

Identifying metabolites by integrating metabolome databases with mass spectrometry cheminformatics
- PMID: 29176591
- PMCID: PMC6358022
- DOI: 10.1038/nmeth.4512
Identifying metabolites by integrating metabolome databases with mass spectrometry cheminformatics
Abstract
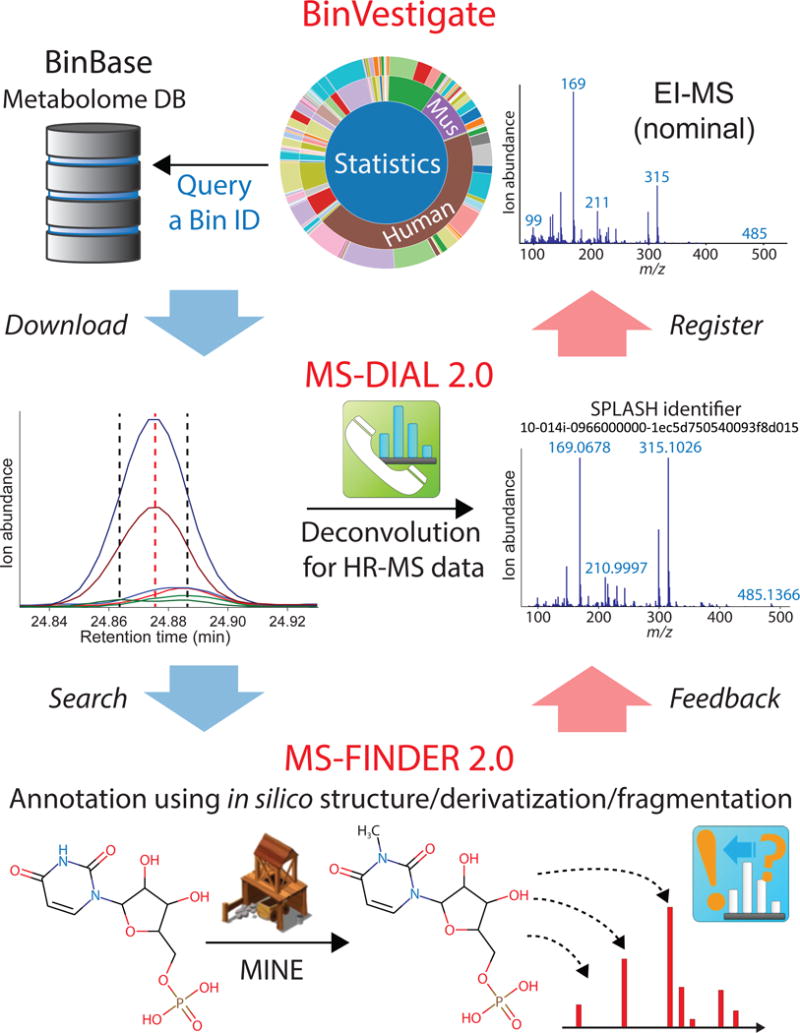
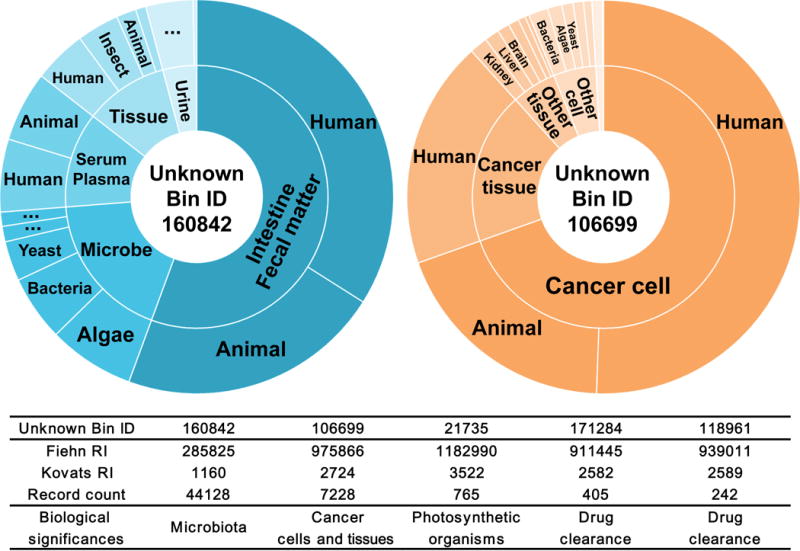
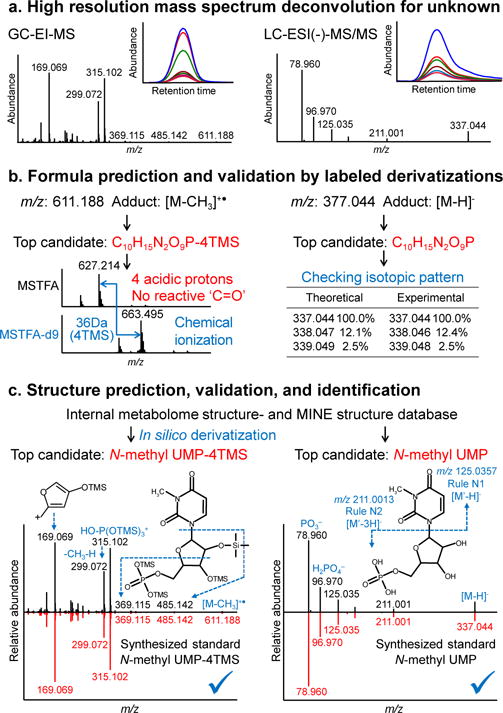
Novel metabolites distinct from canonical pathways can be identified through the integration of three cheminformatics tools: BinVestigate, which queries the BinBase gas chromatography-mass spectrometry (GC-MS) metabolome database to match unknowns with biological metadata across over 110,000 samples; MS-DIAL 2.0, a software tool for chromatographic deconvolution of high-resolution GC-MS or liquid chromatography-mass spectrometry (LC-MS); and MS-FINDER 2.0, a structure-elucidation program that uses a combination of 14 metabolome databases in addition to an enzyme promiscuity library. We showcase our workflow by annotating N-methyl-uridine monophosphate (UMP), lysomonogalactosyl-monopalmitin, N-methylalanine, and two propofol derivatives.
Conflict of interest statement
The authors declare competing financial interests. Atsushi Ogiwara is a developer in Reifycs Inc., which provides the ABF converter of mass spectral data for free at
Figures
References
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
