

Deep Recurrent Neural Networks for Human Activity Recognition
- PMID: 29113103
- PMCID: PMC5712979
- DOI: 10.3390/s17112556
Deep Recurrent Neural Networks for Human Activity Recognition
Abstract
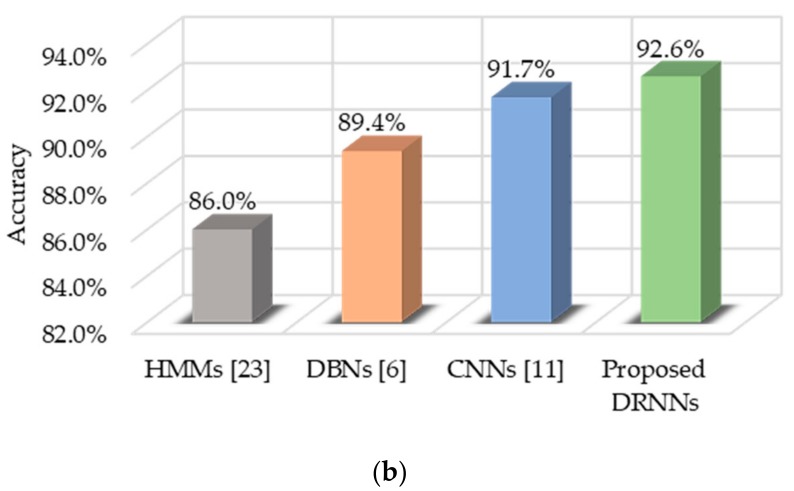
Adopting deep learning methods for human activity recognition has been effective in extracting discriminative features from raw input sequences acquired from body-worn sensors. Although human movements are encoded in a sequence of successive samples in time, typical machine learning methods perform recognition tasks without exploiting the temporal correlations between input data samples. Convolutional neural networks (CNNs) address this issue by using convolutions across a one-dimensional temporal sequence to capture dependencies among input data. However, the size of convolutional kernels restricts the captured range of dependencies between data samples. As a result, typical models are unadaptable to a wide range of activity-recognition configurations and require fixed-length input windows. In this paper, we propose the use of deep recurrent neural networks (DRNNs) for building recognition models that are capable of capturing long-range dependencies in variable-length input sequences. We present unidirectional, bidirectional, and cascaded architectures based on long short-term memory (LSTM) DRNNs and evaluate their effectiveness on miscellaneous benchmark datasets. Experimental results show that our proposed models outperform methods employing conventional machine learning, such as support vector machine (SVM) and k-nearest neighbors (KNN). Additionally, the proposed models yield better performance than other deep learning techniques, such as deep believe networks (DBNs) and CNNs.
Keywords: deep learning; human activity recognition; recurrent neural networks.
Conflict of interest statement
The authors declare no conflict of interest.
