

In Silico Labeling: Predicting Fluorescent Labels in Unlabeled Images
- PMID: 29656897
- PMCID: PMC6309178
- DOI: 10.1016/j.cell.2018.03.040
In Silico Labeling: Predicting Fluorescent Labels in Unlabeled Images
Abstract
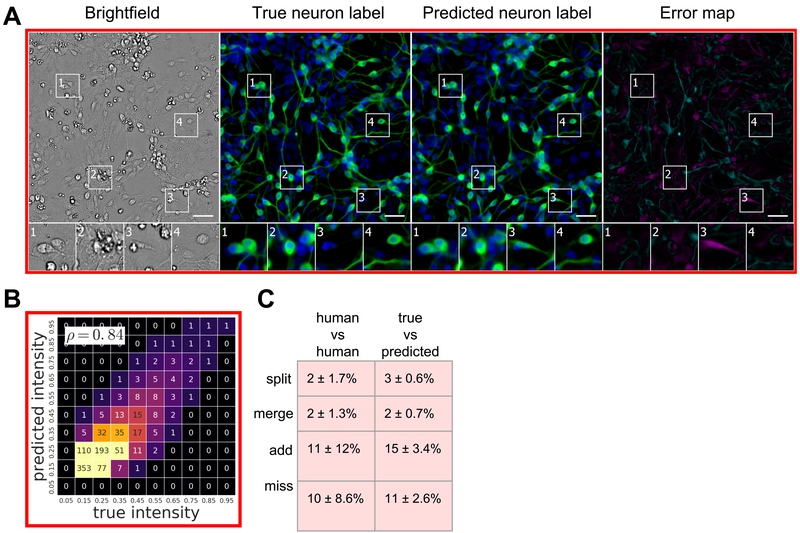
Microscopy is a central method in life sciences. Many popular methods, such as antibody labeling, are used to add physical fluorescent labels to specific cellular constituents. However, these approaches have significant drawbacks, including inconsistency; limitations in the number of simultaneous labels because of spectral overlap; and necessary perturbations of the experiment, such as fixing the cells, to generate the measurement. Here, we show that a computational machine-learning approach, which we call "in silico labeling" (ISL), reliably predicts some fluorescent labels from transmitted-light images of unlabeled fixed or live biological samples. ISL predicts a range of labels, such as those for nuclei, cell type (e.g., neural), and cell state (e.g., cell death). Because prediction happens in silico, the method is consistent, is not limited by spectral overlap, and does not disturb the experiment. ISL generates biological measurements that would otherwise be problematic or impossible to acquire.
