

Cooperating with machines
- PMID: 29339817
- PMCID: PMC5770455
- DOI: 10.1038/s41467-017-02597-8
Cooperating with machines
Abstract
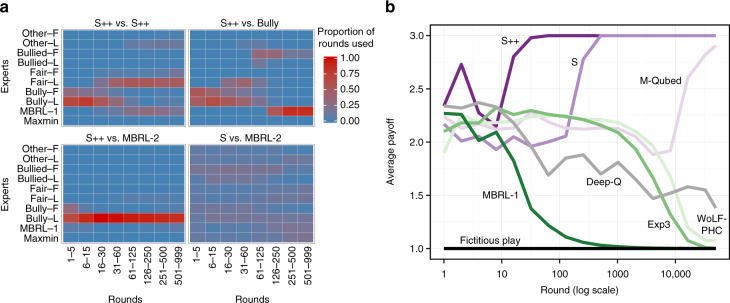
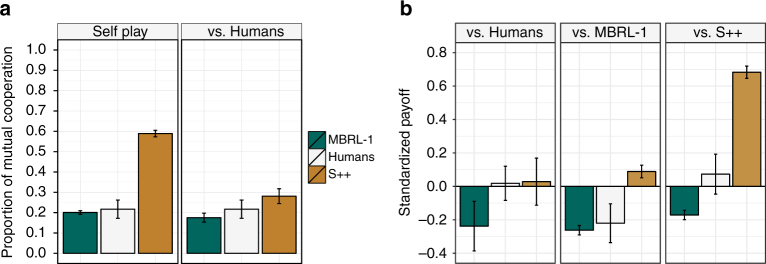
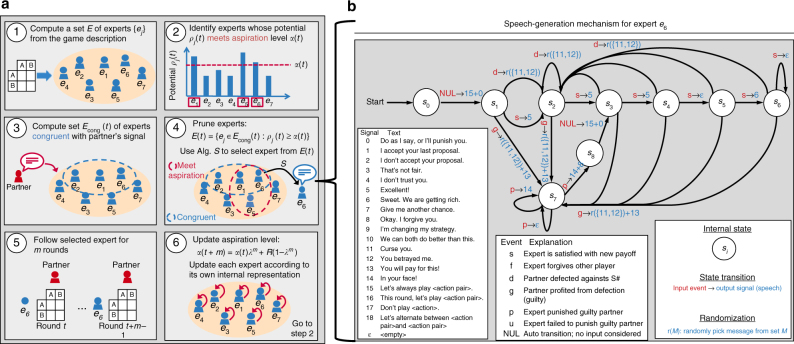
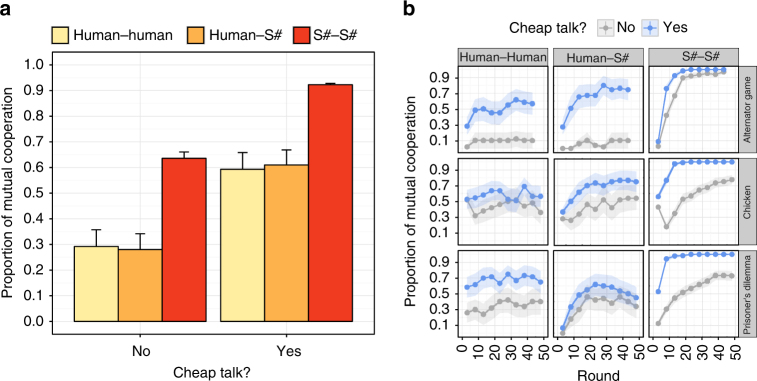
Since Alan Turing envisioned artificial intelligence, technical progress has often been measured by the ability to defeat humans in zero-sum encounters (e.g., Chess, Poker, or Go). Less attention has been given to scenarios in which human-machine cooperation is beneficial but non-trivial, such as scenarios in which human and machine preferences are neither fully aligned nor fully in conflict. Cooperation does not require sheer computational power, but instead is facilitated by intuition, cultural norms, emotions, signals, and pre-evolved dispositions. Here, we develop an algorithm that combines a state-of-the-art reinforcement-learning algorithm with mechanisms for signaling. We show that this algorithm can cooperate with people and other algorithms at levels that rival human cooperation in a variety of two-player repeated stochastic games. These results indicate that general human-machine cooperation is achievable using a non-trivial, but ultimately simple, set of algorithmic mechanisms.
Conflict of interest statement
The authors declare no competing financial interests.
