

Hierarchical attention networks for information extraction from cancer pathology reports
- PMID: 29155996
- PMCID: PMC7282502
- DOI: 10.1093/jamia/ocx131
Hierarchical attention networks for information extraction from cancer pathology reports
Abstract
Objective: We explored how a deep learning (DL) approach based on hierarchical attention networks (HANs) can improve model performance for multiple information extraction tasks from unstructured cancer pathology reports compared to conventional methods that do not sufficiently capture syntactic and semantic contexts from free-text documents.
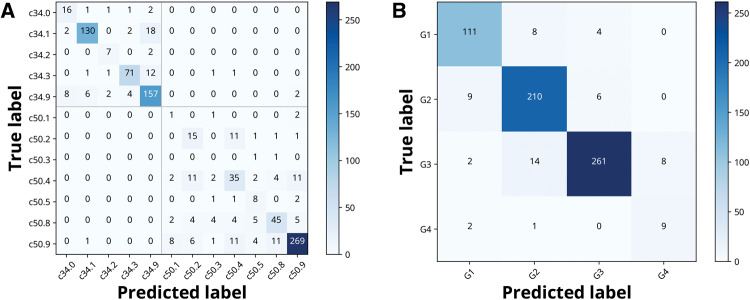
Materials and methods: Data for our analyses were obtained from 942 deidentified pathology reports collected by the National Cancer Institute Surveillance, Epidemiology, and End Results program. The HAN was implemented for 2 information extraction tasks: (1) primary site, matched to 12 International Classification of Diseases for Oncology topography codes (7 breast, 5 lung primary sites), and (2) histological grade classification, matched to G1-G4. Model performance metrics were compared to conventional machine learning (ML) approaches including naive Bayes, logistic regression, support vector machine, random forest, and extreme gradient boosting, and other DL models, including a recurrent neural network (RNN), a recurrent neural network with attention (RNN w/A), and a convolutional neural network.
Results: Our results demonstrate that for both information tasks, HAN performed significantly better compared to the conventional ML and DL techniques. In particular, across the 2 tasks, the mean micro and macro F-scores for the HAN with pretraining were (0.852,0.708), compared to naive Bayes (0.518, 0.213), logistic regression (0.682, 0.453), support vector machine (0.634, 0.434), random forest (0.698, 0.508), extreme gradient boosting (0.696, 0.522), RNN (0.505, 0.301), RNN w/A (0.637, 0.471), and convolutional neural network (0.714, 0.460).
Conclusions: HAN-based DL models show promise in information abstraction tasks within unstructured clinical pathology reports.
Keywords: attention networks; classification; clinical pathology reports; information retrieval; recurrent neural nets.
© The Author 2017. Published by Oxford University Press on behalf of the American Medical Informatics Association.
Figures




References
-
- National Cancer Institute.Overview of the SEER Program.2017https://seer.cancer.gov/about/overview.html. Accessed October 10, 2017.
-
- Kumar A,Irsoy O,Ondruska P,et al.Ask me anything: dynamic memory networks for natural language processing. In:Proc Int Conf Mach Learn. 2016:1378–87.
-
- Kim Y. Convolutional neural networks for sentence classification.arXiv preprint arXiv:14085882. 2014.
-
- Lipton Z,Berkowitz J,Elkan C. A critical review of recurrent neural networks for sequence learning.arXiv preprint arXiv:150600019. 2015.
