

Stabilizing patterns in time: Neural network approach
- PMID: 29232710
- PMCID: PMC5741269
- DOI: 10.1371/journal.pcbi.1005861
Stabilizing patterns in time: Neural network approach
Abstract
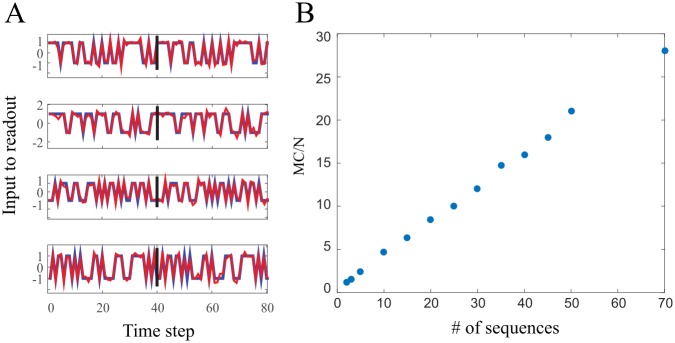
Recurrent and feedback networks are capable of holding dynamic memories. Nonetheless, training a network for that task is challenging. In order to do so, one should face non-linear propagation of errors in the system. Small deviations from the desired dynamics due to error or inherent noise might have a dramatic effect in the future. A method to cope with these difficulties is thus needed. In this work we focus on recurrent networks with linear activation functions and binary output unit. We characterize its ability to reproduce a temporal sequence of actions over its output unit. We suggest casting the temporal learning problem to a perceptron problem. In the discrete case a finite margin appears, providing the network, to some extent, robustness to noise, for which it performs perfectly (i.e. producing a desired sequence for an arbitrary number of cycles flawlessly). In the continuous case the margin approaches zero when the output unit changes its state, hence the network is only able to reproduce the sequence with slight jitters. Numerical simulation suggest that in the discrete time case, the longest sequence that can be learned scales, at best, as square root of the network size. A dramatic effect occurs when learning several short sequences in parallel, that is, their total length substantially exceeds the length of the longest single sequence the network can learn. This model easily generalizes to an arbitrary number of output units, which boost its performance. This effect is demonstrated by considering two practical examples for sequence learning. This work suggests a way to overcome stability problems for training recurrent networks and further quantifies the performance of a network under the specific learning scheme.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures




References
-
- Reiss R. A theory of resonance networks Neural theory. 1964;.
-
- Harmon LD. Neuromimes: action of a reciprocally inhibitory pair. Science. 1964;146(3649):1323–1325. doi: 10.1126/science.146.3649.1323 - DOI - PubMed
-
- Wilson DM, Waldron I. Models for the generation of the motor output pattern in flying locusts. Proceedings of the IEEE. 1968;56(6):1058–1064. doi: 10.1109/PROC.1968.6457 - DOI
-
- Kling U, Székely G. Simulation of rhythmic nervous activities. Kybernetik. 1968;5(3):89–103. doi: 10.1007/BF00288899 - DOI - PubMed
-
- Kleinfeld D, Sompolinsky H. Associative neural network model for the generation of temporal patterns. Theory and application to central pattern generators. Biophysical Journal. 1988;54(6):1039 doi: 10.1016/S0006-3495(88)83041-8 - DOI - PMC - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
