

Characterizing and Managing Missing Structured Data in Electronic Health Records: Data Analysis
- PMID: 29475824
- PMCID: PMC5845101
- DOI: 10.2196/medinform.8960
Characterizing and Managing Missing Structured Data in Electronic Health Records: Data Analysis
Abstract
Background: Missing data is a challenge for all studies; however, this is especially true for electronic health record (EHR)-based analyses. Failure to appropriately consider missing data can lead to biased results. While there has been extensive theoretical work on imputation, and many sophisticated methods are now available, it remains quite challenging for researchers to implement these methods appropriately. Here, we provide detailed procedures for when and how to conduct imputation of EHR laboratory results.
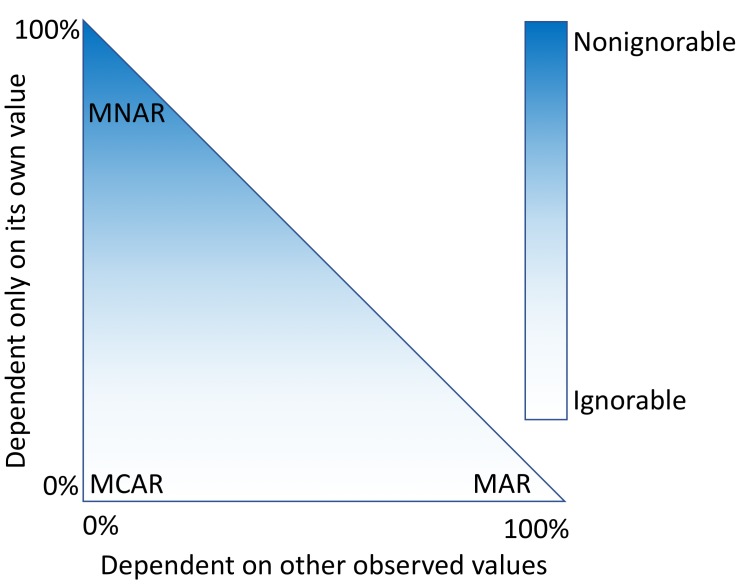
Objective: The objective of this study was to demonstrate how the mechanism of missingness can be assessed, evaluate the performance of a variety of imputation methods, and describe some of the most frequent problems that can be encountered.
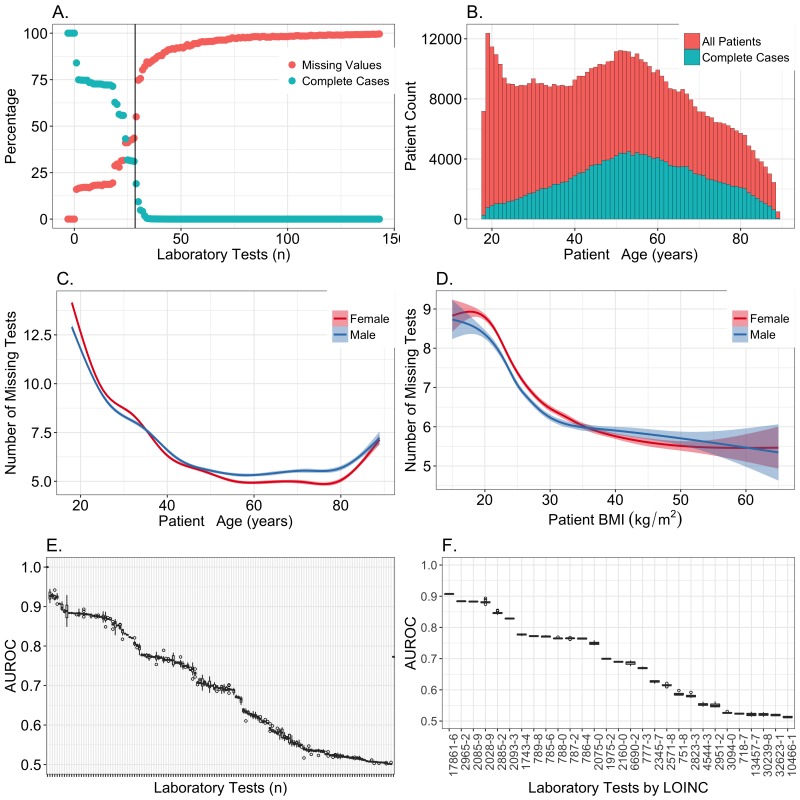
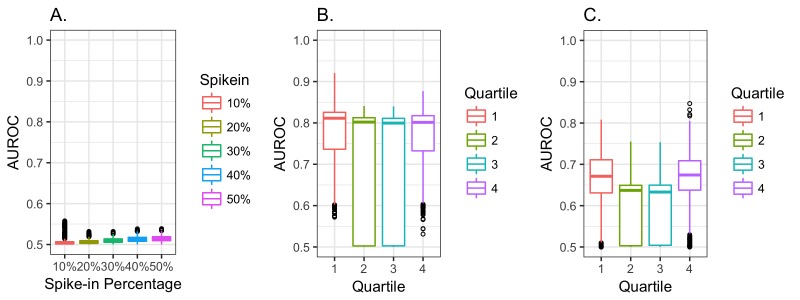
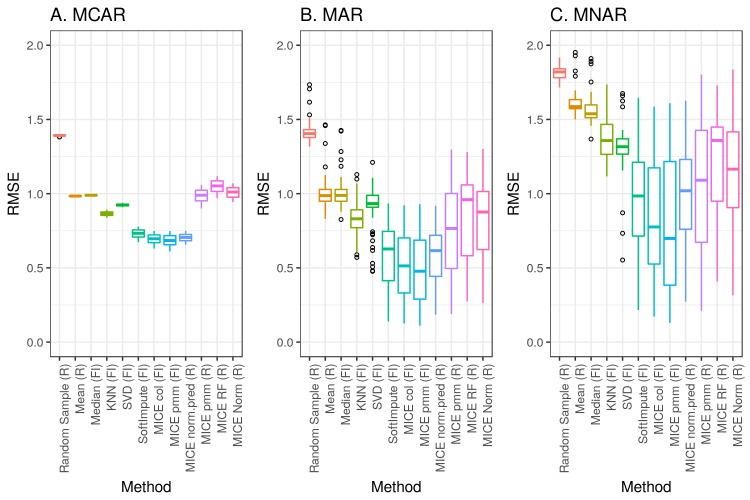
Methods: We analyzed clinical laboratory measures from 602,366 patients in the EHR of Geisinger Health System in Pennsylvania, USA. Using these data, we constructed a representative set of complete cases and assessed the performance of 12 different imputation methods for missing data that was simulated based on 4 mechanisms of missingness (missing completely at random, missing not at random, missing at random, and real data modelling).
