

Exploring Feature Dimensions to Learn a New Policy in an Uninformed Reinforcement Learning Task
- PMID: 29247192
- PMCID: PMC5732284
- DOI: 10.1038/s41598-017-17687-2
Exploring Feature Dimensions to Learn a New Policy in an Uninformed Reinforcement Learning Task
Abstract
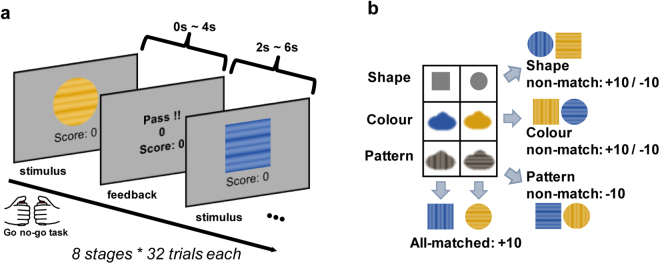
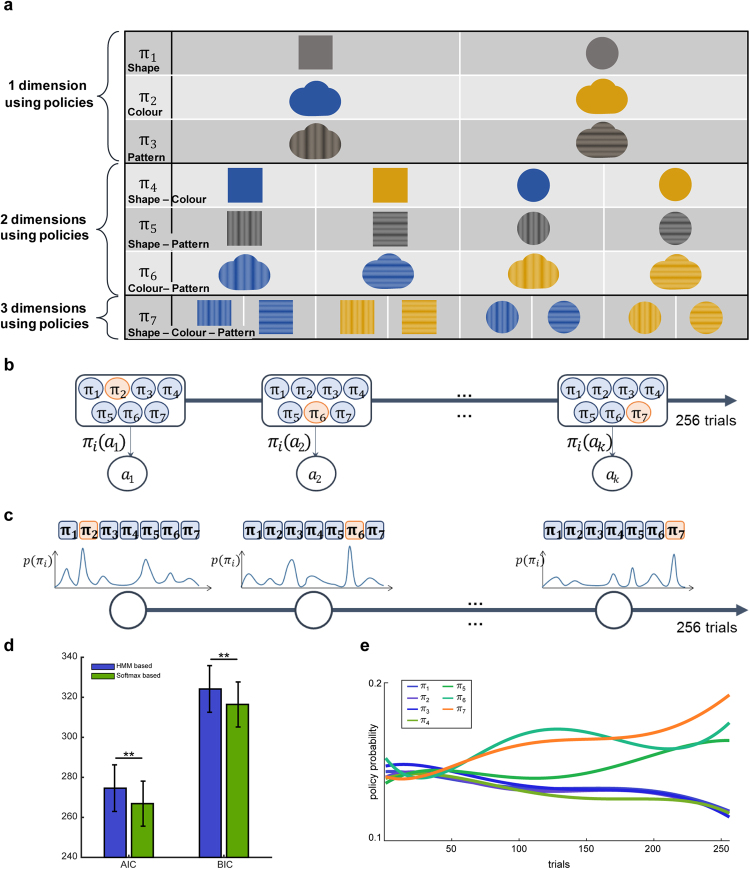
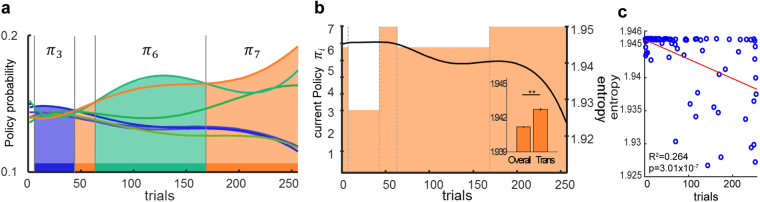
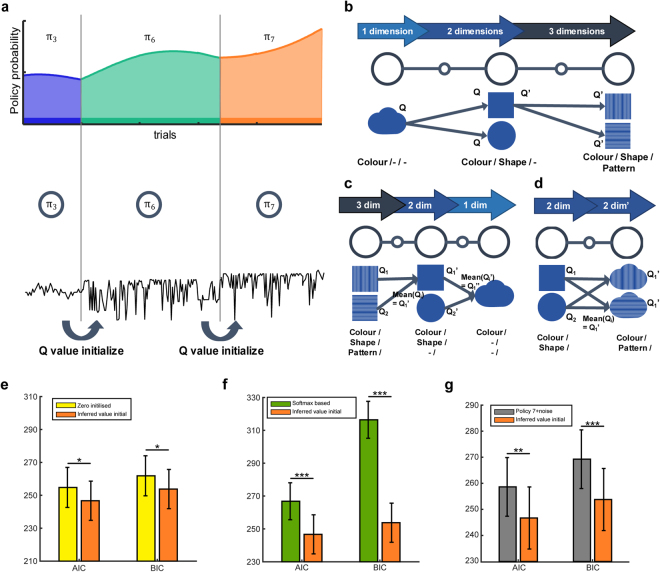
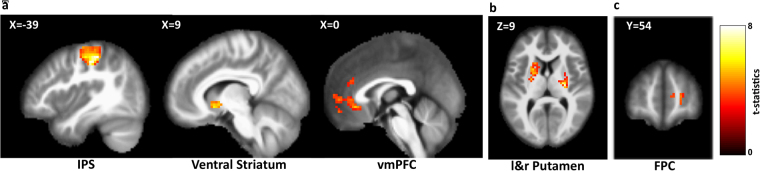
When making a choice with limited information, we explore new features through trial-and-error to learn how they are related. However, few studies have investigated exploratory behaviour when information is limited. In this study, we address, at both the behavioural and neural level, how, when, and why humans explore new feature dimensions to learn a new policy for choosing a state-space. We designed a novel multi-dimensional reinforcement learning task to encourage participants to explore and learn new features, then used a reinforcement learning algorithm to model policy exploration and learning behaviour. Our results provide the first evidence that, when humans explore new feature dimensions, their values are transferred from the previous policy to the new online (active) policy, as opposed to being learned from scratch. We further demonstrated that exploration may be regulated by the level of cognitive ambiguity, and that this process might be controlled by the frontopolar cortex. This opens up new possibilities of further understanding how humans explore new features in an open-space with limited information.
Conflict of interest statement
The authors declare that they have no competing interests.
Figures
References
-
- Beharelle AR, Polanía R, Hare TA, Ruff CC. Transcranial Stimulation over Frontopolar Cortex Elucidates the Choice Attributes and Neural Mechanisms Used to Resolve Exploration–Exploitation Trade-Offs. Journal of Neuroscience. 2015;35:14544–14556. doi: 10.1523/JNEUROSCI.2322-15.2015. - DOI - PMC - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
