

Horizontal transfer of code fragments between protocells can explain the origins of the genetic code without vertical descent
- PMID: 29476089
- PMCID: PMC5824800
- DOI: 10.1038/s41598-018-21973-y
Horizontal transfer of code fragments between protocells can explain the origins of the genetic code without vertical descent
Abstract
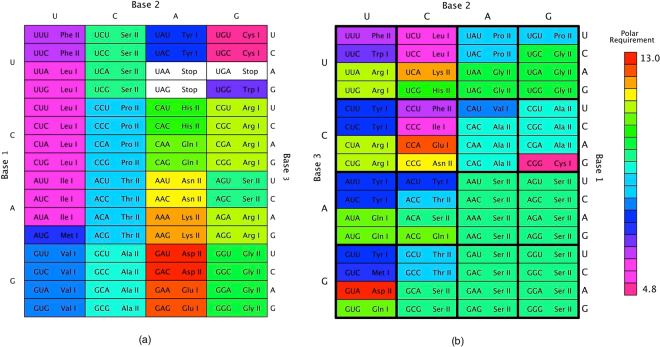
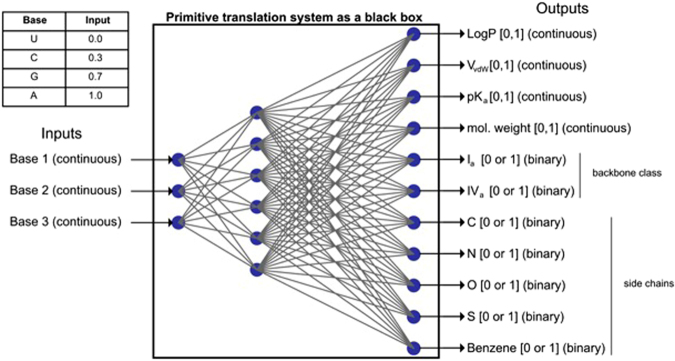
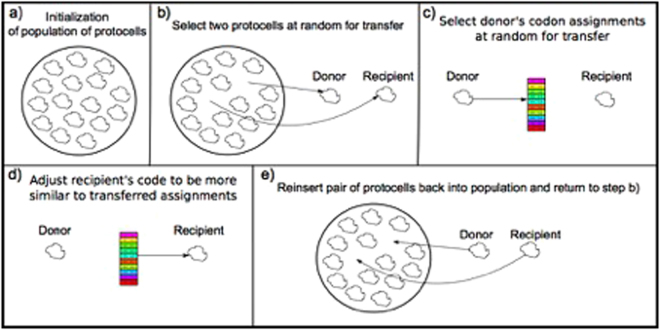
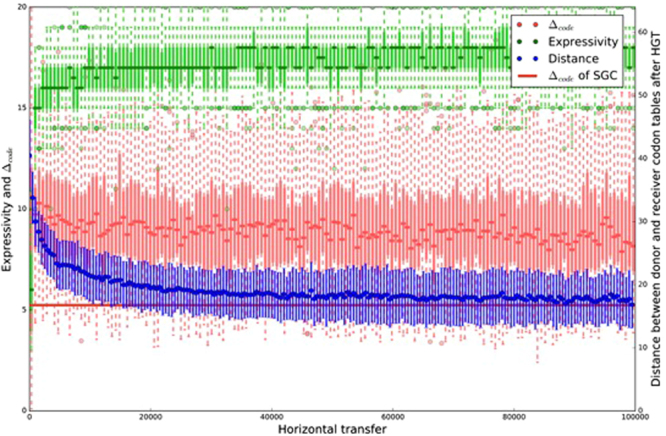
Theories of the origin of the genetic code typically appeal to natural selection and/or mutation of hereditable traits to explain its regularities and error robustness, yet the present translation system presupposes high-fidelity replication. Woese's solution to this bootstrapping problem was to assume that code optimization had played a key role in reducing the effect of errors caused by the early translation system. He further conjectured that initially evolution was dominated by horizontal exchange of cellular components among loosely organized protocells ("progenotes"), rather than by vertical transmission of genes. Here we simulated such communal evolution based on horizontal transfer of code fragments, possibly involving pairs of tRNAs and their cognate aminoacyl tRNA synthetases or a precursor tRNA ribozyme capable of catalysing its own aminoacylation, by using an iterated learning model. This is the first model to confirm Woese's conjecture that regularity, optimality, and (near) universality could have emerged via horizontal interactions alone.
Conflict of interest statement
The authors declare no competing interests.
Figures
References
-
- Koonin, E. V. & Novozhilov, A. S. Origin and evolution of the universal genetic code. Annu. Rev. Genet. 51 (2017). - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
