

Origins of scale invariance in vocalization sequences and speech
- PMID: 29659561
- PMCID: PMC5919684
- DOI: 10.1371/journal.pcbi.1005996
Origins of scale invariance in vocalization sequences and speech
Abstract
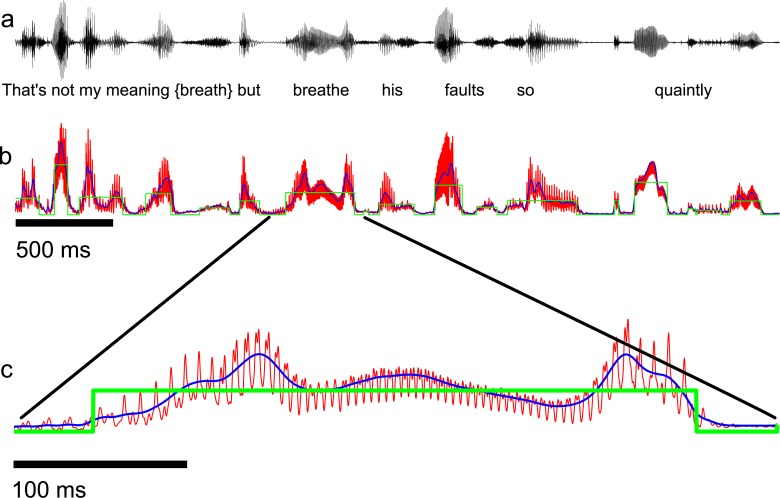
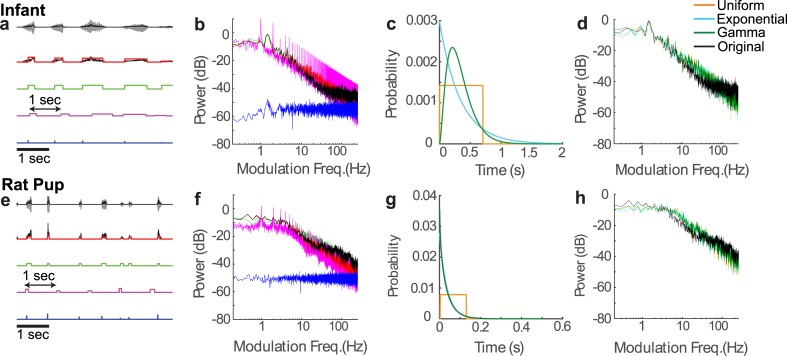
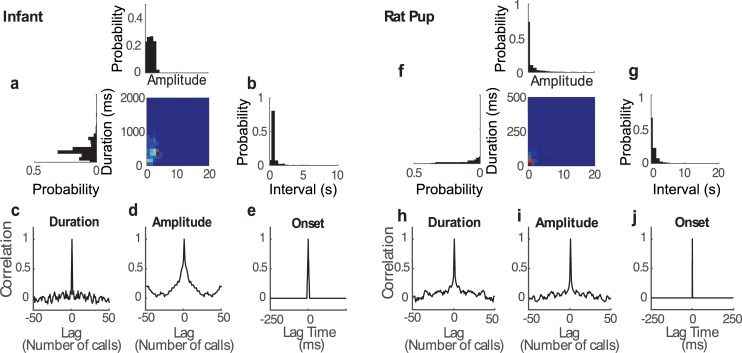
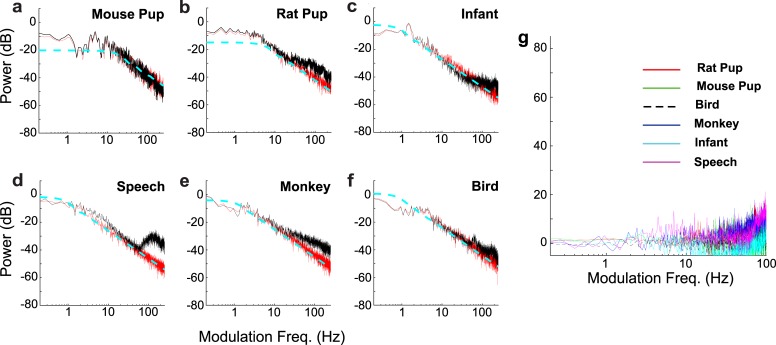
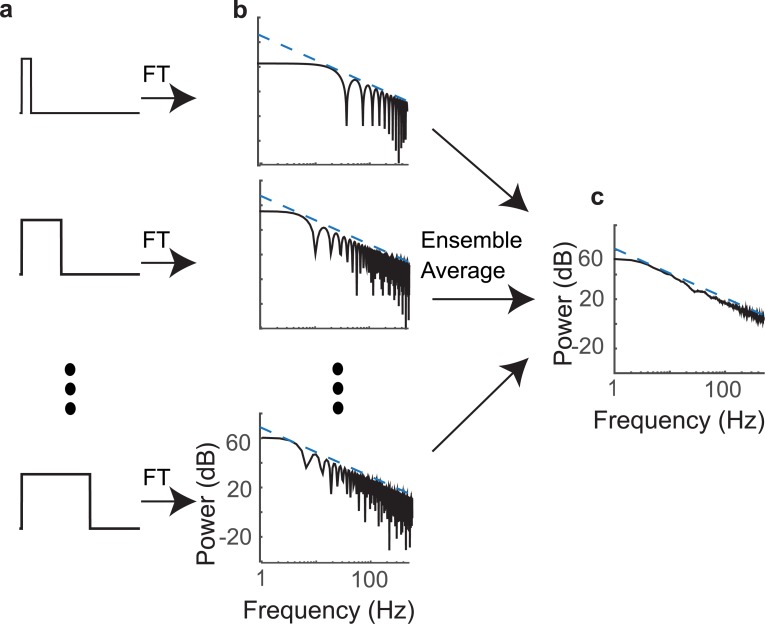
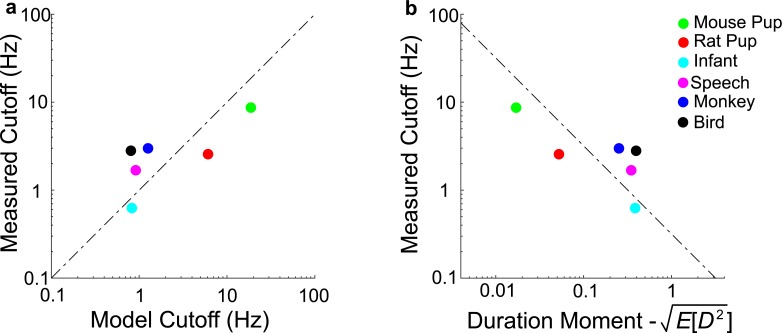
To communicate effectively animals need to detect temporal vocalization cues that vary over several orders of magnitude in their amplitude and frequency content. This large range of temporal cues is evident in the power-law scale-invariant relationship between the power of temporal fluctuations in sounds and the sound modulation frequency (f). Though various forms of scale invariance have been described for natural sounds, the origins and implications of scale invariant phenomenon remain unknown. Using animal vocalization sequences, including continuous human speech, and a stochastic model of temporal amplitude fluctuations we demonstrate that temporal acoustic edges are the primary acoustic cue accounting for the scale invariant phenomenon. The modulation spectrum of vocalization sequences and the model both exhibit a dual regime lowpass structure with a flat region at low modulation frequencies and scale invariant 1/f2 trend for high modulation frequencies. Moreover, we find a time-frequency tradeoff between the