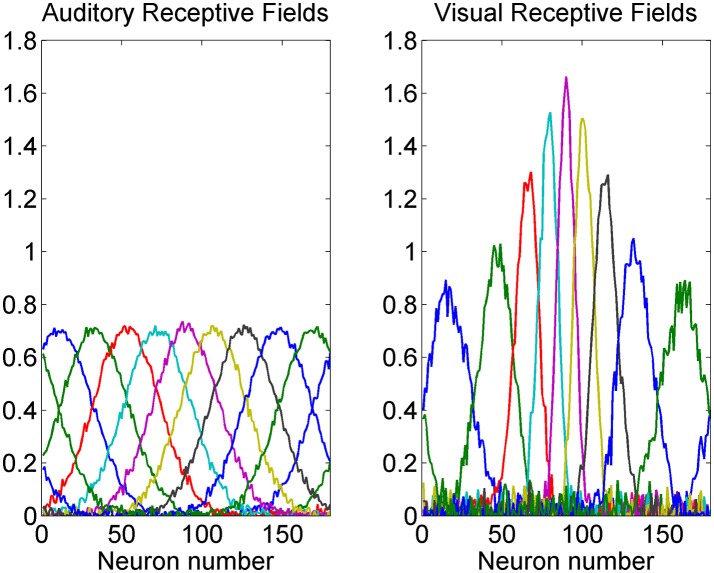
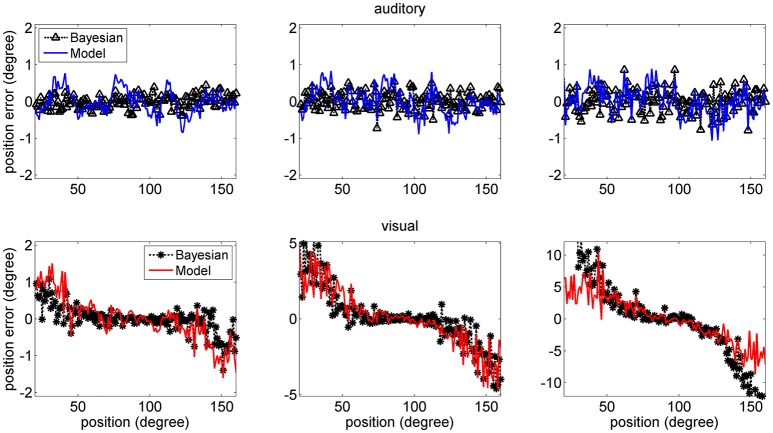
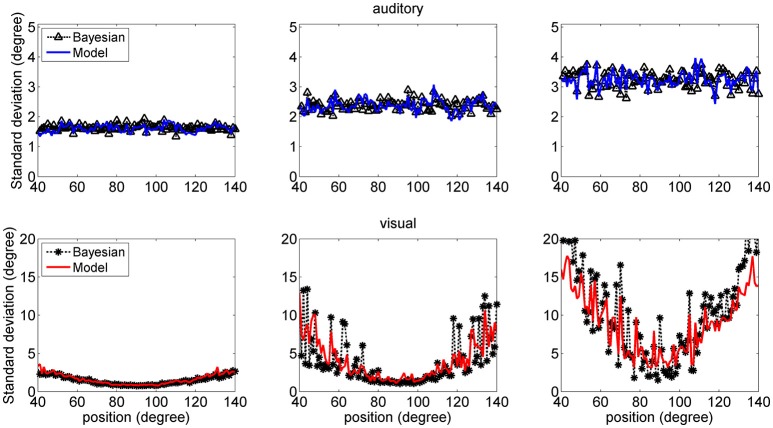
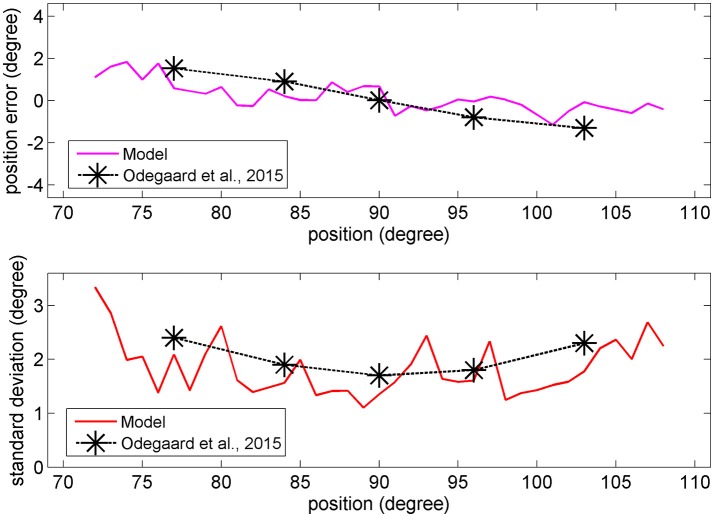
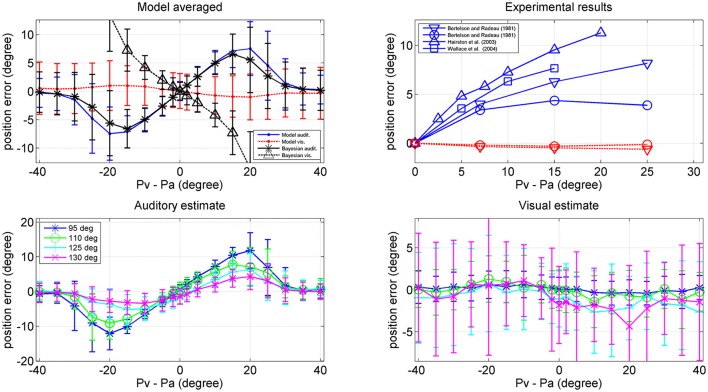
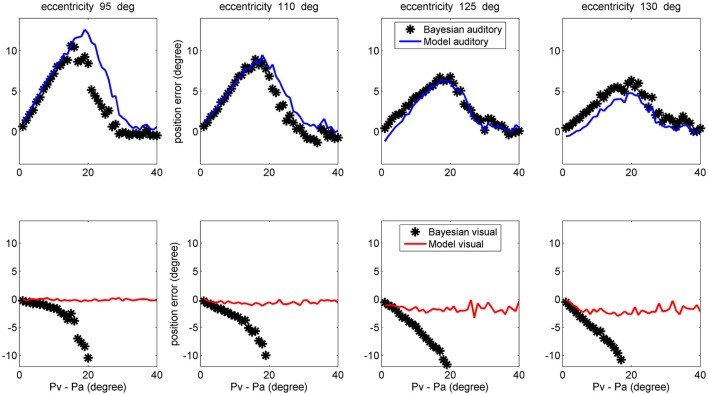
The brain integrates information from different sensory modalities to generate a coherent and accurate percept of external events. Several experimental studies suggest that this integration follows the principle of Bayesian estimate. However, the neural mechanisms responsible for this behavior, and its development in a multisensory environment, are still insufficiently understood. We recently presented a neural network model of audio-visual integration (Neural Computation, 2017) to investigate how a Bayesian estimator can spontaneously develop from the statistics of external stimuli. Model assumes the presence of two unimodal areas (auditory and visual) topologically organized. Neurons in each area receive an input from the external environment, computed as the inner product of the sensory-specific stimulus and the receptive field synapses, and a cross-modal input from neurons of the other modality. Based on sensory experience, synapses were trained via Hebbian potentiation and a decay term. Aim of this work is to improve the previous model, including a more realistic distribution of visual stimuli: visual stimuli have a higher spatial accuracy at the central azimuthal coordinate and a lower accuracy at the periphery. Moreover, their prior probability is higher at the center, and decreases toward the periphery. Simulations show that, after training, the receptive fields of visual and auditory neurons shrink to reproduce the accuracy of the input (both at the center and at the periphery in the visual case), thus realizing the likelihood estimate of unimodal spatial position. Moreover, the preferred positions of visual neurons contract toward the center, thus encoding the prior probability of the visual input. Finally, a prior probability of the co-occurrence of audio-visual stimuli is encoded in the cross-modal synapses. The model is able to simulate the main properties of a Bayesian estimator and to reproduce behavioral data in all conditions examined. In particular, in unisensory conditions the visual estimates exhibit a bias toward the fovea, which increases with the level of noise. In cross modal conditions, the SD of the estimates decreases when using congruent audio-visual stimuli, and a ventriloquism effect becomes evident in case of spatially disparate stimuli. Moreover, the ventriloquism decreases with the eccentricity.
