

Leveraging uncertainty information from deep neural networks for disease detection
- PMID: 29259224
- PMCID: PMC5736701
- DOI: 10.1038/s41598-017-17876-z
Leveraging uncertainty information from deep neural networks for disease detection
Abstract
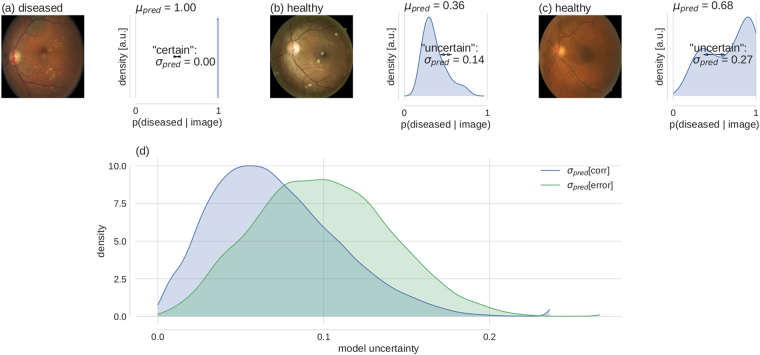
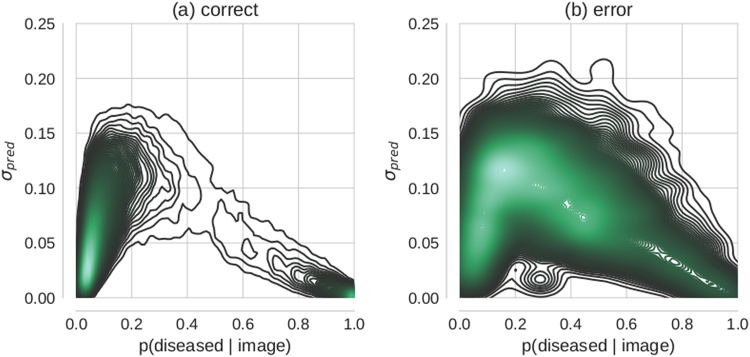
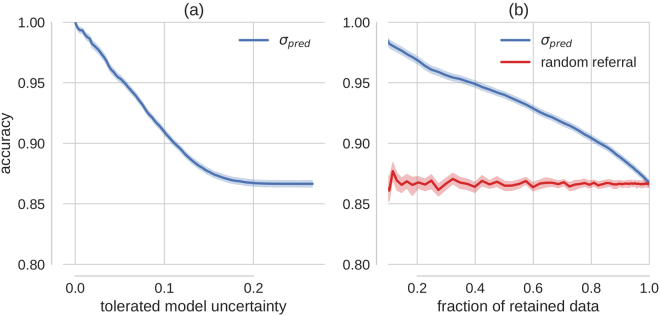
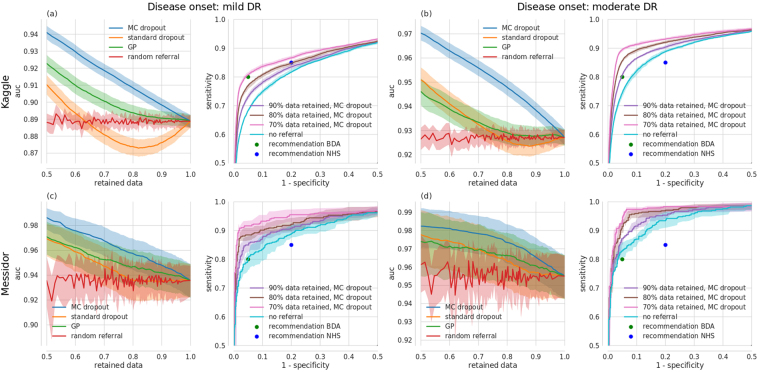
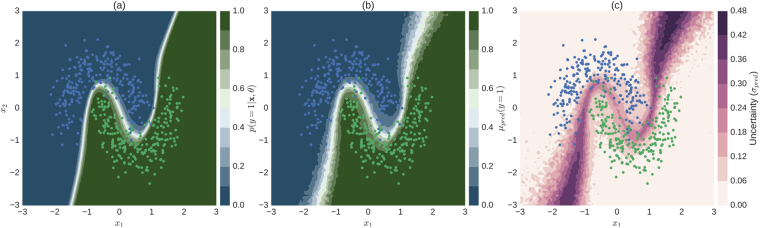
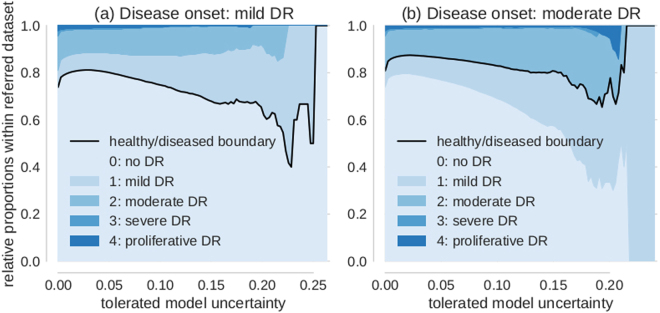
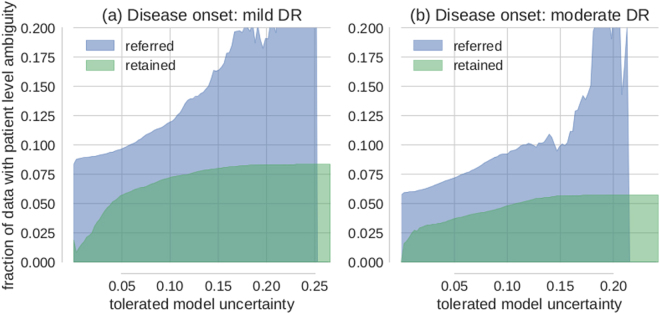
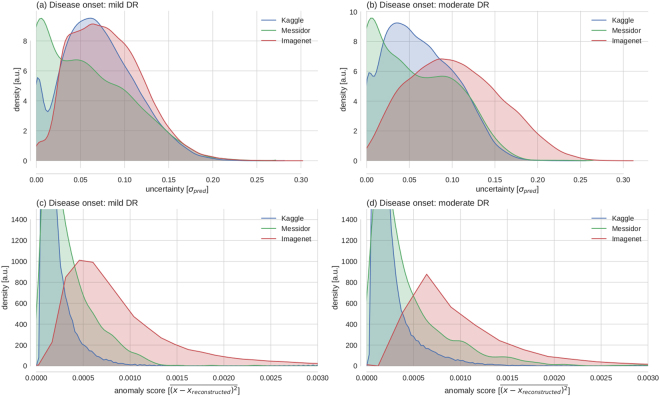
Deep learning (DL) has revolutionized the field of computer vision and image processing. In medical imaging, algorithmic solutions based on DL have been shown to achieve high performance on tasks that previously required medical experts. However, DL-based solutions for disease detection have been proposed without methods to quantify and control their uncertainty in a decision. In contrast, a physician knows whether she is uncertain about a case and will consult more experienced colleagues if needed. Here we evaluate drop-out based Bayesian uncertainty measures for DL in diagnosing diabetic retinopathy (DR) from fundus images and show that it captures uncertainty better than straightforward alternatives. Furthermore, we show that uncertainty informed decision referral can improve diagnostic performance. Experiments across different networks, tasks and datasets show robust generalization. Depending on network capacity and task/dataset difficulty, we surpass 85% sensitivity and 80% specificity as recommended by the NHS when referring 0-20% of the most uncertain decisions for further inspection. We analyse causes of uncertainty by relating intuitions from 2D visualizations to the high-dimensional image space. While uncertainty is sensitive to clinically relevant cases, sensitivity to unfamiliar data samples is task dependent, but can be rendered more robust.
Conflict of interest statement
The authors declare that they have no competing interests.
Figures
References
-
- Krizhevsky, A., Sutskever, I. & Hinton, G. E. ImageNet Classification with Deep Convolutional Neural Networks. Advances in Neural Information Processing Systems 1–9 (2012).
-
- Rusk N. Deep learning. Nature Methods. 2016;13:35–35. doi: 10.1038/nmeth.3707. - DOI
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