average vocalization duration of each vocalization sequence and the cutoff frequency beyond which scale invariant behavior is observed. These results indicate that temporal edges are universal features responsible for scale invariance in vocalized sounds. This is significant since temporal acoustic edges are salient perceptually and the auditory system could exploit such statistical regularities to minimize redundancies and generate compact neural representations of vocalized sounds.
Conflict of interest statement
No
Figures
References
-
- Barlow H. Possible principles underlying the transformation of sensory messages Sensory Communication: MIT Press; 1961.
-
- Ruderman DL, Bialek W. Statistics of natural images: Scaling in the woods. Physical Review Letters. 1994;73(6):814–7. doi: 10.1103/PhysRevLett.73.814 . - DOI - PubMed
-
- Field DJ. Relations between the statistics of natural images and the response properties of cortical cells. J Opt Soc Am A. 1987;4(12):2379–94. Epub 1987/12/01. . - PubMed
-
- Zylberberg J, Pfau D, Deweese MR. Dead leaves and the dirty ground: low-level image statistics in transmissive and occlusive imaging environments. Phys Rev E Stat Nonlin Soft Matter Phys. 2012;86(6 Pt 2):066112 doi: 10.1103/PhysRevE.86.066112 . - DOI - PubMed
-
- Hsiao WH, Millane RP. Effects of occlusion, edges, and scaling on the power spectra of natural images. J Opt Soc Am A Opt Image Sci Vis. 2005;22(9):1789–97. . - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
