

Biosignature Discovery for Substance Use Disorders Using Statistical Learning
- PMID: 29409736
- PMCID: PMC5836808
- DOI: 10.1016/j.molmed.2017.12.008
Biosignature Discovery for Substance Use Disorders Using Statistical Learning
Abstract
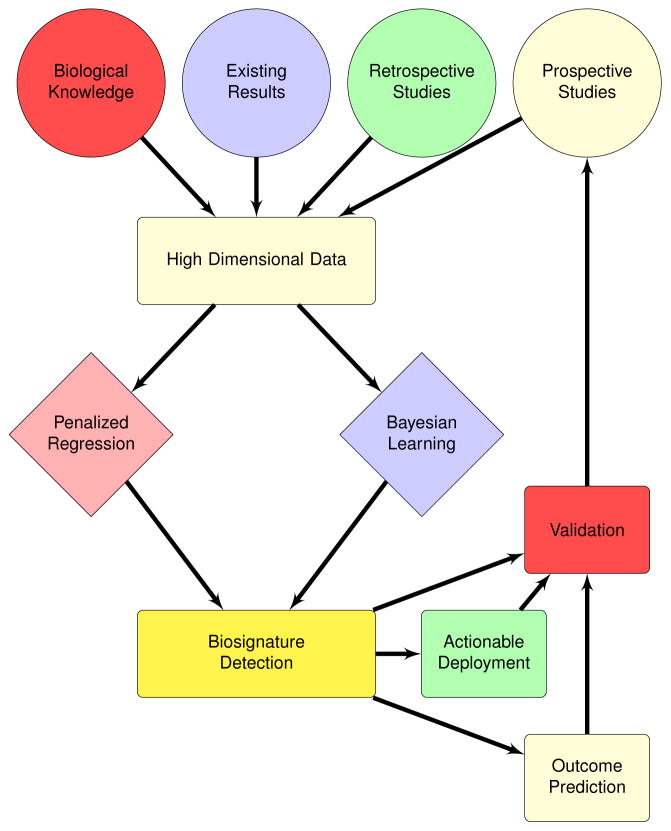
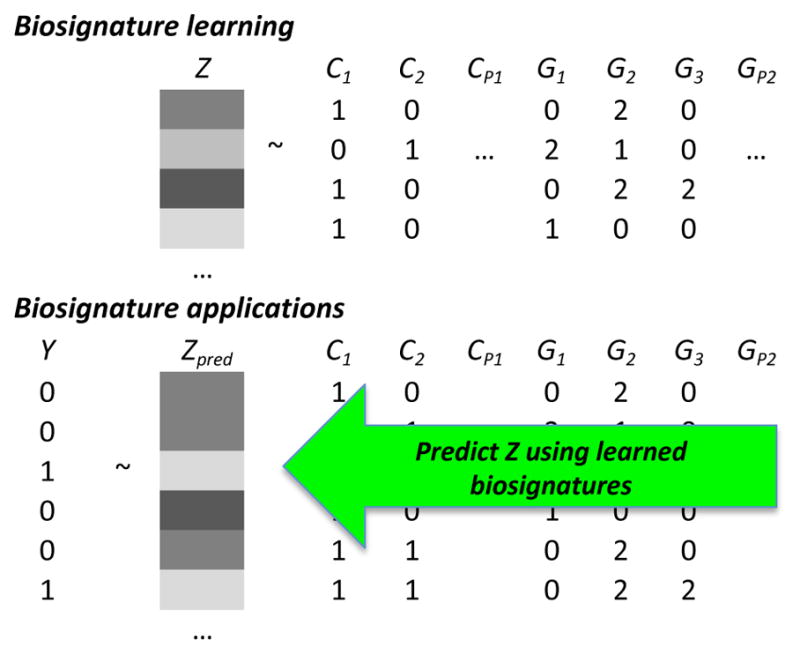
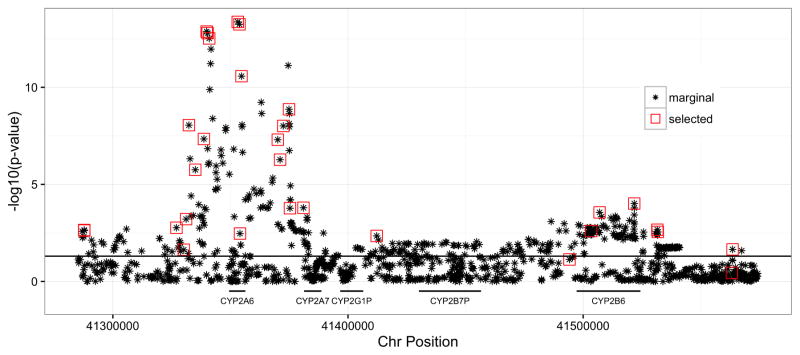
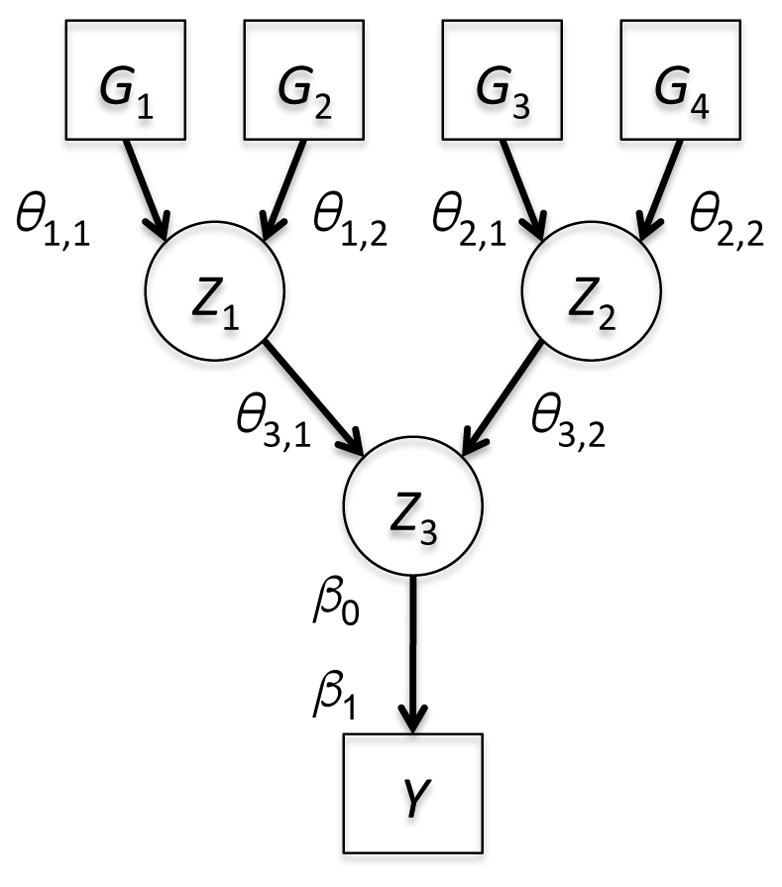
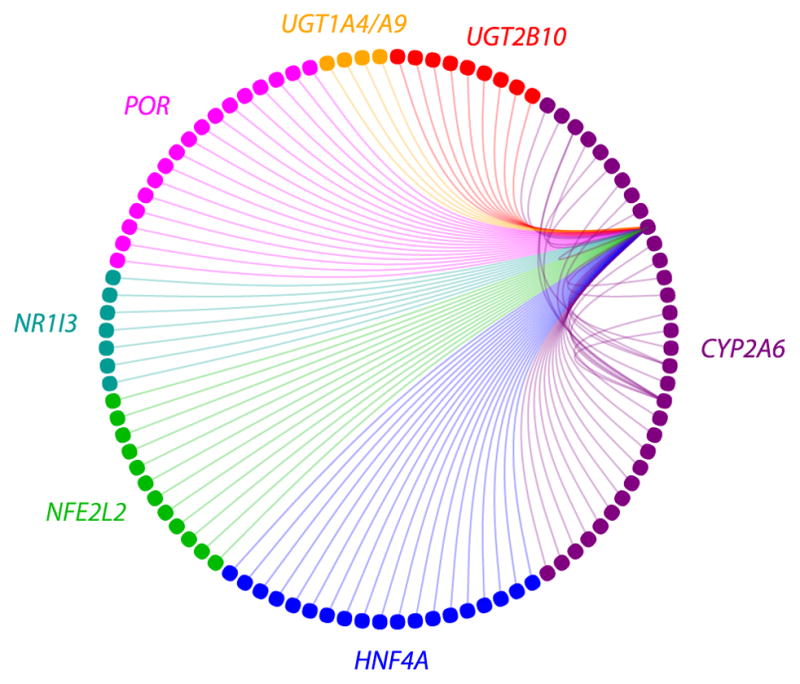
There are limited biomarkers for substance use disorders (SUDs). Traditional statistical approaches are identifying simple biomarkers in large samples, but clinical use cases are still being established. High-throughput clinical, imaging, and 'omic' technologies are generating data from SUD studies and may lead to more sophisticated and clinically useful models. However, analytic strategies suited for high-dimensional data are not regularly used. We review strategies for identifying biomarkers and biosignatures from high-dimensional data types. Focusing on penalized regression and Bayesian approaches, we address how to leverage evidence from existing studies and knowledge bases, using nicotine metabolism as an example. We posit that big data and machine learning approaches will considerably advance SUD biomarker discovery. However, translation to clinical practice, will require integrated scientific efforts.
Keywords: artificial intelligence; biomarker; genomics; machine learning; nicotine metabolism; substance use disorders.
Copyright © 2017 Elsevier Ltd. All rights reserved.
Figures

References
-
- Boscolo-Berto R, Viel G, Montisci M, Terranova C, Favretto D, Ferrara SD. Ethyl glucuronide concentration in hair for detecting heavy drinking and/or abstinence: a meta-analysis. Int J Legal Med. 2013;127(3):611–619. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
