

Random Forest Missing Data Algorithms
- PMID: 29403567
- PMCID: PMC5796790
- DOI: 10.1002/sam.11348
Random Forest Missing Data Algorithms
Abstract
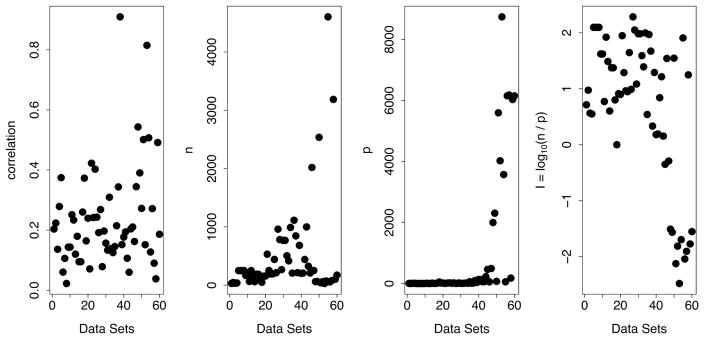
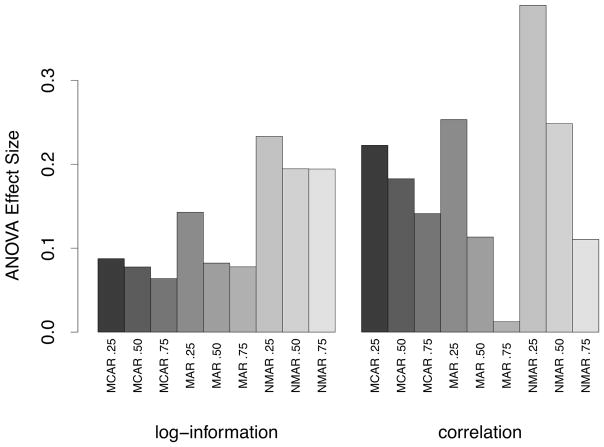
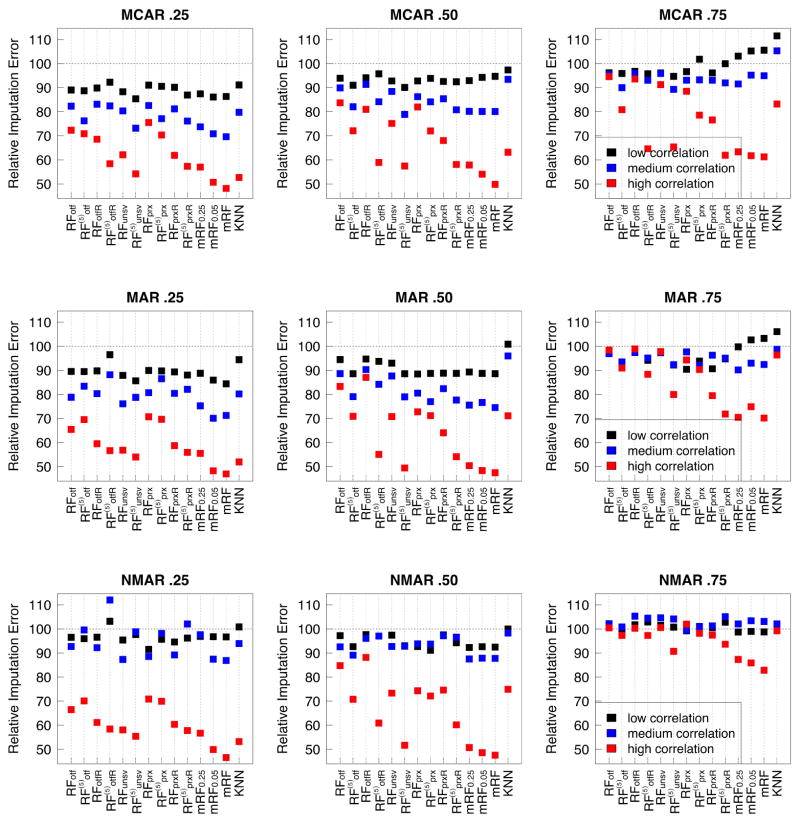
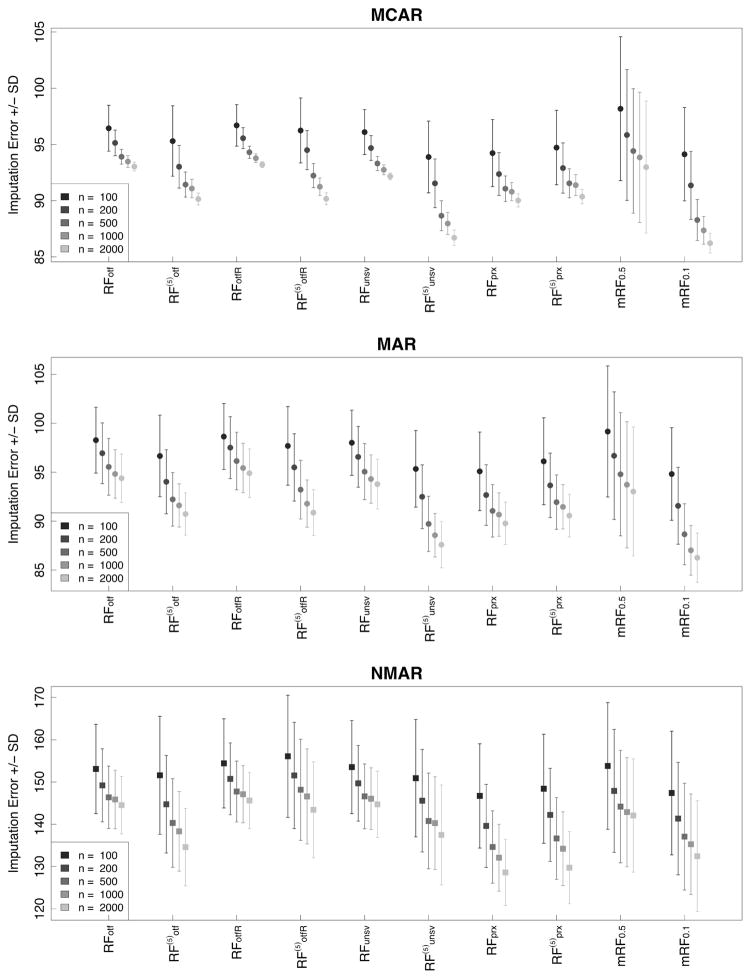
Random forest (RF) missing data algorithms are an attractive approach for imputing missing data. They have the desirable properties of being able to handle mixed types of missing data, they are adaptive to interactions and nonlinearity, and they have the potential to scale to big data settings. Currently there are many different RF imputation algorithms, but relatively little guidance about their efficacy. Using a large, diverse collection of data sets, imputation performance of various RF algorithms was assessed under different missing data mechanisms. Algorithms included proximity imputation, on the fly imputation, and imputation utilizing multivariate unsupervised and supervised splitting-the latter class representing a generalization of a new promising imputation algorithm called missForest. Our findings reveal RF imputation to be generally robust with performance improving with increasing correlation. Performance was good under moderate to high missingness, and even (in certain cases) when data was missing not at random.
Keywords: Correlation; Imputation; Machine Learning; Missingness; Splitting (random; multivariate; univariate; unsupervised).
