

Targeting IS608 transposon integration to highly specific sequences by structure-based transposon engineering
- PMID: 29635476
- PMCID: PMC5934647
- DOI: 10.1093/nar/gky235
Targeting IS608 transposon integration to highly specific sequences by structure-based transposon engineering
Abstract
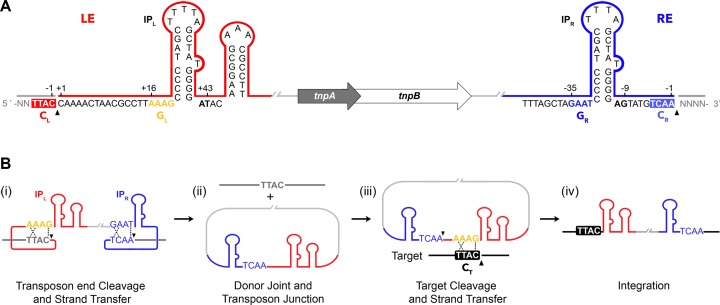
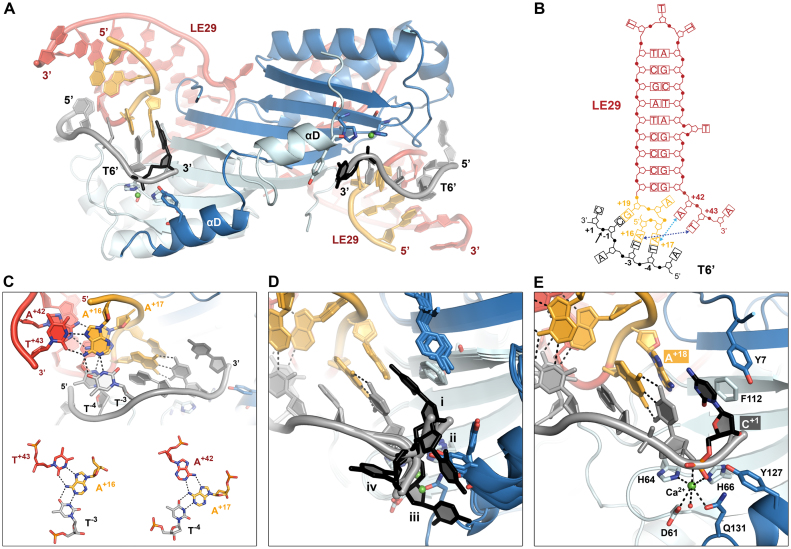
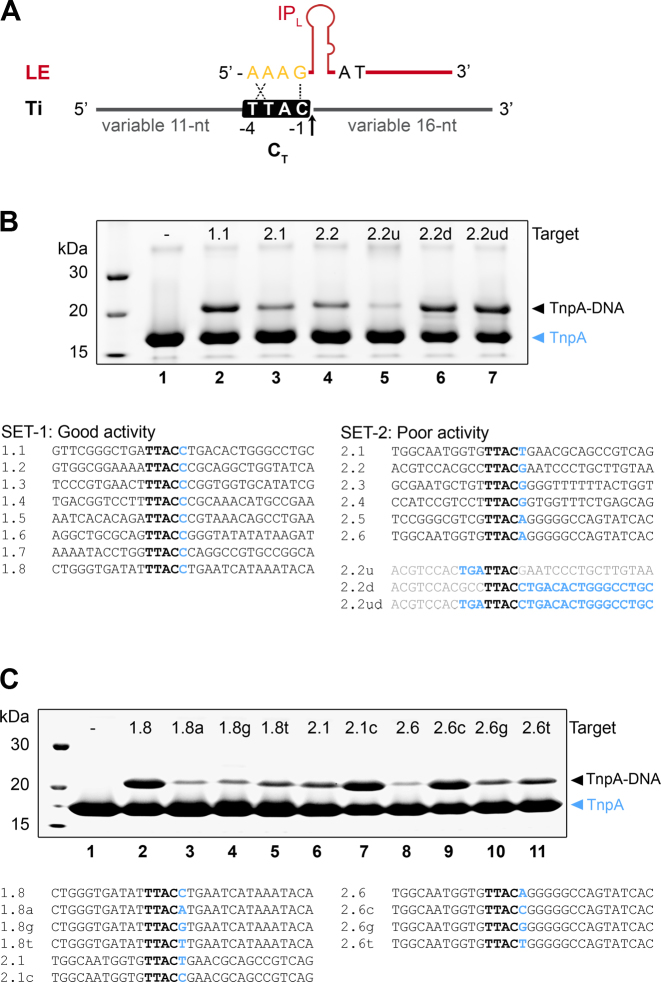
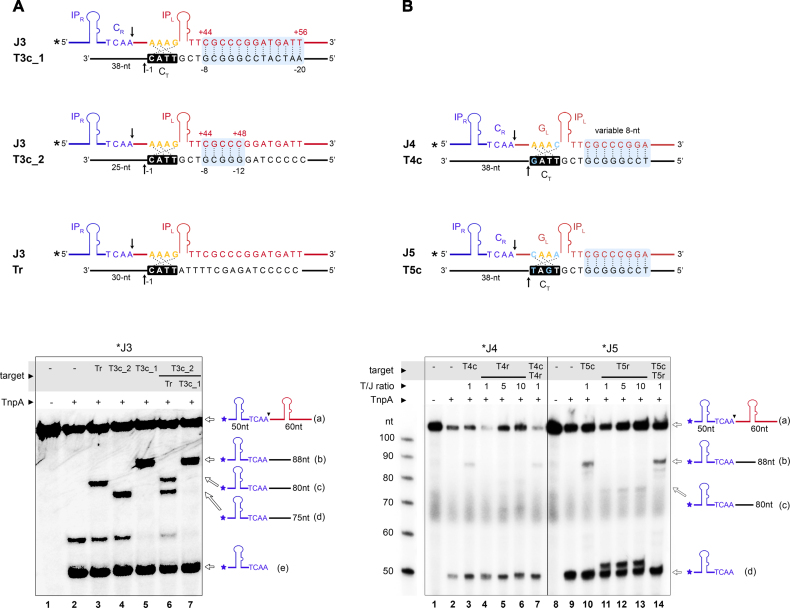
Transposable elements are efficient DNA carriers and thus important tools for transgenesis and insertional mutagenesis. However, their poor target sequence specificity constitutes an important limitation for site-directed applications. The insertion sequence IS608 from Helicobacter pylori recognizes a specific tetranucleotide sequence by base pairing, and its target choice can be re-programmed by changes in the transposon DNA. Here, we present the crystal structure of the IS608 target capture complex in an active conformation, providing a complete picture of the molecular interactions between transposon and target DNA prior to integration. Based on this, we engineered IS608 variants to direct their integration specifically to various 12/17-nt long target sites by extending the base pair interaction network between the transposon and the target DNA. We demonstrate in vitro that the engineered transposons efficiently select their intended