

Enhancing Auditory Selective Attention Using a Visually Guided Hearing Aid
- PMID: 29049603
- PMCID: PMC5945072
- DOI: 10.1044/2017_JSLHR-H-17-0071
Enhancing Auditory Selective Attention Using a Visually Guided Hearing Aid
Abstract
Purpose: Listeners with hearing loss, as well as many listeners with clinically normal hearing, often experience great difficulty segregating talkers in a multiple-talker sound field and selectively attending to the desired "target" talker while ignoring the speech from unwanted "masker" talkers and other sources of sound. This listening situation forms the classic "cocktail party problem" described by Cherry (1953) that has received a great deal of study over the past few decades. In this article, a new approach to improving sound source segregation and enhancing auditory selective attention is described. The conceptual design, current implementation, and results obtained to date are reviewed and discussed in this article.
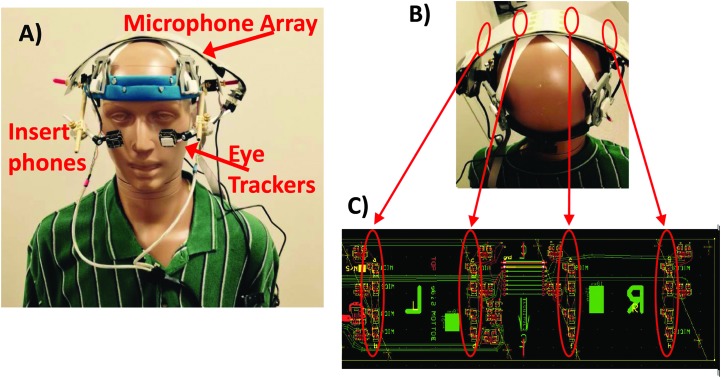
Method: This approach, embodied in a prototype "visually guided hearing aid" (VGHA) currently used for research, employs acoustic beamforming steered by eye gaze as a means for improving the ability of listeners to segregate and attend to one sound source in the presence of competing sound sources.