Figures
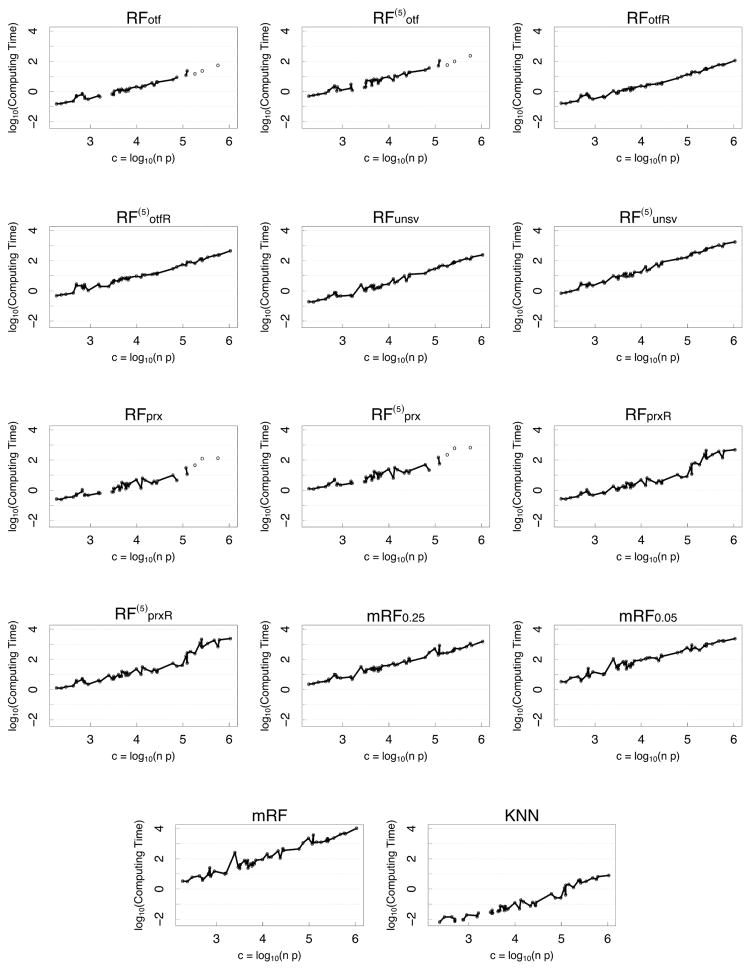
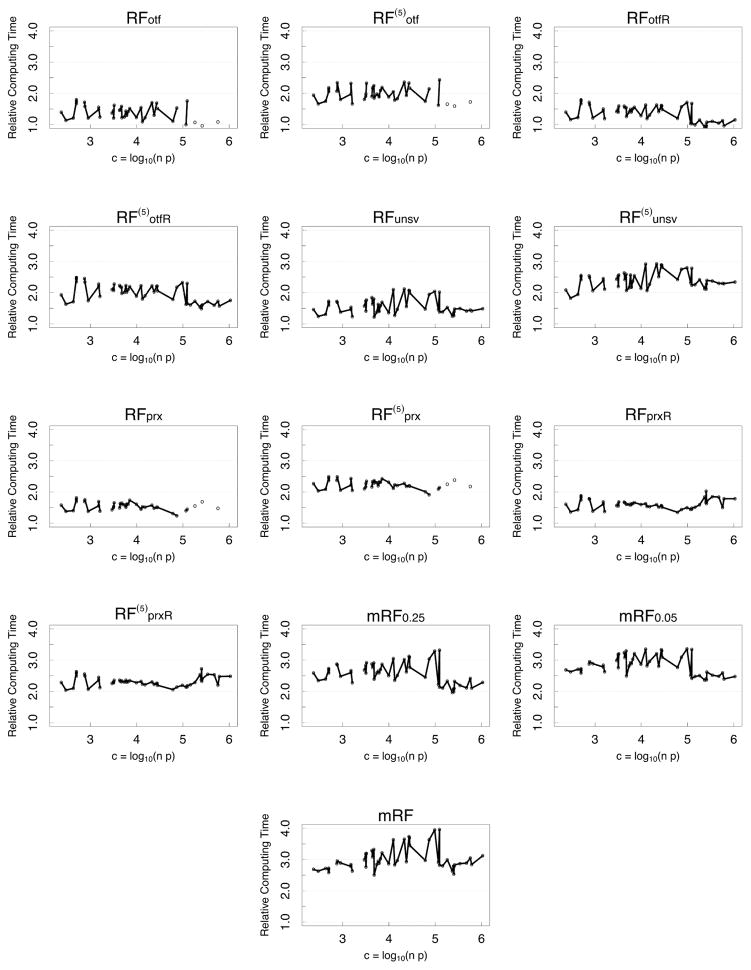
References
-
- Enders CK. Applied Missing Data Analysis. Guilford Publications; New York: 2010.
-
- Rubin DB. Multiple imputation after 18+ years. J Am Stat Assoc. 1996;91:473–489.
-
- Loh PL, Wainwright MJ. Advances in Neural Information Processing Systems. 2011. High-dimensional regression with noisy and missing data: provable guarantees with non-convexity; pp. 2726–2734.
-
- Aittokallio T. Dealing with missing values in large-scale studies: microarray data imputation and beyond. Brief Bioinform. 2009;2(2):253–264. - PubMed
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources