

Evaluating Fast Maximum Likelihood-Based Phylogenetic Programs Using Empirical Phylogenomic Data Sets
- PMID: 29177474
- PMCID: PMC5850867
- DOI: 10.1093/molbev/msx302
Evaluating Fast Maximum Likelihood-Based Phylogenetic Programs Using Empirical Phylogenomic Data Sets
Abstract
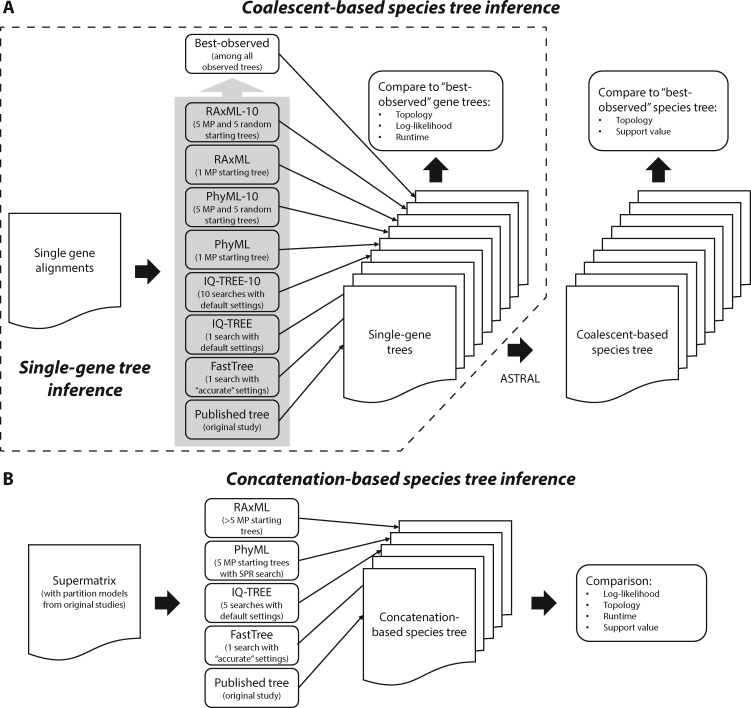
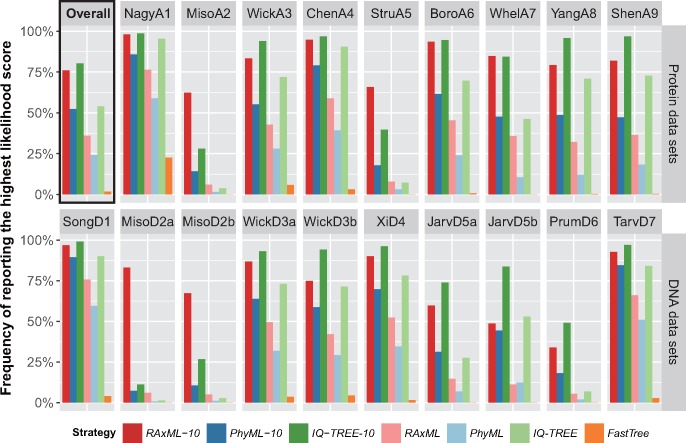
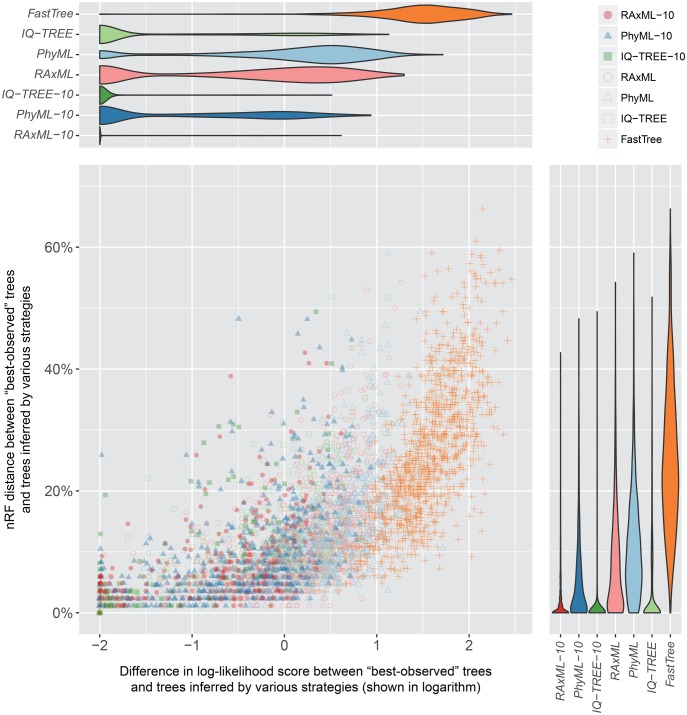
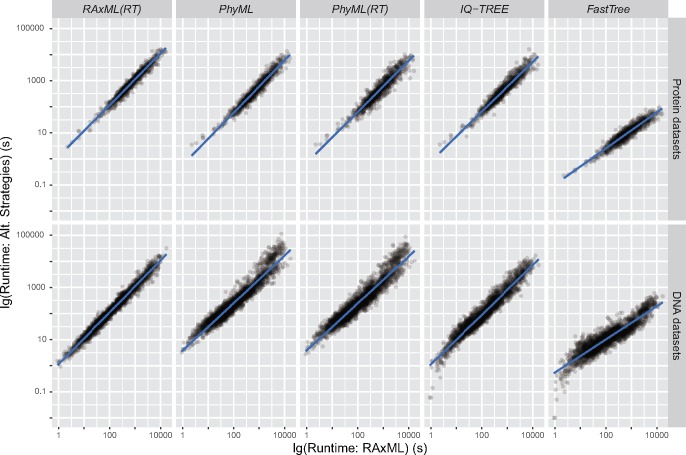
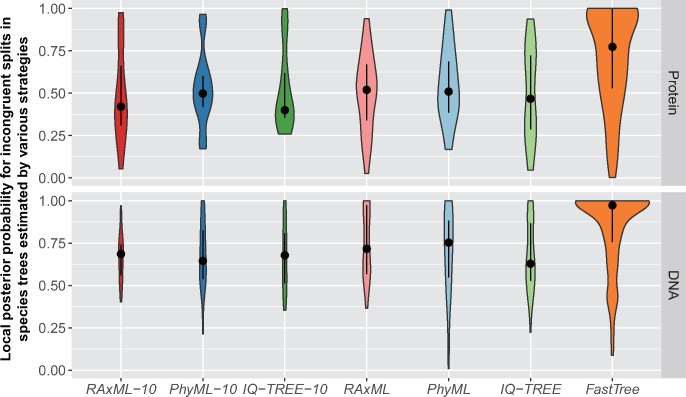
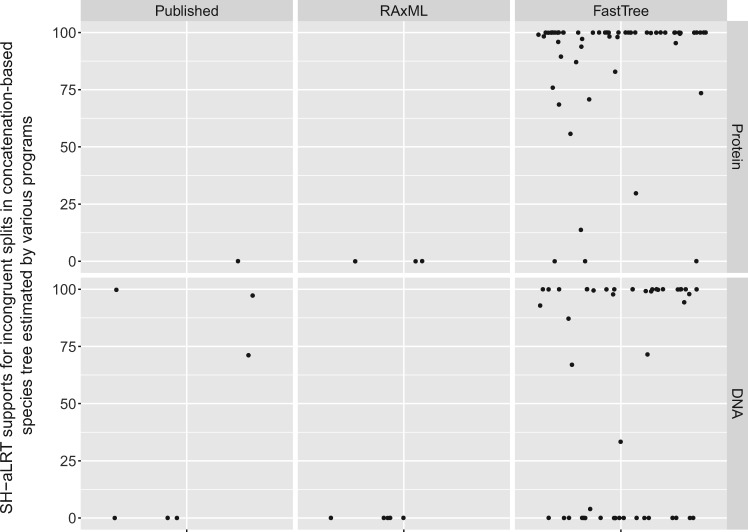
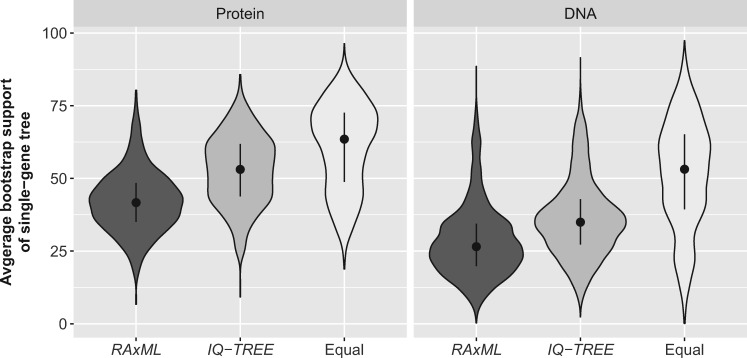
The sizes of the data matrices assembled to resolve branches of the tree of life have increased dramatically, motivating the development of programs for fast, yet accurate, inference. For example, several different fast programs have been developed in the very popular maximum likelihood framework, including RAxML/ExaML, PhyML, IQ-TREE, and FastTree. Although these programs are widely used, a systematic evaluation and comparison of their performance using empirical genome-scale data matrices has so far been lacking. To address this question, we evaluated these four programs on 19 empirical phylogenomic