Figures
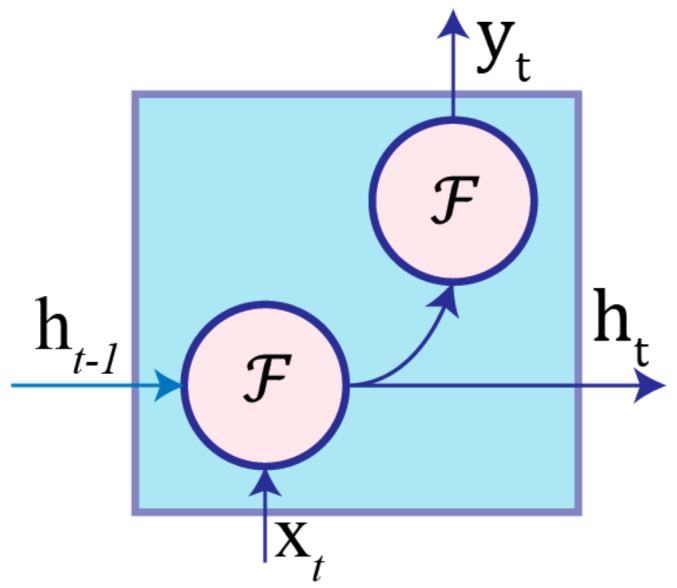
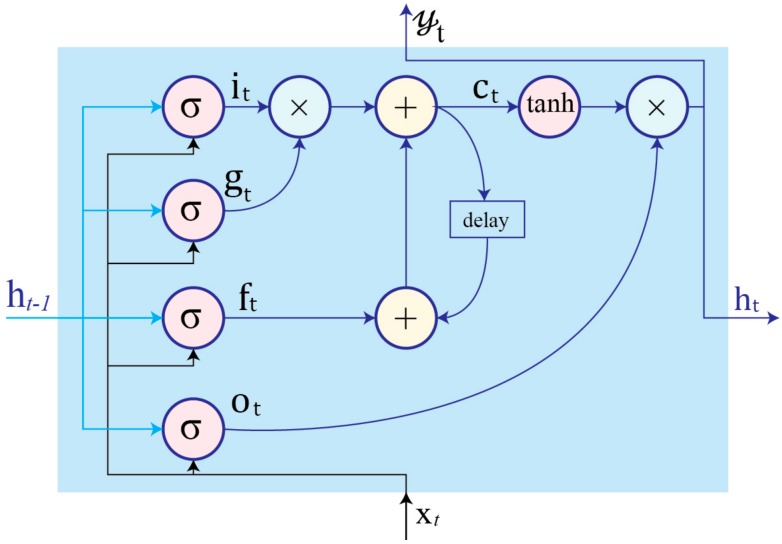
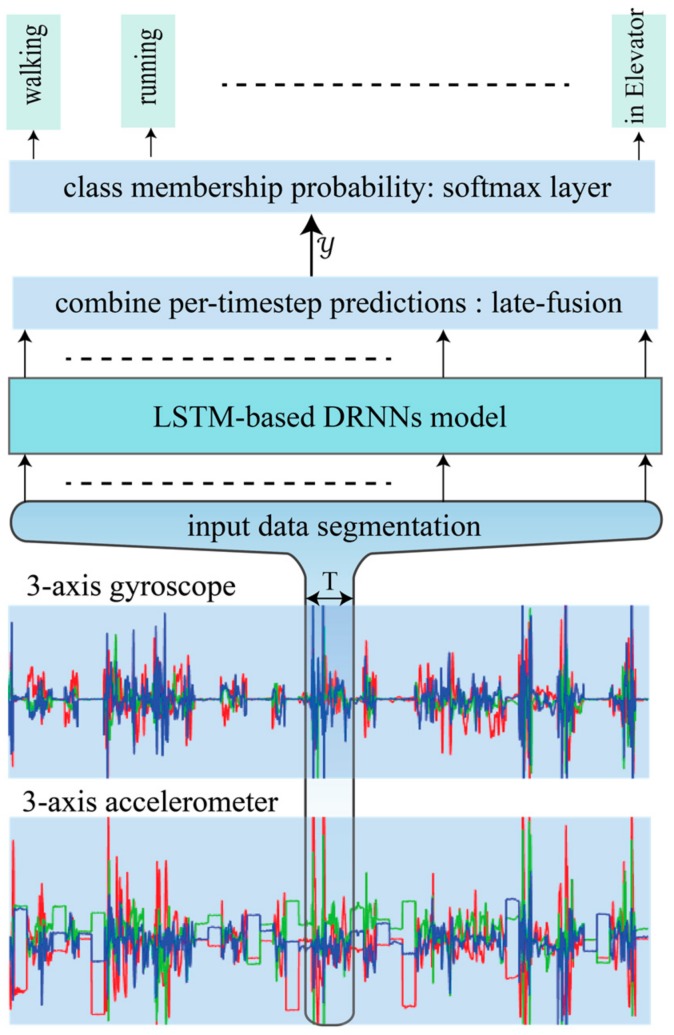
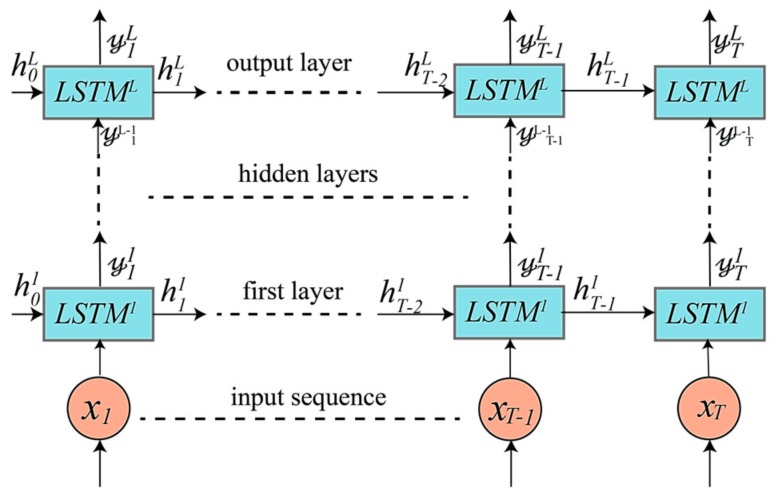
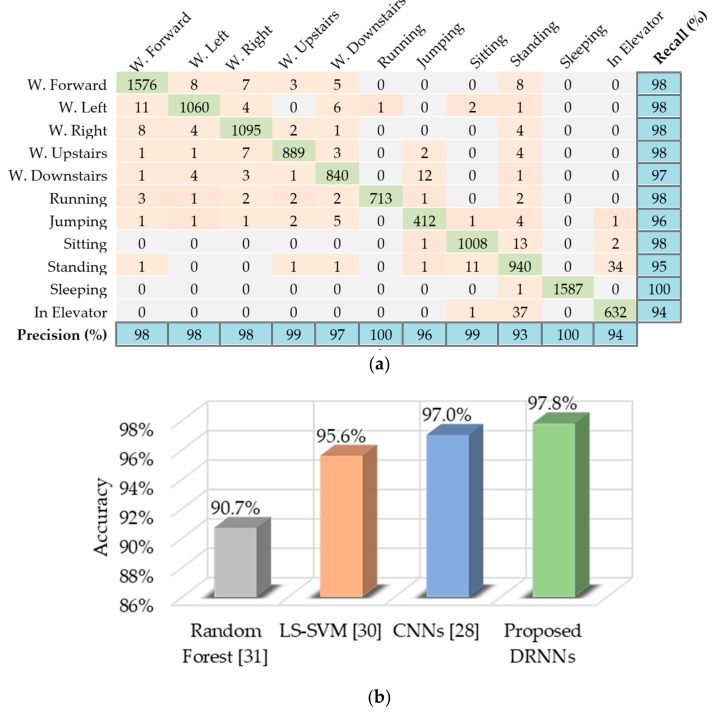
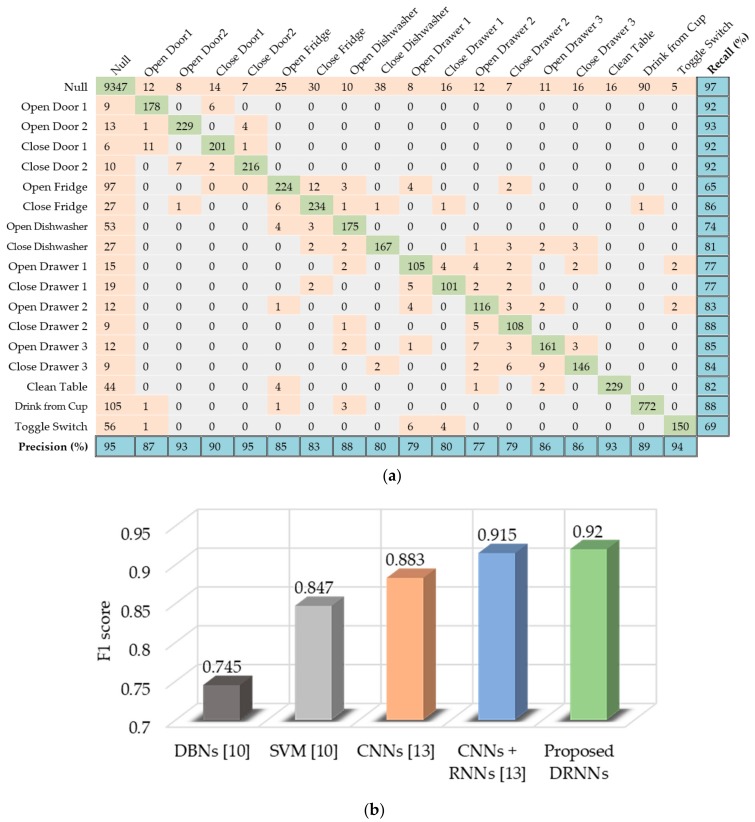
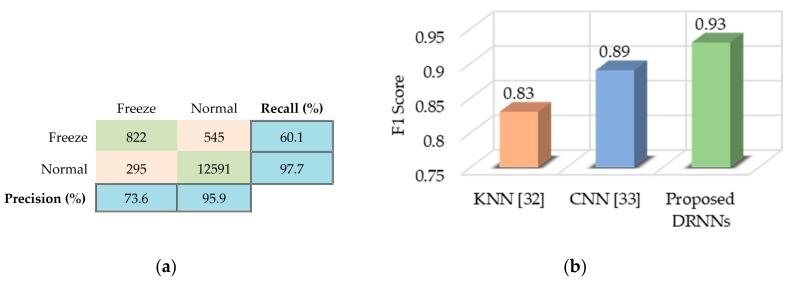
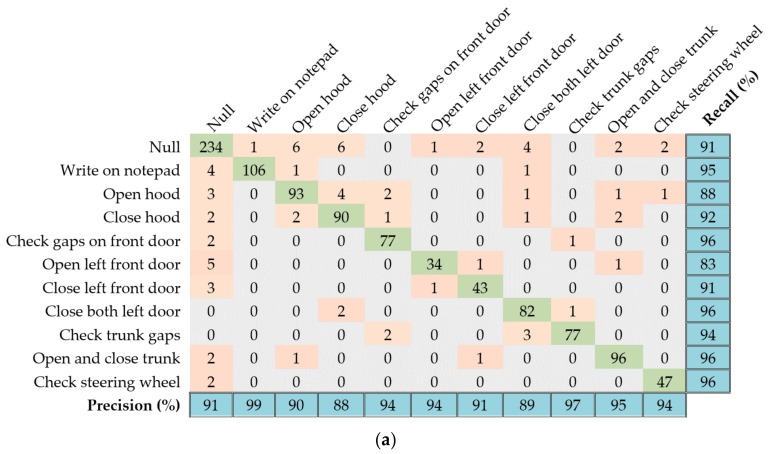
References
-
- Graves A., Mohamed A., Hinton G. Speech recognition with deep recurrent neural networks; Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing; Vancouver, BC, Canada. 26–31 May 2013; pp. 6645–6649.
-
- Sundermeyer M., Schlüter R., Ney H. LSTM Neural Networks for Language Modeling; Proceedings of the Thirteenth Annual Conference of the International Speech Communication Association; Portland, OR, USA. 9–13 September 2012.
-
- Yao L., Cho K., Ballas N., Paí C., Courville A. Describing Videos by Exploiting Temporal Structure; Proceedings of the IEEE International Conference on Computer Vision; Santiago, Chile. 7–13 December 2015.
-
- Graves A. Supervised Sequence Labelling with Recurrent Neural Networks. Volume 385. Springer; Berlin/Heidelberg, Germany: 2012. Studies in Computational Intelligence.
-
- Plötz T., Hammerla N.Y., Olivier P. Feature Learning for Activity Recognition in Ubiquitous Computing; Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence; Barcelona, Catalonia, Spain. 16–22 July 2011; pp. 1729–1734.
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