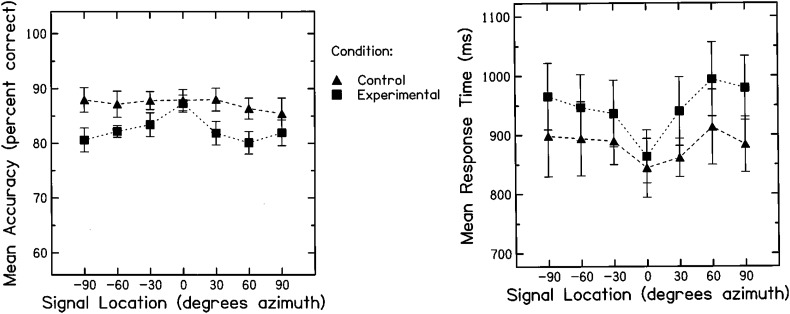
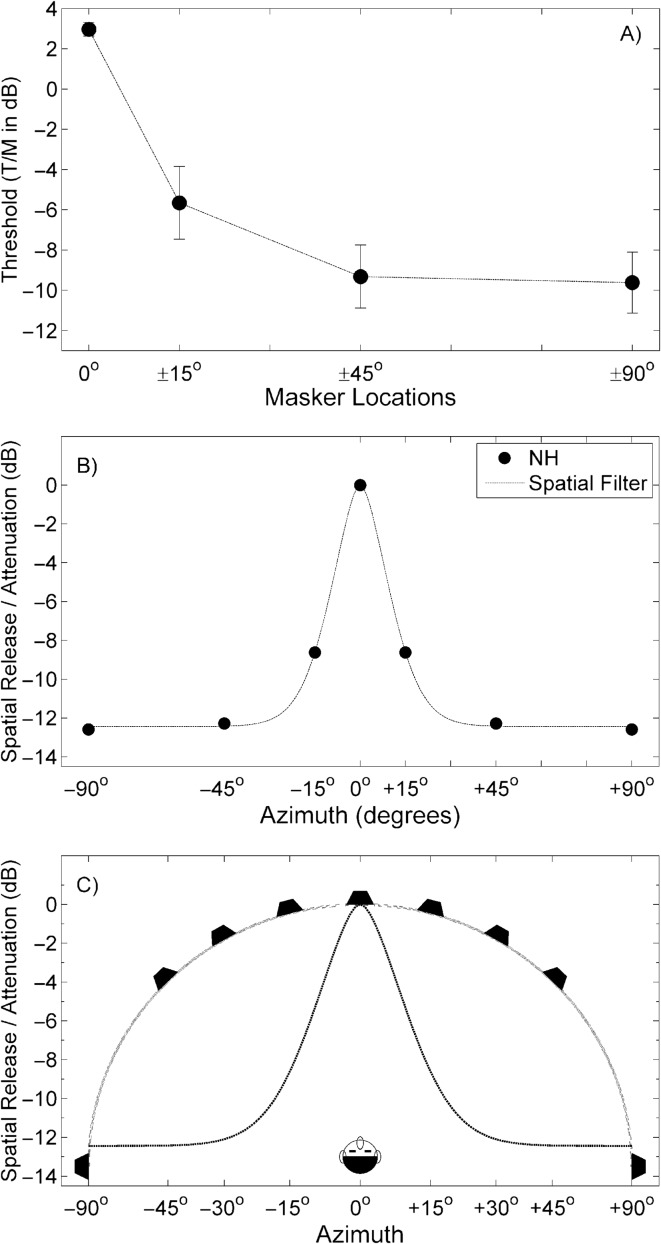
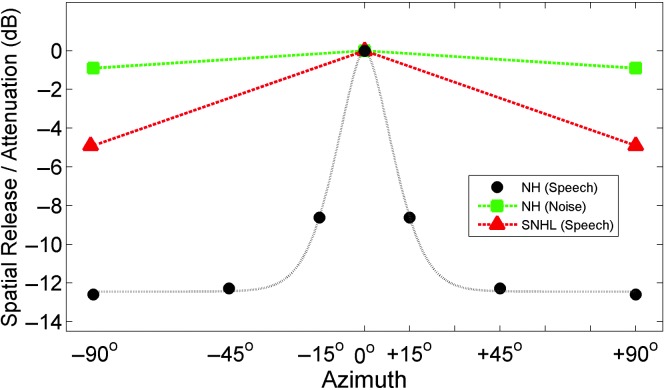
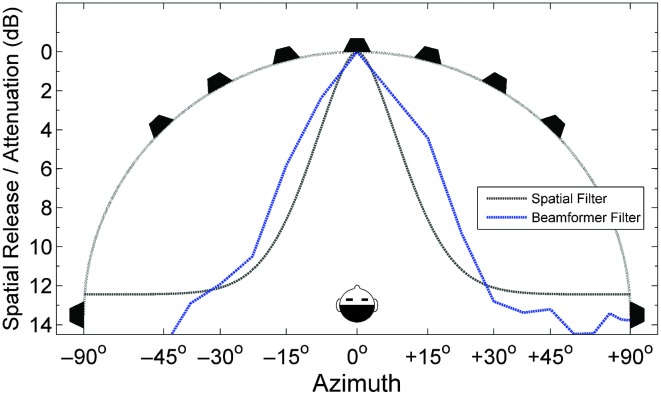
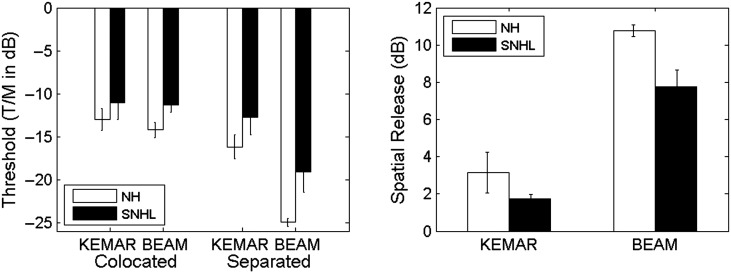
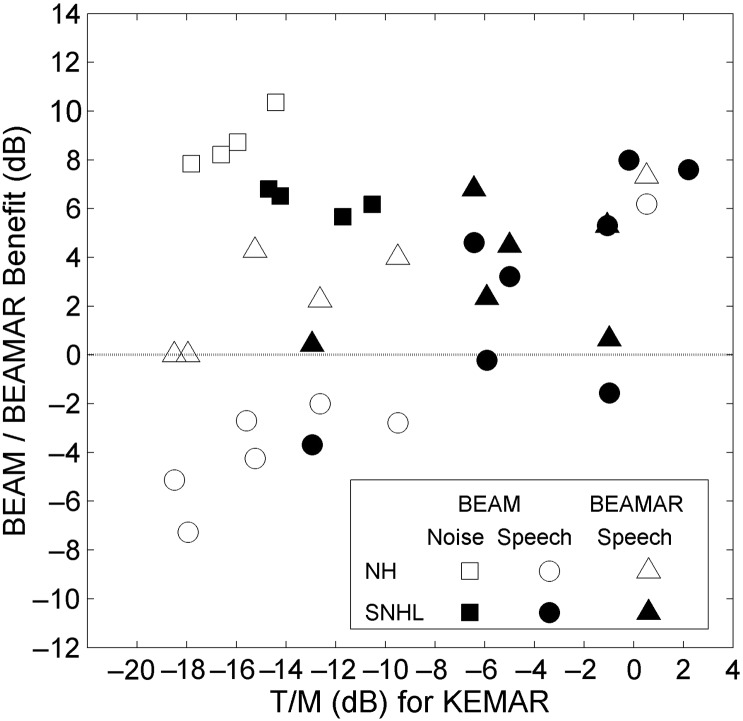
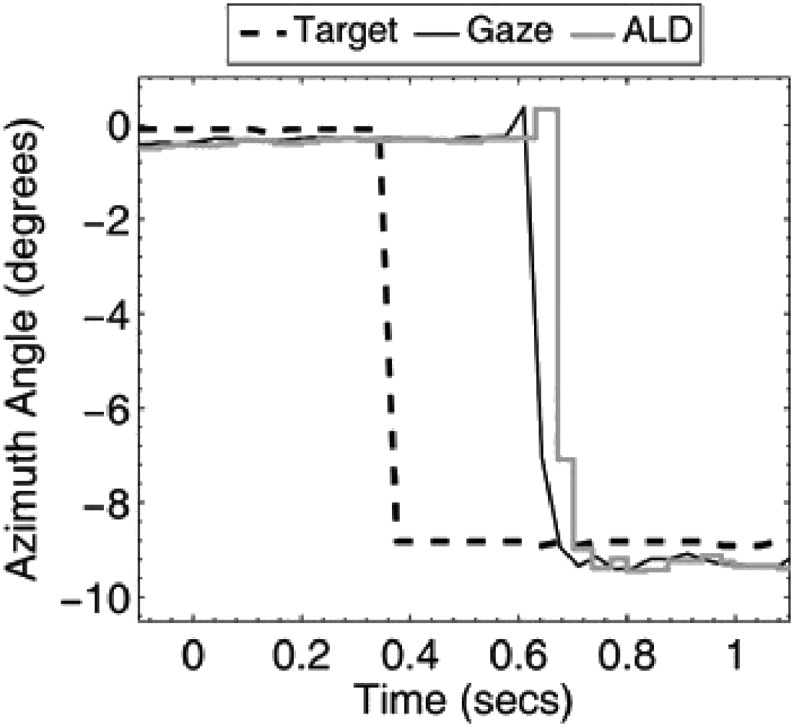
Results: The results from several studies demonstrate that listeners with normal hearing are able to use an attention-based "spatial filter" operating primarily on binaural cues to selectively attend to one source among competing spatially distributed sources. Furthermore, listeners with sensorineural hearing loss generally are less able to use this spatial filter as effectively as are listeners with normal hearing especially in conditions high in "informational masking." The VGHA enhances auditory spatial attention for speech-on-speech masking and improves signal-to-noise ratio for conditions high in "energetic masking." Visual steering of the beamformer supports the coordinated actions of vision and audition in selective attention and facilitates following sound source transitions in complex listening situations.