target sites. Our data further elucidate how the distinct secondary structure of the single-stranded transposon intermediate prevents extended target specificity in the wild-type transposon, allowing it to move between diverse genomic sites. Our strategy enables efficient targeting of unique DNA sequences with high specificity in an easily programmable manner, opening possibilities for the use of the IS608 system for site-specific gene insertions.
Figures

References
-
- Lander E.S., Linton L.M., Birren B., Nusbaum C., Zody M.C., Baldwin J., Devon K., Dewar K., Doyle M., FitzHugh W. et al. . Initial sequencing and analysis of the human genome. Nature. 2001; 409:860–921. - PubMed
-
- Chain P.S., Carniel E., Larimer F.W., Lamerdin J., Stoutland P.O., Regala W.M., Georgescu A.M., Vergez L.M., Land M.L., Motin V.L. et al. . Insights into the evolution of Yersinia pestis through whole-genome comparison with Yersinia pseudotuberculosis. Proc. Natl. Acad. Sci. U.S.A. 2004; 101:13826–13831. - PMC - PubMed
-
- Curcio M.J., Derbyshire K.M.. The outs and ins of transposition: from mu to kangaroo. Nat. Rev. Mol. Cell Biol. 2003; 4:865–877. - PubMed
-
- Chen J.M., Stenson P.D., Cooper D.N., Ferec C.. A systematic analysis of LINE-1 endonuclease-dependent retrotranspositional events causing human genetic disease. Hum. Genet. 2005; 117:411–427. - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