data sets with hundreds to thousands of genes and up to 200 taxa with respect to likelihood maximization, tree topology, and computational speed. For single-gene tree inference, we found that the more exhaustive and slower strategies (ten searches per alignment) outperformed faster strategies (one tree search per alignment) using RAxML, PhyML, or IQ-TREE. Interestingly, single-gene trees inferred by the three programs yielded comparable coalescent-based species tree estimations. For concatenation-based species tree inference, IQ-TREE consistently achieved the best-observed likelihoods for all data sets, and RAxML/ExaML was a close second. In contrast, PhyML often failed to complete concatenation-based analyses, whereas FastTree was the fastest but generated lower likelihood values and more dissimilar tree topologies in both types of analyses. Finally, data matrix properties, such as the number of taxa and the strength of phylogenetic signal, sometimes substantially influenced the programs' relative performance. Our results provide real-world gene and species tree phylogenetic inference benchmarks to inform the design and execution of large-scale phylogenomic data analyses.
Keywords: heuristic search; molecular evolution; topology; tree space.
© The Author 2017. Published by Oxford University Press on behalf of the Society for Molecular Biology and Evolution.
Figures


References
-
- Bruno WJ, Socci ND, Halpern AL.. 2000. Weighted neighbor joining: a likelihood-based approach to distance-based phylogeny reconstruction. Mol Biol Evol. 171:189–197.http://dx.doi.org/10.1093/oxfordjournals.molbev.a026231 - DOI - PubMed
-
- Bryant D, Galtier N, Poursat M-A.. 2005. Likelihood calculation in molecular phylogenetics In: Gascuel O, editor. Mathematics of evolution and phylogeny. Oxford (UK: ): Oxford University Press; p. 33–62.
-
- Chen MY, Liang D, Zhang P.. 2015. Selecting question-specific genes to reduce incongruence in phylogenomics: a case study of jawed vertebrate backbone phylogeny. Syst Biol. 646:1104–1120.http://dx.doi.org/10.1093/sysbio/syv059 - DOI - PubMed
-
- Chernomor O, von Haeseler A, Minh BQ.. 2016. Terrace aware data structure for phylogenomic inference from supermatrices. Syst Biol. 656: 997–1008.http://dx.doi.org/10.1093/sysbio/syw037 - DOI - PMC - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