Conclusions: Both listeners with normal hearing and with sensorineural hearing loss may benefit from the acoustic beamforming implemented by the VGHA, especially for nearby sources in less reverberant sound fields. Moreover, guiding the beam using eye gaze can be an effective means of sound source enhancement for listening conditions where the target source changes frequently over time as often occurs during turn-taking in a conversation.
Presentation video: http://cred.pubs.asha.org/article.aspx?articleid=2601621.
Figures

References
-
- Agus T. L., Akeroyd M. A., Noble W., & Bhullar N. (2009). An analysis of the masking of speech by competing speech using self-report data (L). The Journal of the Acoustical Society of America, 125, 23–26. - PubMed
-
- Arbogast T. L., & Kidd G. Jr. (2000). Evidence for spatial tuning in informational masking using the probe-signal method. The Journal of the Acoustical Society of America, 108, 1803–1810. - PubMed
-
- Arbogast T. L., Mason C. R., & Kidd G. Jr. (2002). The effect of spatial separation on informational and energetic masking of speech. The Journal of the Acoustical Society of America, 112, 2086–2098. - PubMed
-
- Awh E., & Pashler H. (2000). Evidence for split attentional foci. The Journal of Experimental Psychology: Human Perception and Performance, 26, 834–846. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
Miscellaneous