Keywords: cancer; computer vision; deep learning; machine learning; microscopy; neuroscience; stem cells.
Copyright © 2018 Elsevier Inc. All rights reserved.
Conflict of interest statement
I asked every author of this work to declare any conflicts of interest.
Figures
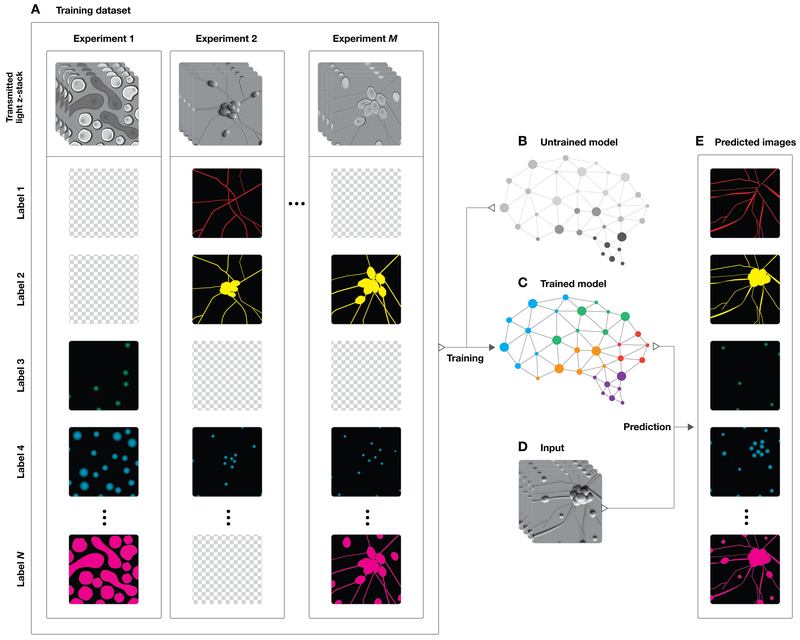

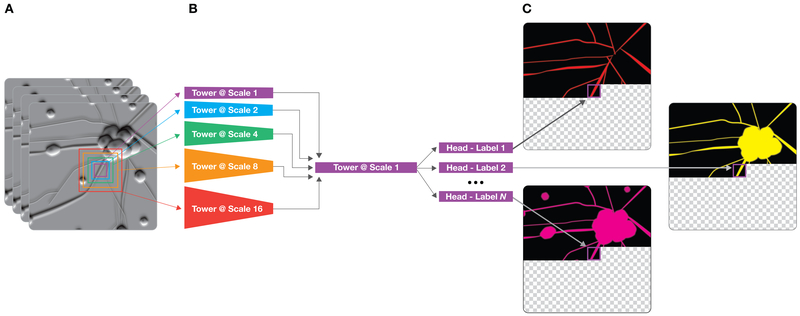
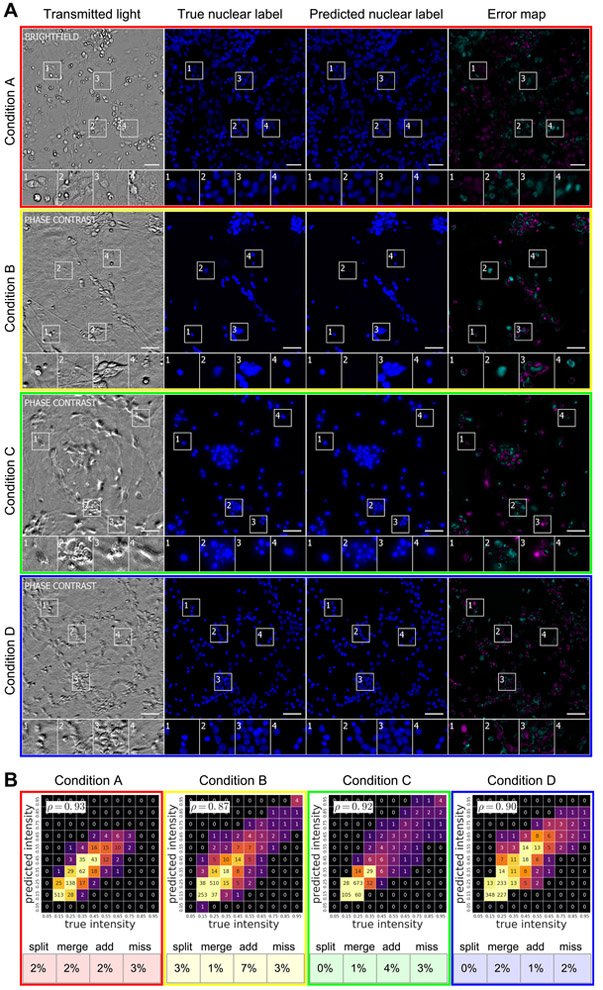
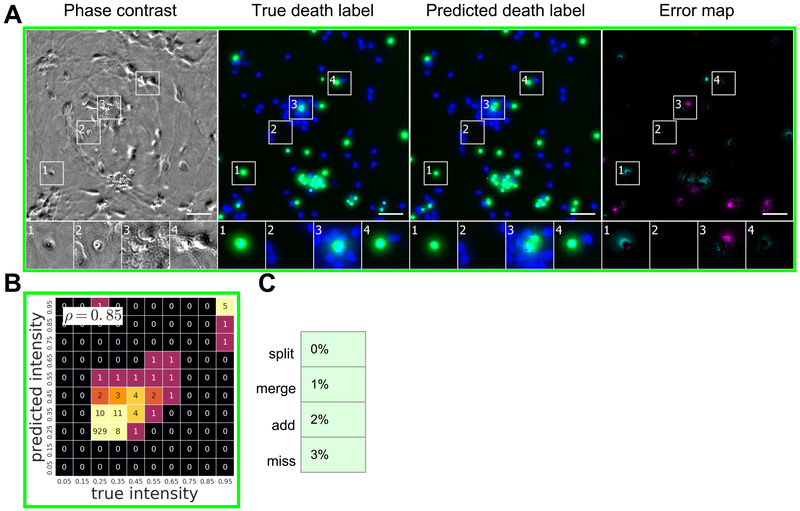
Comment in
-
Seeing More: A Future of Augmented Microscopy.Cell. 2018 Apr 19;173(3):546-548. doi: 10.1016/j.cell.2018.04.003. Cell. 2018. PMID: 29677507
References
-
- Abadi M, Agarwal A, Barham P, Brevdo E, Chen Z, Citro C, Corrado G, Davis A, Dean J, Devin M, et al. (2015). TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems.
-
- Arrasate M, Mitra S, Schweitzer ES, Segal MR, and Finkbeiner S (2004). Inclusion body formation reduces levels of mutant huntingtin and the risk of neuronal death. Nature 431, 805–810. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
Miscellaneous
