

An application of machine learning to haematological diagnosis
- PMID: 29323142
- PMCID: PMC5765139
- DOI: 10.1038/s41598-017-18564-8
An application of machine learning to haematological diagnosis
Abstract
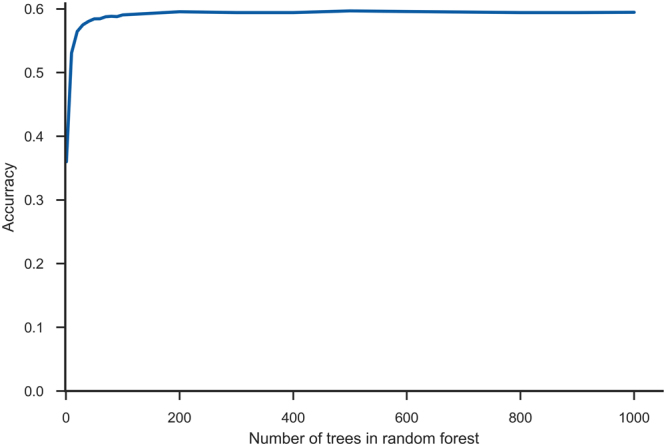
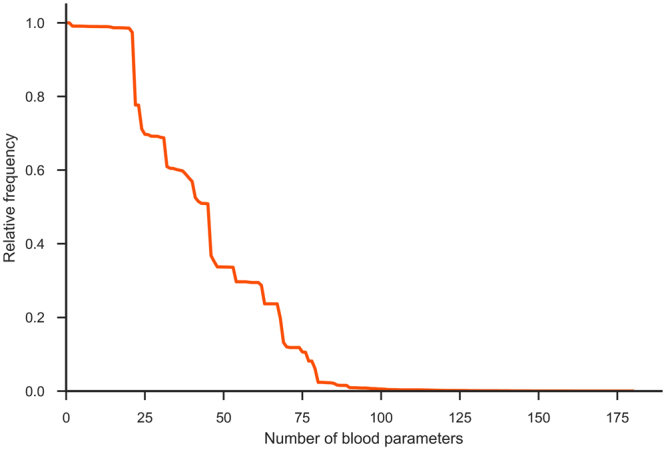
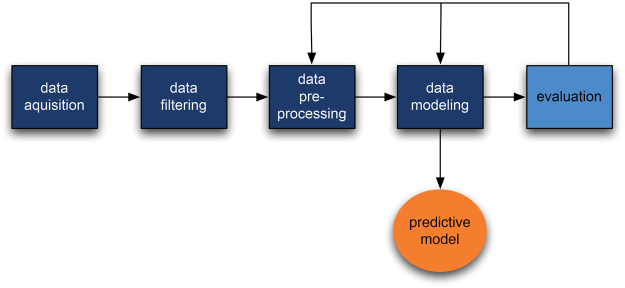
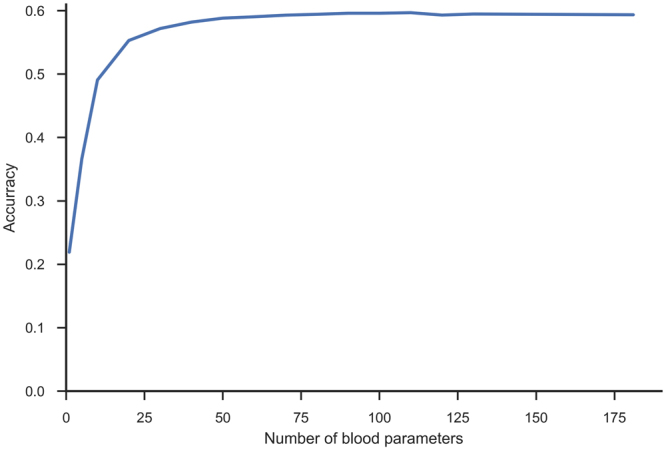
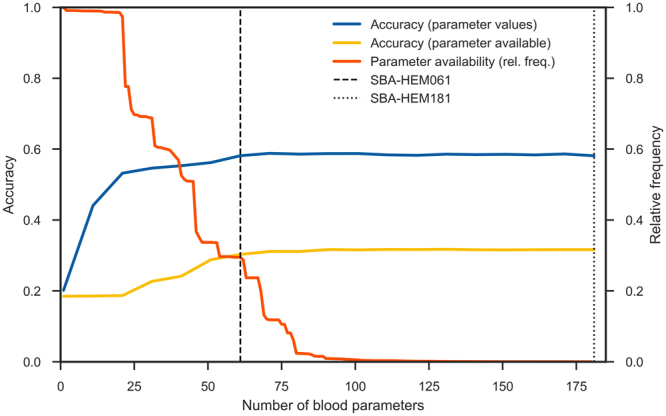
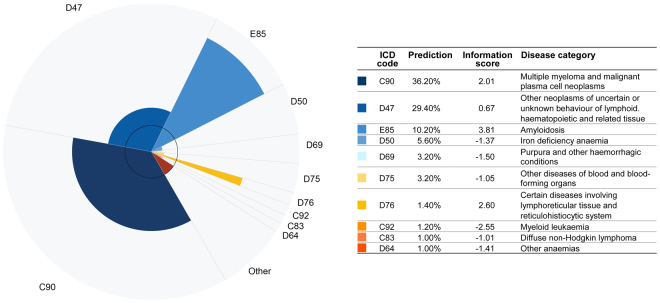
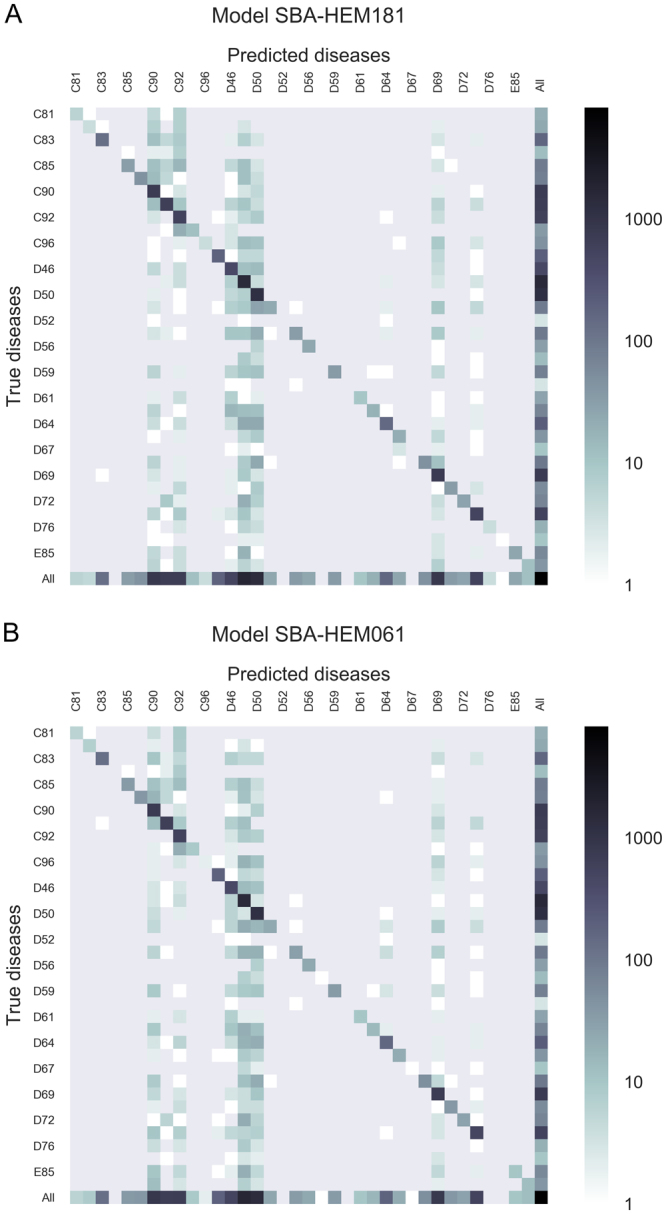
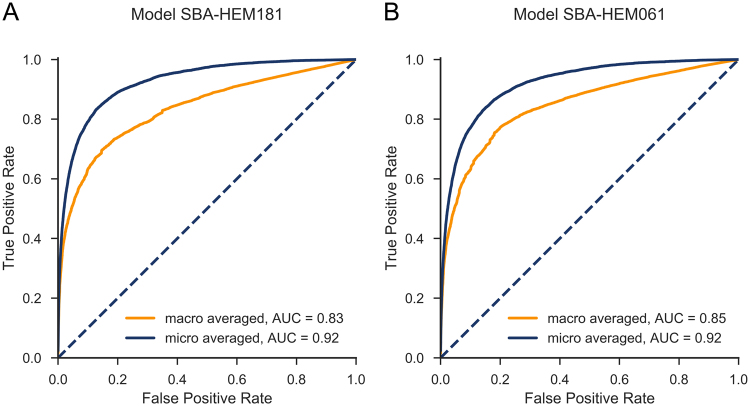
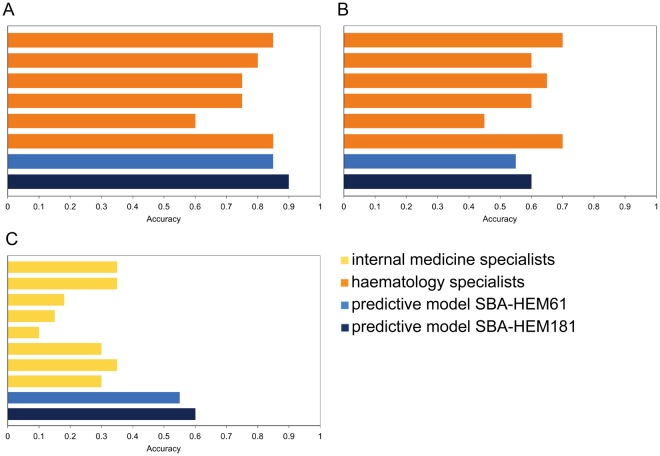
Quick and accurate medical diagnoses are crucial for the successful treatment of diseases. Using machine learning algorithms and based on laboratory blood test results, we have built two models to predict a haematologic disease. One predictive model used all the available blood test parameters and the other used only a reduced set that is usually measured upon patient admittance. Both models produced good results, obtaining prediction accuracies of 0.88 and 0.86 when considering the list of five most likely diseases and 0.59 and 0.57 when considering only the most likely disease. The models did not differ significantly, which indicates that a reduced set of parameters can represent a relevant "fingerprint" of a disease. This knowledge expands the model's utility for use by general practitioners and indicates that blood test results contain more information than physicians generally recognize. A clinical test showed that the accuracy of our predictive models was on par with that of haematology specialists. Our study is the first to show that a machine learning predictive model based on blood tests alone can be successfully applied to predict haematologic diseases. This result and could open up unprecedented possibilities for medical diagnosis.
Conflict of interest statement
Smart Blood Analytics Swiss SA (SBA) fully funded this research. Mar. N. is SBA CEO, M.K., Mat. N. and G.G. are SBA advisors.
Figures
References
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
