

Comparison of machine learning techniques to predict all-cause mortality using fitness data: the Henry ford exercIse testing (FIT) project
- PMID: 29258510
- PMCID: PMC5735871
- DOI: 10.1186/s12911-017-0566-6
Comparison of machine learning techniques to predict all-cause mortality using fitness data: the Henry ford exercIse testing (FIT) project
Abstract
Background: Prior studies have demonstrated that cardiorespiratory fitness (CRF) is a strong marker of cardiovascular health. Machine learning (ML) can enhance the prediction of outcomes through classification techniques that classify the data into predetermined categories. The aim of this study is to present an evaluation and comparison of how machine learning techniques can be applied on medical records of cardiorespiratory fitness and how the various techniques differ in terms of capabilities of predicting medical outcomes (e.g. mortality).
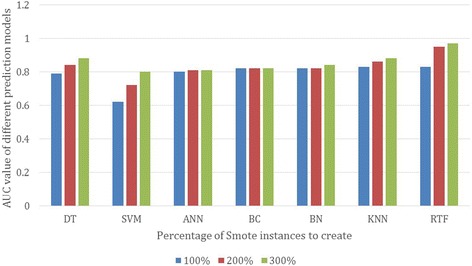
Methods: We use data of 34,212 patients free of known coronary artery disease or heart failure who underwent clinician-referred exercise treadmill stress testing at Henry Ford Health Systems Between 1991 and 2009 and had a complete 10-year follow-up. Seven machine learning classification techniques were evaluated: Decision Tree (DT), Support Vector Machine (SVM), Artificial Neural Networks (ANN), Naïve Bayesian Classifier (BC), Bayesian Network (BN), K-Nearest Neighbor (KNN) and Random Forest (RF). In order to handle the imbalanced dataset used, the Synthetic Minority Over-Sampling Technique (SMOTE) is used.
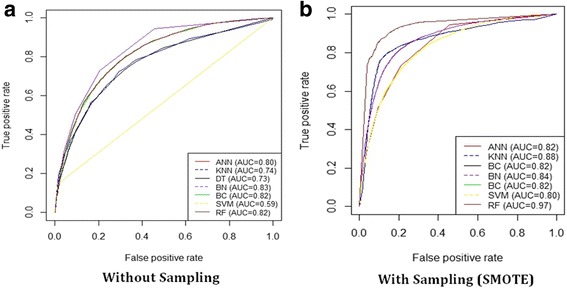
Results: Two set of experiments have been conducted with and without the SMOTE sampling technique. On average over different evaluation metrics, SVM Classifier has shown the lowest performance while other models like BN, BC and DT performed better. The RF classifier has shown the best performance (AUC = 0.97) among all models trained using the SMOTE sampling.
Conclusions: The results show that various ML techniques can significantly vary in terms of its performance for the different evaluation metrics. It is also not necessarily that the more complex the ML model, the more prediction accuracy can be achieved. The prediction performance of all models trained with SMOTE is much better than the performance of models trained without SMOTE. The study shows the potential of machine learning methods for predicting all-cause mortality using cardiorespiratory fitness data.
Keywords: All-cause mortality; FIT (Henry ford ExercIse testing) project; Machine learning.
Conflict of interest statement
Ethics approval and consent to participate
This article does not contain any studies with human participants or animals performed by any of the authors. The FIT project is approved by the IRB (ethics committee) of HFH hospital (IRB #: 5812). Informed consent was waived due to retrospective nature of the study. The consent to participate is not required.
Consent for publication
Not applicable. The manuscript doesn’t contain any individual identifying data.
Competing interests
The authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Figures
Similar articles
-
Predicting diabetes mellitus using SMOTE and ensemble machine learning approach: The Henry Ford ExercIse Testing (FIT) project.PLoS One. 2017 Jul 24;12(7):e0179805. doi: 10.1371/journal.pone.0179805. eCollection 2017. PLoS One. 2017. PMID: 28738059 Free PMC article.
-
Using machine learning on cardiorespiratory fitness data for predicting hypertension: The Henry Ford ExercIse Testing (FIT) Project.PLoS One. 2018 Apr 18;13(4):e0195344. doi: 10.1371/journal.pone.0195344. eCollection 2018. PLoS One. 2018. PMID: 29668729 Free PMC article.
-
Using Machine Learning to Define the Association between Cardiorespiratory Fitness and All-Cause Mortality (from the Henry Ford Exercise Testing Project).Am J Cardiol. 2017 Dec 1;120(11):2078-2084. doi: 10.1016/j.amjcard.2017.08.029. Epub 2017 Aug 30. Am J Cardiol. 2017. PMID: 28951020
-
Machine learning and deep learning methods that use omics data for metastasis prediction.Comput Struct Biotechnol J. 2021 Sep 4;19:5008-5018. doi: 10.1016/j.csbj.2021.09.001. eCollection 2021. Comput Struct Biotechnol J. 2021. PMID: 34589181 Free PMC article. Review.
-
Predicting academic performance associated with physical fitness of primary school students using machine learning methods.Complement Ther Clin Pract. 2023 May;51:101736. doi: 10.1016/j.ctcp.2023.101736. Epub 2023 Feb 11. Complement Ther Clin Pract. 2023. PMID: 36821949 Review.
Cited by
-
Prediction of Prednisolone Dose Correction Using Machine Learning.J Healthc Inform Res. 2023 Feb 15;7(1):84-103. doi: 10.1007/s41666-023-00128-3. eCollection 2023 Mar. J Healthc Inform Res. 2023. PMID: 36910914 Free PMC article.
-
Estimated Artificial Neural Network Modeling of Maximal Oxygen Uptake Based on Multistage 10-m Shuttle Run Test in Healthy Adults.Int J Environ Res Public Health. 2021 Aug 12;18(16):8510. doi: 10.3390/ijerph18168510. Int J Environ Res Public Health. 2021. PMID: 34444259 Free PMC article.
-
Machine-learning predicts time-series prognosis factors in metastatic prostate cancer patients treated with androgen deprivation therapy.Sci Rep. 2023 Apr 18;13(1):6325. doi: 10.1038/s41598-023-32987-6. Sci Rep. 2023. PMID: 37072487 Free PMC article.
-
Using machine-learning approach to distinguish patients with methamphetamine dependence from healthy subjects in a virtual reality environment.Brain Behav. 2020 Nov;10(11):e01814. doi: 10.1002/brb3.1814. Epub 2020 Aug 29. Brain Behav. 2020. PMID: 32862513 Free PMC article.
-
Integrative Interpretation of Cardiopulmonary Exercise Tests for Cardiovascular Outcome Prediction: A Machine Learning Approach.Diagnostics (Basel). 2023 Jun 13;13(12):2051. doi: 10.3390/diagnostics13122051. Diagnostics (Basel). 2023. PMID: 37370946 Free PMC article.
References
-
- Alpaydin E. Introduction to machine learning. MIT press; 2014. https://mitpress.mit.edu/books/introduction-machine-learning-0.
-
- Marsland S. Machine learning: an algorithmic perspective. CRC press; 2015. https://www.crcpress.com/Machine-Learning-An-Algorithmic-Perspective-Sec....
-
- Aggarwal CC. Data classification: algorithms and applications. CRC Press; 2014. https://www.crcpress.com/Data-Classification-Algorithms-and-Applications....
-
- Mayer-Schonberger V, Cukier K. Big data: a revolution that will transform how we live, work, and think. Houghton Mifflin Harcourt; 2013. https://www.amazon.com/Big-Data-Revolution-Transform-Think/dp/0544227751.
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