Keywords: multisensory integration; neural networks; perception bias; prior probability; ventriloquism.
Figures


Similar articles
-
Multisensory Bayesian Inference Depends on Synapse Maturation during Training: Theoretical Analysis and Neural Modeling Implementation.Neural Comput. 2017 Mar;29(3):735-782. doi: 10.1162/NECO_a_00935. Epub 2017 Jan 17. Neural Comput. 2017. PMID: 28095201
-
Explaining the Effect of Likelihood Manipulation and Prior Through a Neural Network of the Audiovisual Perception of Space.Multisens Res. 2019 Jan 1;32(2):111-144. doi: 10.1163/22134808-20191324. Multisens Res. 2019. PMID: 31059469
-
A neural network model of ventriloquism effect and aftereffect.PLoS One. 2012;7(8):e42503. doi: 10.1371/journal.pone.0042503. Epub 2012 Aug 3. PLoS One. 2012. PMID: 22880007 Free PMC article.
-
Neurocomputational approaches to modelling multisensory integration in the brain: a review.Neural Netw. 2014 Dec;60:141-65. doi: 10.1016/j.neunet.2014.08.003. Epub 2014 Aug 23. Neural Netw. 2014. PMID: 25218929 Review.
-
[Ventriloquism and audio-visual integration of voice and face].Brain Nerve. 2012 Jul;64(7):771-7. Brain Nerve. 2012. PMID: 22764349 Review. Japanese.
Cited by
-
Scikit-NeuroMSI: A Generalized Framework for Modeling Multisensory Integration.Neuroinformatics. 2025 Jul 24;23(3):40. doi: 10.1007/s12021-025-09738-1. Neuroinformatics. 2025. PMID: 40705133 Free PMC article.
-
Is Competition the Default Configuration of Cross-Sensory Interactions?Eur J Neurosci. 2025 Aug;62(4):e70233. doi: 10.1111/ejn.70233. Eur J Neurosci. 2025. PMID: 40859467 Free PMC article.
-
Crossmodal associations modulate multisensory spatial integration.Atten Percept Psychophys. 2020 Oct;82(7):3490-3506. doi: 10.3758/s13414-020-02083-2. Atten Percept Psychophys. 2020. PMID: 32627131 Free PMC article.
-
Atypical development of causal inference in autism inferred through a neurocomputational model.Front Comput Neurosci. 2023 Oct 19;17:1258590. doi: 10.3389/fncom.2023.1258590. eCollection 2023. Front Comput Neurosci. 2023. PMID: 37927544 Free PMC article.
-
From Near-Optimal Bayesian Integration to Neuromorphic Hardware: A Neural Network Model of Multisensory Integration.Front Neurorobot. 2020 May 15;14:29. doi: 10.3389/fnbot.2020.00029. eCollection 2020. Front Neurorobot. 2020. PMID: 32499692 Free PMC article.
References
LinkOut - more resources
Full Text Sources
Other Literature Sources