

doi: 10.1038/nmeth.4526.
Points of Significance: Machine learning: a primer
Affiliations
- PMID: 29664466
- PMCID: PMC5905345
- DOI: 10.1038/nmeth.4526
Item in Clipboard
Points of Significance: Machine learning: a primer
Nat Methods.
.
Abstract
Machine learning extracts general principles from observed examples without explicit instructions.
Conflict of interest statement
The authors declare no competing financial interests.
Figures
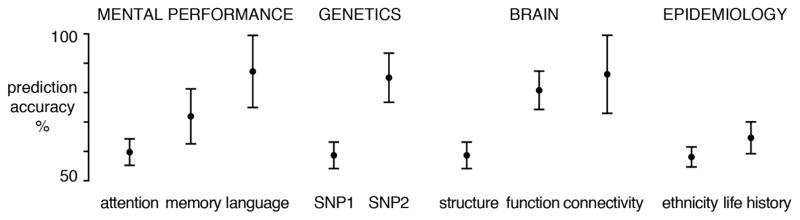
Probing the basis of a psychiatric disorder at multiple levels. Schematic of how psychological, genetic, neurobiological and epidemiological observations can be used to automatically learn the difference between healthy individuals and affected patients. For each type of measurement (e.g., attention test scores), a learning algorithm is trained on part of the data and subsequently evaluated on remaining test data from independent individuals to obtain prediction performance estimates (50% accuracy corresponds to random guessing). The statistical uncertainty of the prediction accuracies is shown by 95% confidence intervals obtained from bootstrap resampling of data points with replacement.
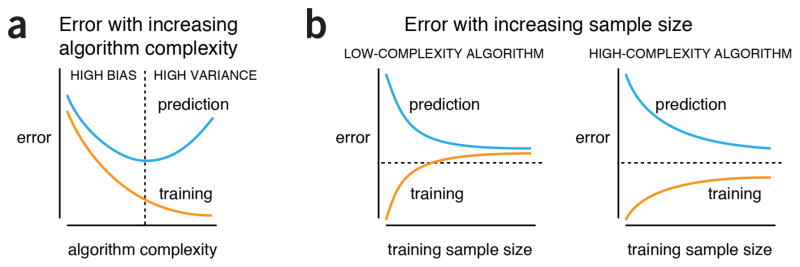
General behaviors of machine-learning algorithms. (a) When algorithm complexity is low, both prediction on new data (“prediction error”) and failed model evaluation on the training data (“training error”) are high. In this high-bias regime, prediction is poor because the algorithm has a tendency to underfit structure in the data. As algorithm complexity increases, both errors drop but eventually prediction error rises again. The algorithm enters the high-variance regime, where it starts to overfit. (b) As training sample size increases, for a fixed level of algorithm complexity, prediction error drops and training error increases. This trend is more pronounced for low-complexity algorithms, such as logistic regression or linear regression, which have a limited capacity to improve with additional data. High-complexity algorithms, such as high-order polynomials, CART, or (deep) neural networks, on the other hand, continue to improve on the test data but their predictive performance is still limited by sources of noise. In this practical example, the low-complexity example could benefit from a more flexible algorithm and the high-complexity example from more data. The three dashed lines show a hypothetical desired error level.
References
-
- Jordan MI, Mitchell TM. Science. 2015;349:255–260. - PubMed
-
- Abu-Mostafa YS, Magdon-Ismail M, Lin HT. AMLBook; California: 2012.
-
- Lever J, Krzywinski M, Altman N. Points of Significance: Model Selection and Overfitting. Nature Methods. 2016;13(9):703–704. doi: 10.1038/nmeth.3968. - DOI
-
- Hastie T, Tibshirani R, Friedman J. Springer Series in Statistics. Heidelberg: 2001.
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
