

Network analysis of coronary artery disease risk genes elucidates disease mechanisms and druggable targets
- PMID: 29467471
- PMCID: PMC5821758
- DOI: 10.1038/s41598-018-20721-6
Network analysis of coronary artery disease risk genes elucidates disease mechanisms and druggable targets
Abstract
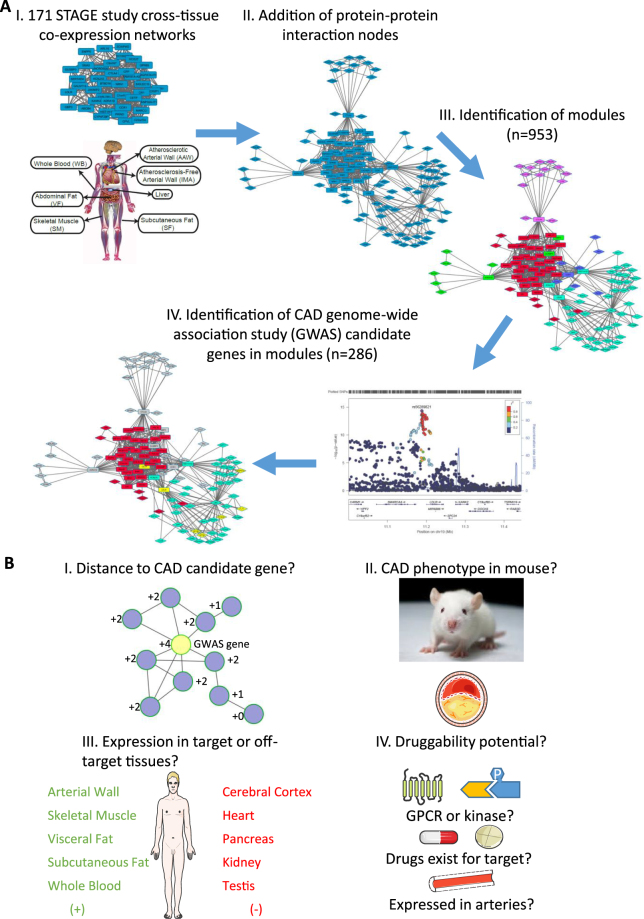
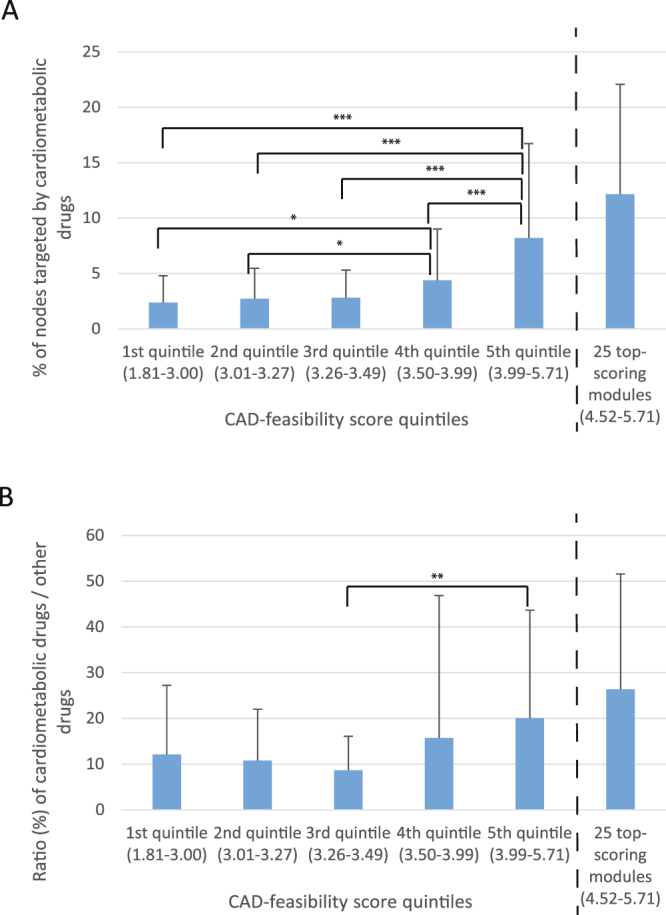
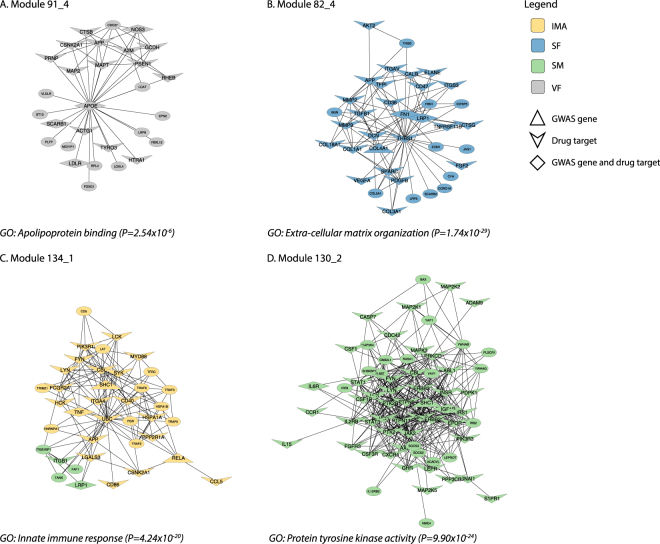
Genome-wide association studies (GWAS) have identified over two hundred chromosomal loci that modulate risk of coronary artery disease (CAD). The genes affected by variants at these loci are largely unknown and an untapped resource to improve our understanding of CAD pathophysiology and identify potential therapeutic targets. Here, we prioritized 68 genes as the most likely causal genes at genome-wide significant loci identified by GWAS of CAD and examined their regulatory roles in 286 metabolic and vascular tissue gene-protein sub-networks ("modules"). The modules and genes within were scored for CAD druggability potential. The scoring enriched for targets of cardiometabolic drugs currently in clinical use and in-depth analysis of the top-scoring modules validated established and revealed novel target tissues, biological processes, and druggable targets. This study provides an unprecedented resource of tissue-defined gene-protein interactions directly affected by genetic variance in CAD risk loci.
Conflict of interest statement
Harri Lempiäinen is an employee and shareholder of Genedata AG. Johannes Eichner, Claudia Biegert and Timo Wittenberger are employees of Genedata AG. Dr. Bjorkegren and Dr. Michoel are consultants and shareholders in Clinical Gene Networks AB (CGN). Dr. Franzen is part-time employee of CGN. Dr. Björkegren is also chairman of the board of directors in CGN. TRW and NJS are funded by the British Heart Foundation and SEH and NJS by the UK National Institute for Health Research.
Figures
References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
Miscellaneous
