

Systematic Dissection of Sequence Elements Controlling σ70 Promoters Using a Genomically Encoded Multiplexed Reporter Assay in Escherichia coli
- PMID: 29388765
- PMCID: PMC6389444
- DOI: 10.1021/acs.biochem.7b01069
Systematic Dissection of Sequence Elements Controlling σ70 Promoters Using a Genomically Encoded Multiplexed Reporter Assay in Escherichia coli
Abstract
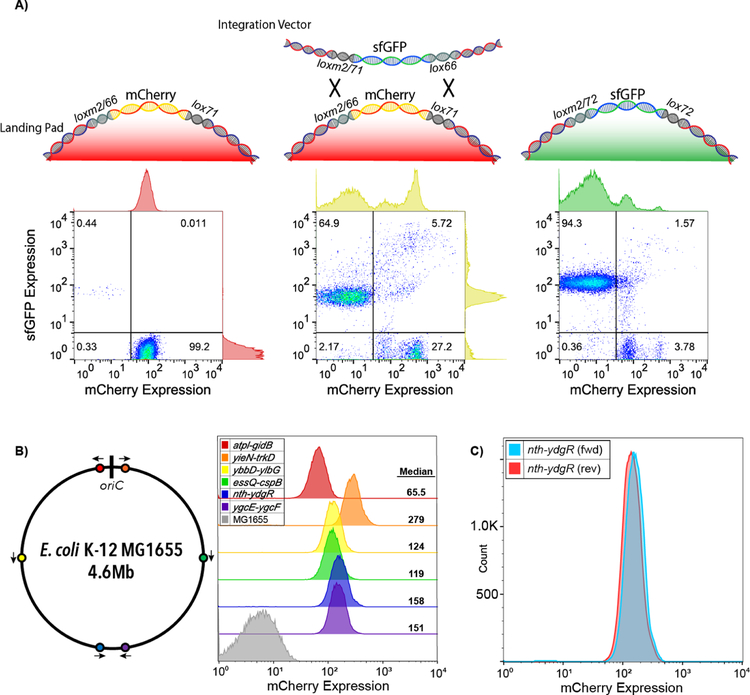
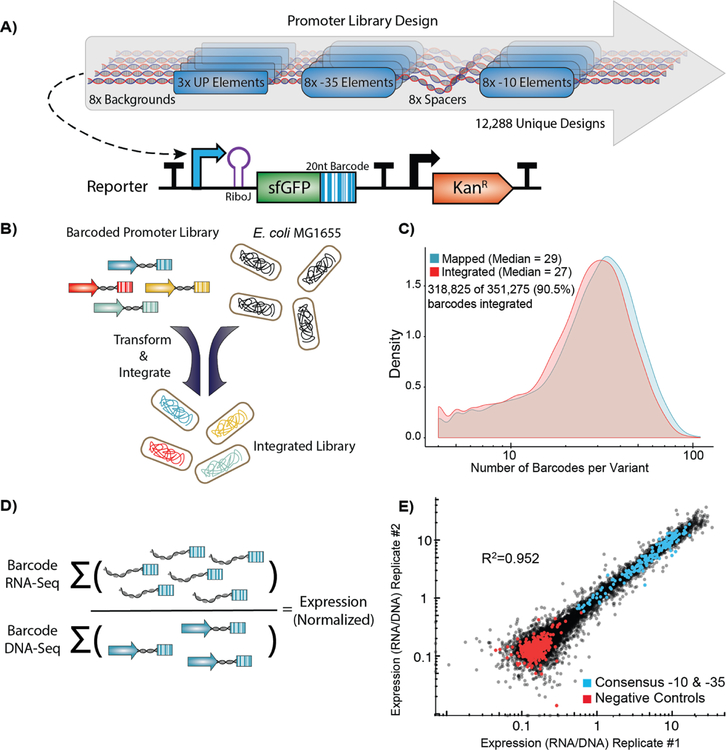
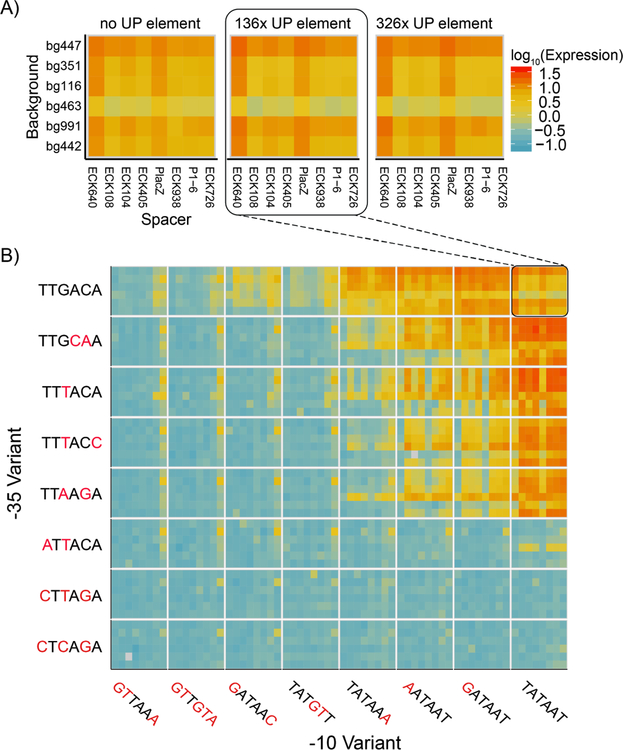
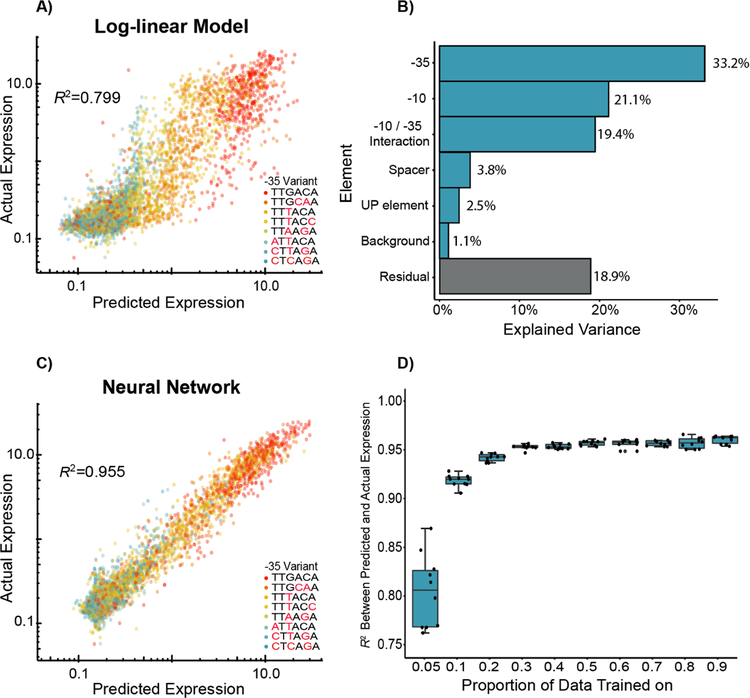
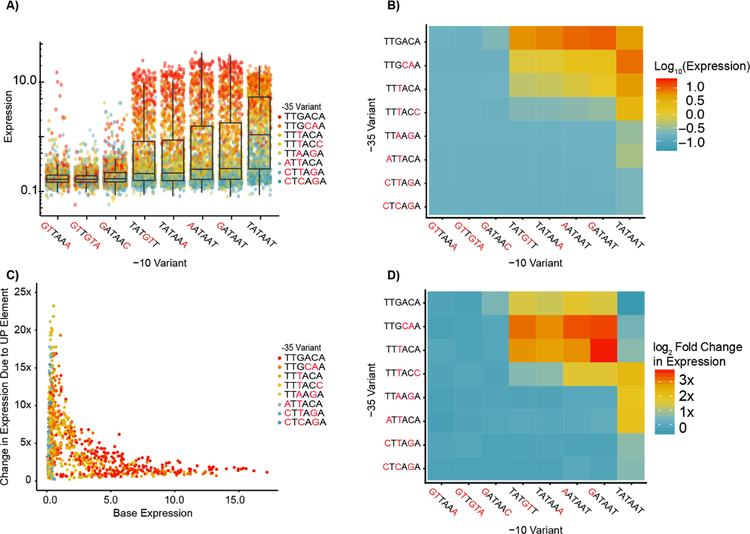
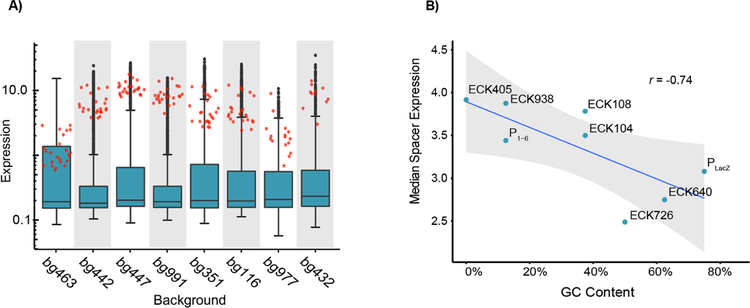
Promoters are the key drivers of gene expression and are largely responsible for the regulation of cellular responses to time and environment. In Escherichia coli, decades of studies have revealed most, if not all, of the sequence elements necessary to encode promoter function. Despite our knowledge of these motifs, it is still not possible to predict the strength and regulation of a promoter from primary sequence alone. Here we develop a novel multiplexed assay to study promoter function in E. coli by building a site-specific genomic recombination-mediated cassette exchange system that allows for the facile construction and testing of large libraries of genetic designs integrated into precise genomic locations. We build and test a library of 10898 σ70 promoter variants consisting of all combinations of a set of eight -35 elements, eight -10 elements, three UP elements, eight spacers, and eight backgrounds. We find that the -35 and -10 sequence elements can explain approximately 74% of the variance in promoter strength within our data set using a simple log-linear statistical model. Simple neural network models explain >95% of the variance in our data set by capturing nonlinear interactions with the spacer, background, and UP elements.
Figures
References
-
- Browning DF, and Busby SJW (2016) Local and global regulation of transcription initiation in bacteria. Nat. Rev. Microbiol 14, 638–650. - PubMed
-
- Feklístov A, Sharon BD, Darst SA, and Gross CA (2014) Bacterial Sigma Factors: A Historical, Structural, and Genomic Perspective. Annu. Rev. Microbiol 68, 357–376. - PubMed
-
- Gruber TM, and Gross CA (2003) Multiple sigma subunits and the partitioning of bacterial transcription space. Annu. Rev. Microbiol 57, 441–466. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
Research Materials
