

Enabling phenotypic big data with PheNorm
- PMID: 29126253
- PMCID: PMC6251688
- DOI: 10.1093/jamia/ocx111
Enabling phenotypic big data with PheNorm
Abstract
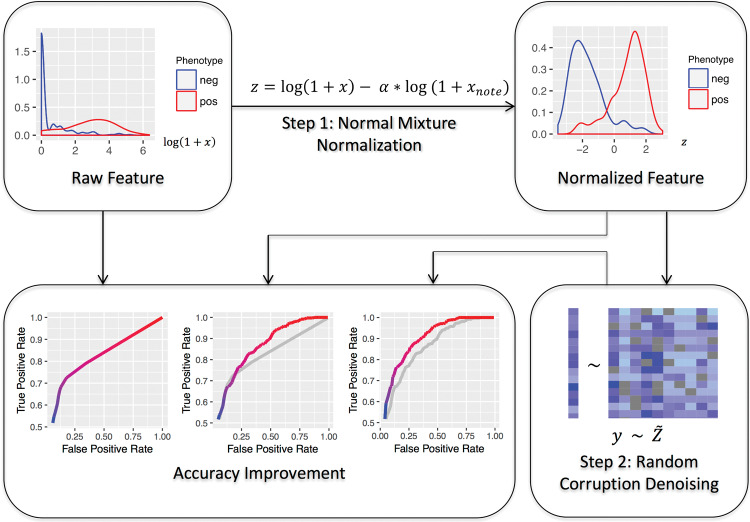
Objective: Electronic health record (EHR)-based phenotyping infers whether a patient has a disease based on the information in his or her EHR. A human-annotated training set with gold-standard disease status labels is usually required to build an algorithm for phenotyping based on a set of predictive features. The time intensiveness of annotation and feature curation severely limits the ability to achieve high-throughput phenotyping. While previous studies have successfully automated feature curation, annotation remains a major bottleneck. In this paper, we present PheNorm, a phenotyping algorithm that does not require expert-labeled samples for training.
Methods: The most predictive features, such as the number of International Classification of Diseases, Ninth Revision, Clinical Modification (ICD-9-CM) codes or mentions of the target phenotype, are normalized to resemble a normal mixture distribution with high area under the receiver operating curve (AUC) for prediction. The transformed features are then denoised and combined into a score for accurate disease classification.
Results: We validated the accuracy of PheNorm with 4 phenotypes: coronary artery disease, rheumatoid arthritis, Crohn's disease, and ulcerative colitis. The AUCs of the PheNorm score reached 0.90, 0.94, 0.95, and 0.94 for the 4 phenotypes, respectively, which were comparable to the accuracy of supervised algorithms trained with sample sizes of 100-300, with no statistically significant difference.
Conclusion: The accuracy of the PheNorm algorithms is on par with algorithms trained with annotated samples. PheNorm fully automates the generation of accurate phenotyping algorithms and demonstrates the capacity for EHR-driven annotations to scale to the next level - phenotypic big data.
Keywords: electronic health records; high-throughput phenotyping; phenotypic big data; precision medicine.
© The Author 2017. Published by Oxford University Press on behalf of the American Medical Informatics Association. All rights reserved. For Permissions, please email: journals.permissions@oup.com
Figures
References
-
- National Human Genome Research Institute. Human Genome Project Completion: Frequently Asked Questions. www.genome.gov/11006943/Human-Genome-Project-Completion-Frequently-Asked.... Accessed April 112 017.
-
- Gaziano JM, Concato J, Brophy M, et al. Million Veteran Program: a mega-biobank to study genetic influences on health and disease. J Clin Epidemiol. 2016;70:214–23. - PubMed
-
- Kohane IS. Using electronic health records to drive discovery in disease genomics. Nat Rev Genet. 2011;12:417–28. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
