

Feature-based learning improves adaptability without compromising precision
- PMID: 29170381
- PMCID: PMC5700946
- DOI: 10.1038/s41467-017-01874-w
Feature-based learning improves adaptability without compromising precision
Abstract
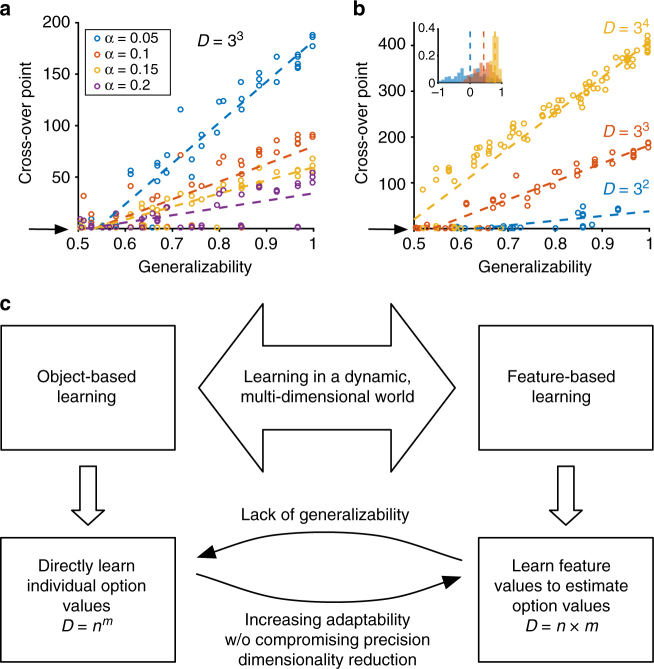
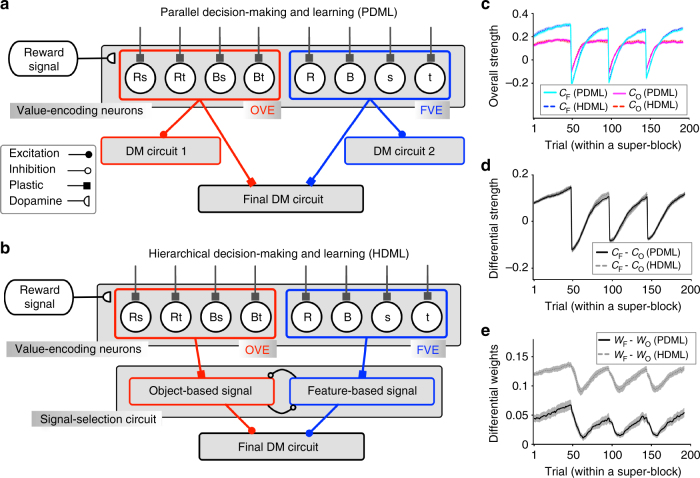
Learning from reward feedback is essential for survival but can become extremely challenging with myriad choice options. Here, we propose that learning reward values of individual features can provide a heuristic for estimating reward values of choice options in dynamic, multi-dimensional environments. We hypothesize that this feature-based learning occurs not just because it can reduce dimensionality, but more importantly because it can increase adaptability without compromising precision of learning. We experimentally test this hypothesis and find that in dynamic environments, human subjects adopt feature-based learning even when this approach does not reduce dimensionality. Even in static, low-dimensional environments, subjects initially adopt feature-based learning and gradually switch to learning reward values of individual options, depending on how accurately objects' values can be predicted by combining feature values. Our computational models reproduce these results and highlight the importance of neurons coding feature values for parallel learning of values for features and objects.
Conflict of interest statement
The authors declare no competing financial interests.
Figures





References
-
- Barto AG, Mahadevan S. Recent advances in hierarchical reinforcement learning. Discrete Event Dyn. Syst. 2003;13:341–379. doi: 10.1023/A:1025696116075. - DOI
-
- Hastie, T., Tibshirani, R. & Friedman, J. The Elements of Statistical Learning: Data Mining, Inference and Prediction 1st edn (Springer-Verlag, New York, 2001).
-
- Sutton, R. S. & Barto, A. G. Reinforcement Learning: an Introduction. (Cambridge, MA: MIT Press, 1998).
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