Figures
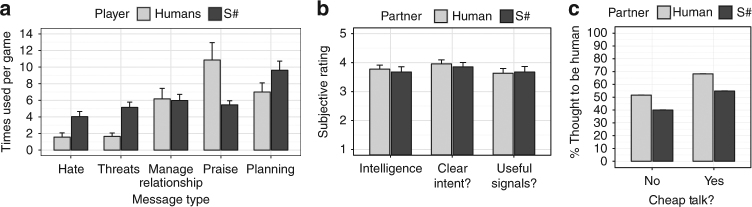
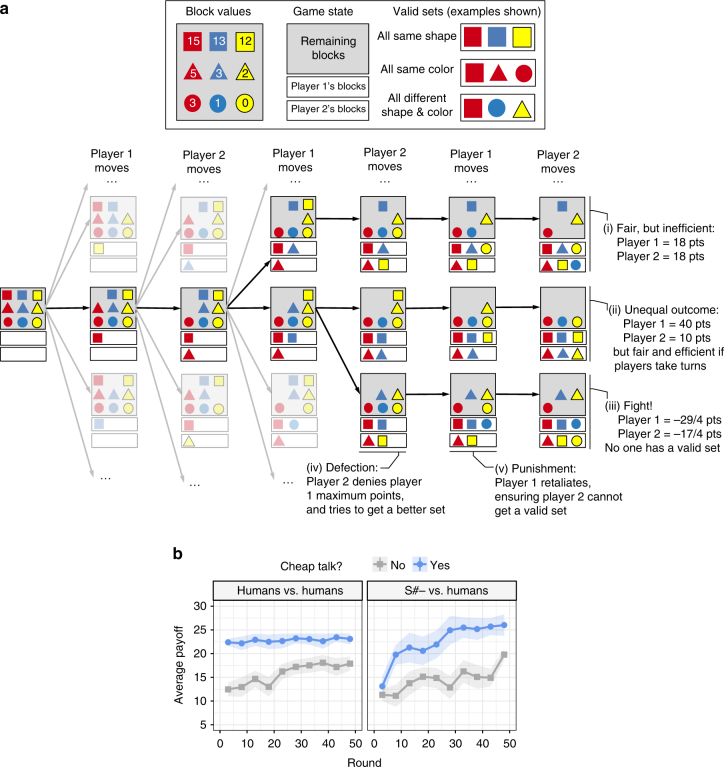
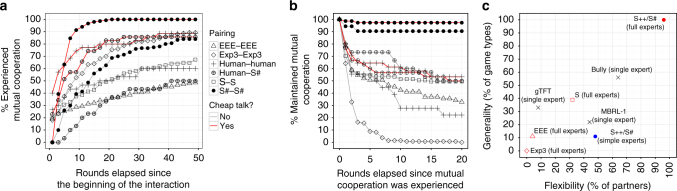
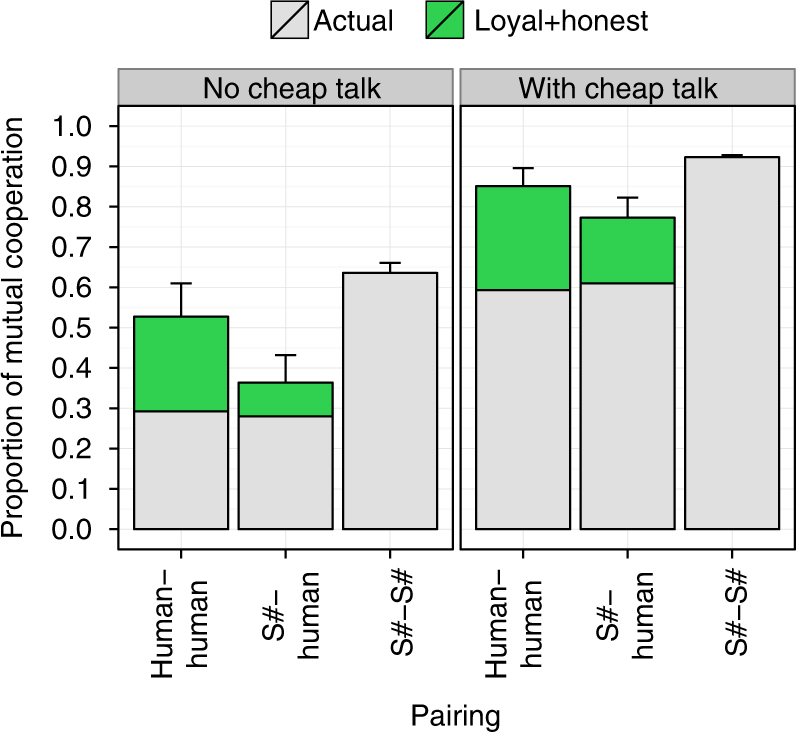
References
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
