

Percolation transition of cooperative mutational effects in colorectal tumorigenesis
- PMID: 29097710
- PMCID: PMC5668266
- DOI: 10.1038/s41467-017-01171-6
Percolation transition of cooperative mutational effects in colorectal tumorigenesis
Abstract
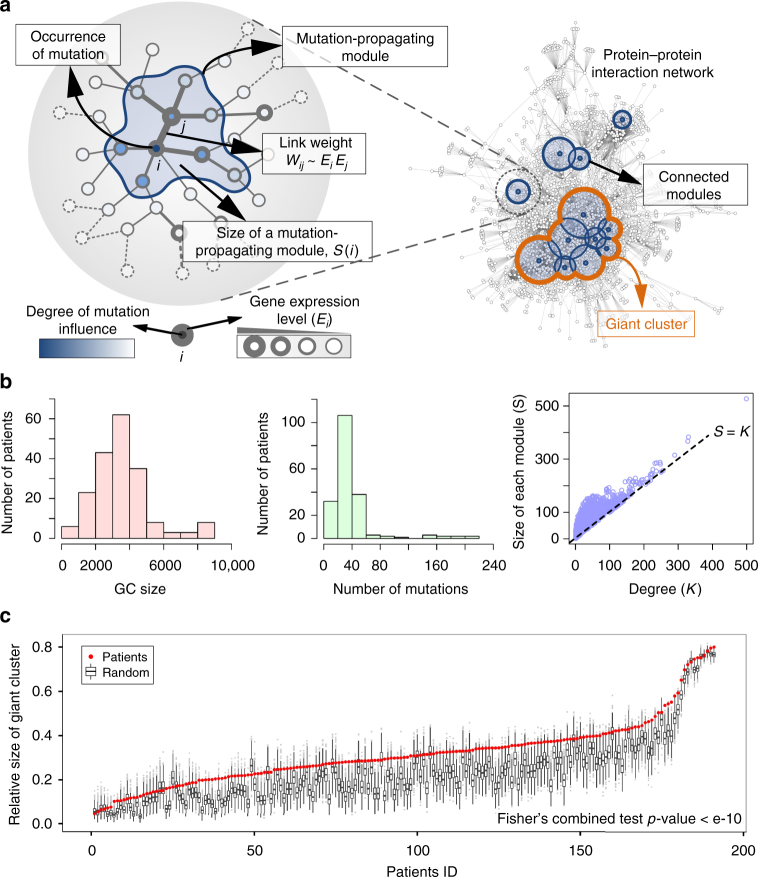
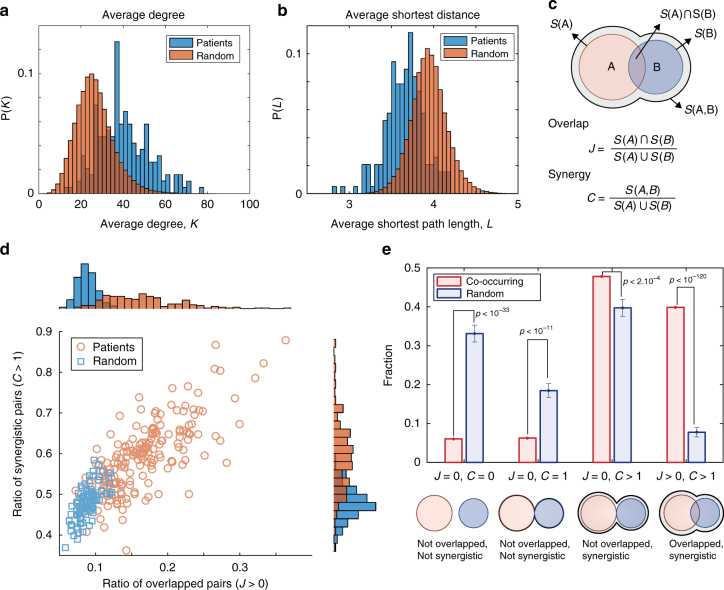
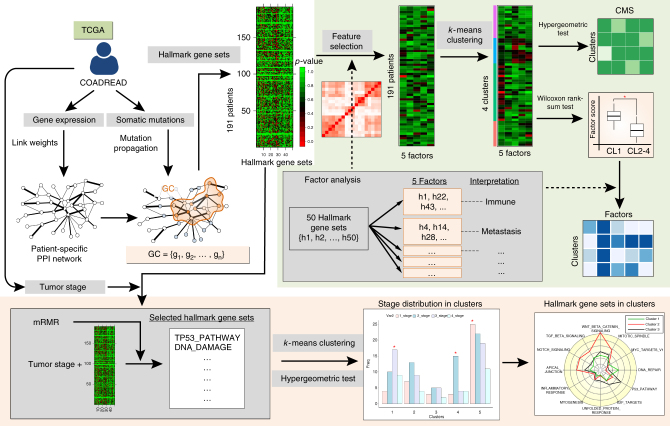
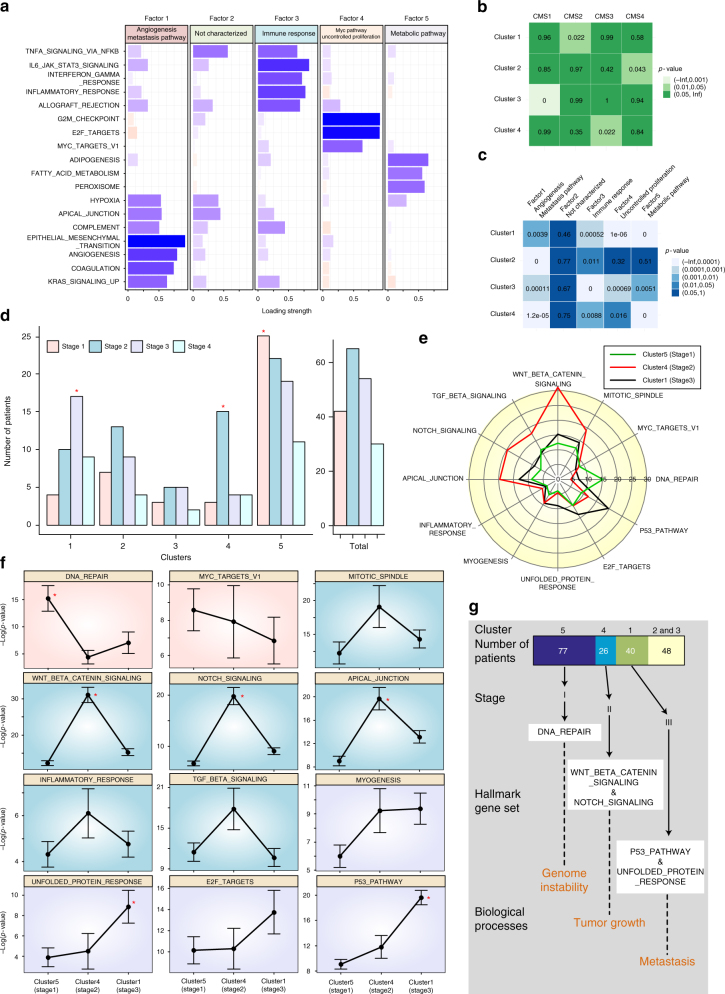
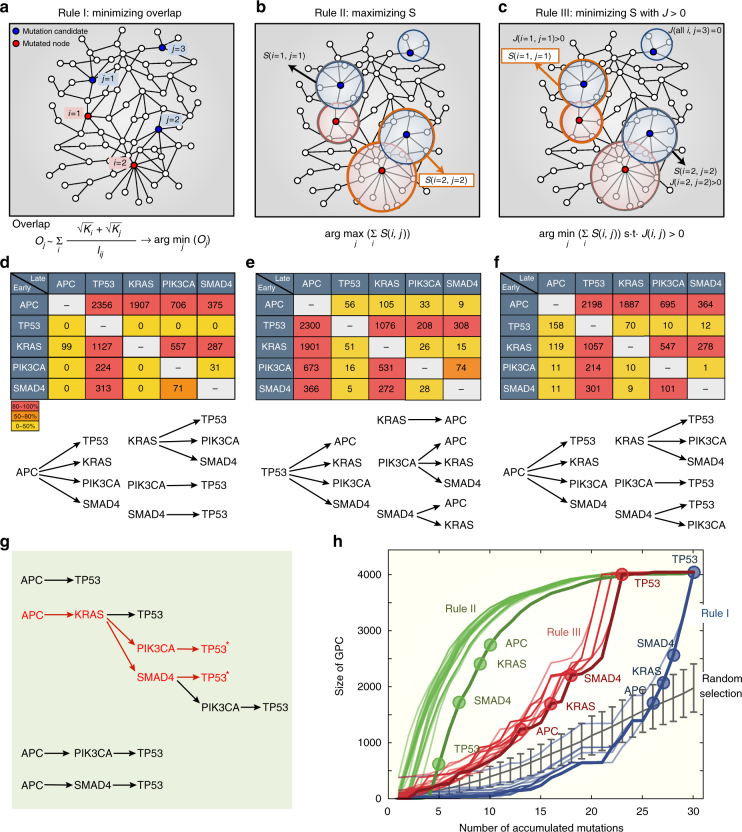
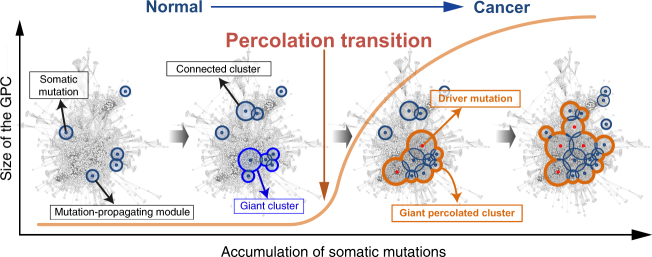
Cancer is caused by the accumulation of multiple genetic mutations, but their cooperative effects are poorly understood. Using a genome-wide analysis of all the somatic mutations in colorectal cancer patients in a large-scale molecular interaction network, here we find that a giant cluster of mutation-propagating modules in the network undergoes a percolation transition, a sudden critical transition from scattered small modules to a large connected cluster, during colorectal tumorigenesis. Such a large cluster ultimately results in a giant percolated cluster, which is accompanied by phenotypic changes corresponding to cancer hallmarks. Moreover, we find that the most commonly observed sequence of driver mutations in colorectal cancer has been optimized to maximize the giant percolated cluster. Our network-level percolation study shows that the cooperative effect rather than any single dominance of multiple somatic mutations is crucial in colorectal tumorigenesis.
Conflict of interest statement
The authors declare no competing financial interests.
Figures
References
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
