

Physiological models of the lateral superior olive
- PMID: 29281618
- PMCID: PMC5744914
- DOI: 10.1371/journal.pcbi.1005903
Physiological models of the lateral superior olive
Abstract
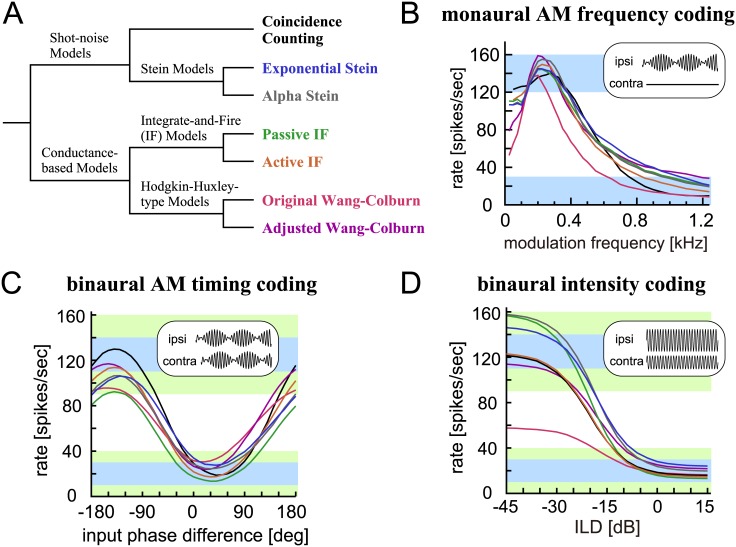
In computational biology, modeling is a fundamental tool for formulating, analyzing and predicting complex phenomena. Most neuron models, however, are designed to reproduce certain small sets of empirical data. Hence their outcome is usually not compatible or comparable with other models or datasets, making it unclear how widely applicable such models are. In this study, we investigate these aspects of modeling, namely credibility and generalizability, with a specific focus on auditory neurons involved in the localization of sound sources. The primary cues for binaural sound localization are comprised of interaural time and level differences (ITD/ILD), which are the timing and intensity differences of the sound waves arriving at the two ears. The lateral superior olive (LSO) in the auditory brainstem is one of the locations where such acoustic information is first computed. An LSO neuron receives temporally structured excitatory and inhibitory synaptic inputs that are driven by ipsi- and contralateral sound stimuli, respectively, and changes its spike rate according to binaural acoustic differences. Here we examine seven contemporary models of LSO neurons with different levels of biophysical complexity, from predominantly functional ones ('shot-noise' models) to those with more detailed physiological components (variations of integrate-and-fire and Hodgkin-Huxley-type). These models, calibrated to reproduce known monaural and binaural characteristics of LSO, generate largely similar results to each other in simulating ITD and ILD coding. Our comparisons of physiological detail, computational efficiency, predictive performances, and further expandability of the models demonstrate (1) that the simplistic, functional LSO models are suitable for applications where low computational costs and mathematical transparency are needed, (2) that more complex models with detailed membrane potential dynamics are necessary for simulation studies where sub-neuronal nonlinear processes play important roles, and (3) that, for general purposes, intermediate models might be a reasonable compromise between simplicity and biological plausibility.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures










Similar articles
-
Robustness of neuronal tuning to binaural sound localization cues against age-related loss of inhibitory synaptic inputs.PLoS Comput Biol. 2021 Jul 9;17(7):e1009130. doi: 10.1371/journal.pcbi.1009130. eCollection 2021 Jul. PLoS Comput Biol. 2021. PMID: 34242210 Free PMC article.
-
Envelope coding in the lateral superior olive. II. Characteristic delays and comparison with responses in the medial superior olive.J Neurophysiol. 1996 Oct;76(4):2137-56. doi: 10.1152/jn.1996.76.4.2137. J Neurophysiol. 1996. PMID: 8899590
-
Envelope coding in the lateral superior olive. I. Sensitivity to interaural time differences.J Neurophysiol. 1995 Mar;73(3):1043-62. doi: 10.1152/jn.1995.73.3.1043. J Neurophysiol. 1995. PMID: 7608754
-
The lateral superior olive: a functional role in sound source localization.Neuroscientist. 2003 Apr;9(2):127-43. doi: 10.1177/1073858403252228. Neuroscientist. 2003. PMID: 12708617 Review.
-
Sound localization.Handb Clin Neurol. 2015;129:99-116. doi: 10.1016/B978-0-444-62630-1.00006-8. Handb Clin Neurol. 2015. PMID: 25726265 Review.
Cited by
-
Between-ear sound frequency disparity modulates a brain stem biomarker of binaural hearing.J Neurophysiol. 2019 Sep 1;122(3):1110-1122. doi: 10.1152/jn.00057.2019. Epub 2019 Jul 17. J Neurophysiol. 2019. PMID: 31314646 Free PMC article.
-
Computational principles of neural adaptation for binaural signal integration.PLoS Comput Biol. 2020 Jul 17;16(7):e1008020. doi: 10.1371/journal.pcbi.1008020. eCollection 2020 Jul. PLoS Comput Biol. 2020. PMID: 32678847 Free PMC article.
-
Spiking Neural Networks and Mathematical Models.Adv Exp Med Biol. 2023;1424:69-79. doi: 10.1007/978-3-031-31982-2_8. Adv Exp Med Biol. 2023. PMID: 37486481 Review.
-
Effects of interaural decoherence on sensitivity to interaural level differences across frequency.J Acoust Soc Am. 2021 Jun;149(6):4630. doi: 10.1121/10.0005123. J Acoust Soc Am. 2021. PMID: 34241434 Free PMC article.
-
Across Species "Natural Ablation" Reveals the Brainstem Source of a Noninvasive Biomarker of Binaural Hearing.J Neurosci. 2018 Oct 3;38(40):8563-8573. doi: 10.1523/JNEUROSCI.1211-18.2018. Epub 2018 Aug 20. J Neurosci. 2018. PMID: 30126974 Free PMC article.
References
-
- Box GEP. Robustness in the strategy of scientific model building In: Launer RL, Wilkinson GN, editors. Robustness in Statistics, Academic Press; 1979. pp. 201–236.
-
- Aumann CA. A methodology for developing simulation models of complex systems. Ecol Modelling. 2007; 202: 385–396.
-
- Popper K. Logik der Forschung. Verlag von Julius Springer, Vienna, Austria; 1935. (English edition: The logic of scientific discovery; 1959).
-
- Secomb TW, Beard DA, Frisbee JC, Smith NP, Pries AR. The role of theoretical modeling in microcirculation research. Microcirculation. 2008; 15: 693–698. doi: 10.1080/10739680802349734 - DOI - PMC - PubMed
-
- Fernandes HL, Kording KP. In praise of "false" model and rich data. J Motor Behav. 2010; 42: 343–349. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