Results: Our results showed that several methods, including variations of Multivariate Imputation by Chained Equations (MICE) and softImpute, consistently imputed missing values with low error; however, only a subset of the MICE methods was suitable for multiple imputation.
Conclusions: The analyses we describe provide an outline of considerations for dealing with missing EHR data, steps that researchers can perform to characterize missingness within their own data, and an evaluation of methods that can be applied to impute clinical data. While the performance of methods may vary between datasets, the process we describe can be generalized to the majority of structured data types that exist in EHRs, and all of our methods and code are publicly available.
Keywords: clinical laboratory test results; electronic health records; imputation; missing data.
©Brett K Beaulieu-Jones, Daniel R Lavage, John W Snyder, Jason H Moore, Sarah A Pendergrass, Christopher R Bauer. Originally published in JMIR Medical Informatics (http://medinform.jmir.org), 23.02.2018.
Conflict of interest statement
Conflicts of Interest: None declared.
Figures
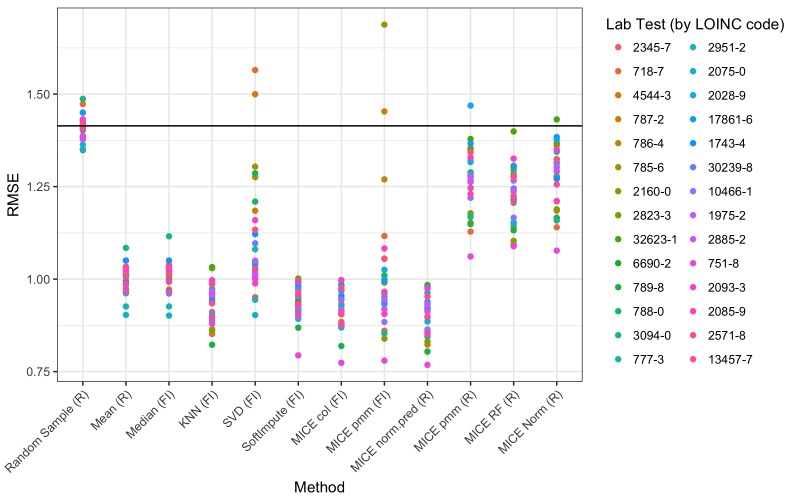
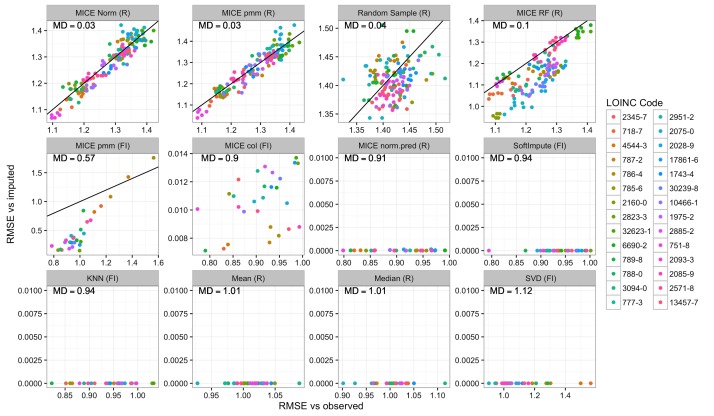
References
-
- Wells BJ, Chagin KM, Nowacki AS, Kattan MW. Strategies for handling missing data in electronic health record derived data. EGEMS (Wash DC) 2013;1(3):1035. doi: 10.13063/2327-9214.1035. http://europepmc.org/abstract/MED/25848578 - DOI - PMC - PubMed
-
- Bhaskaran K, Smeeth L. What is the difference between missing completely at random and missing at random? Int J Epidemiol. 2014 Aug;43(4):1336–9. doi: 10.1093/ije/dyu080. http://europepmc.org/abstract/MED/24706730 - DOI - PMC - PubMed
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
