

BCDForest: a boosting cascade deep forest model towards the classification of cancer subtypes based on gene expression data
- PMID: 29671390
- PMCID: PMC5907304
- DOI: 10.1186/s12859-018-2095-4
BCDForest: a boosting cascade deep forest model towards the classification of cancer subtypes based on gene expression data
Abstract
Background: The classification of cancer subtypes is of great importance to cancer disease diagnosis and therapy. Many supervised learning approaches have been applied to cancer subtype classification in the past few years, especially of deep learning based approaches. Recently, the deep forest model has been proposed as an alternative of deep neural networks to learn hyper-representations by using cascade ensemble decision trees. It has been proved that the deep forest model has competitive or even better performance than deep neural networks in some extent. However, the standard deep forest model may face overfitting and ensemble diversity challenges when dealing with small sample size and high-dimensional biology data.
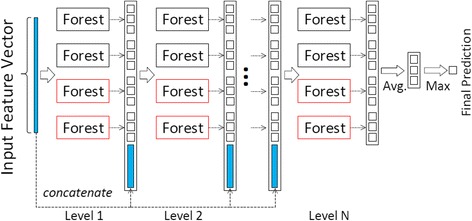
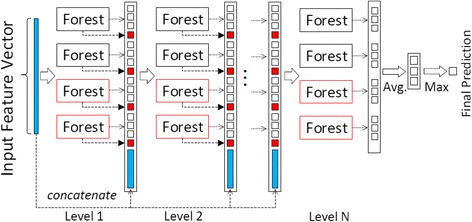
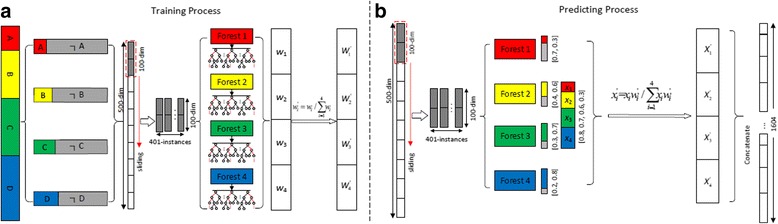
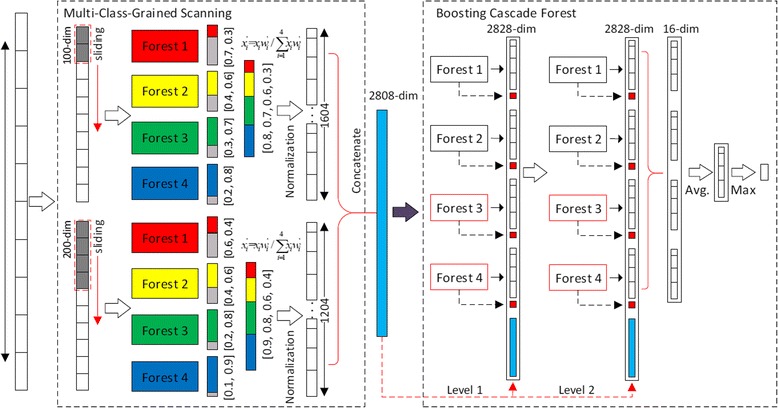
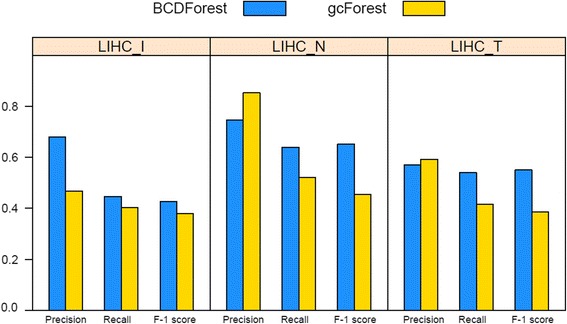
Results: In this paper, we propose a deep learning model, so-called BCDForest, to address cancer subtype classification on small-scale biology datasets, which can be viewed as a modification of the standard deep forest model. The BCDForest distinguishes from the standard deep forest model with the following two main contributions: First, a named multi-class-grained scanning method is proposed to train multiple binary classifiers to encourage diversity of ensemble. Meanwhile, the fitting quality of each classifier is considered in representation learning. Second, we propose a boosting strategy to emphasize more important features in cascade forests, thus to propagate the benefits of discriminative features among cascade layers to improve the classification performance. Systematic comparison experiments on both microarray and RNA-Seq gene expression datasets demonstrate that our method consistently outperforms the state-of-the-art methods in application of cancer subtype classification.
Conclusions: The multi-class-grained scanning and boosting strategy in our model provide an effective solution to ease the overfitting challenge and improve the robustness of deep forest model working on small-scale data. Our model provides a useful approach to the classification of cancer subtypes by using deep learning on high-dimensional and small-scale biology data.
Keywords: Cancer subtype; Cascade forest; Classification.
Conflict of interest statement
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Figures
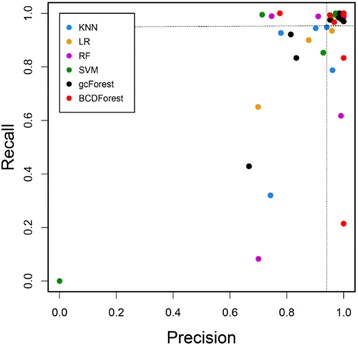
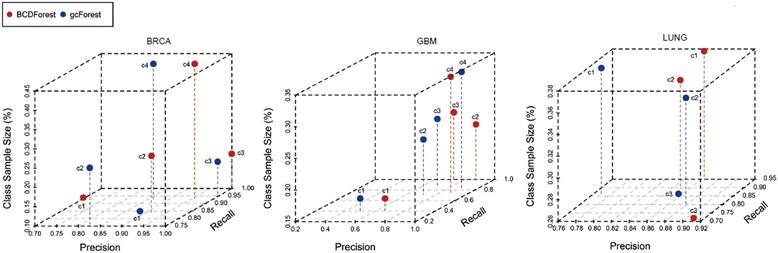
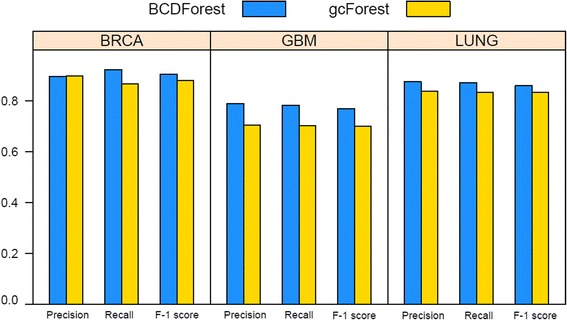
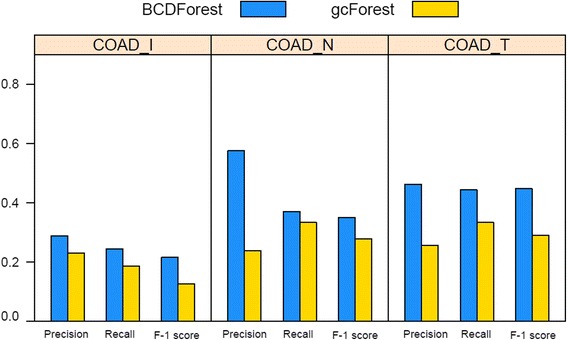
Similar articles
-
Kernel principal components based cascade forest towards disease identification with human microbiota.BMC Med Inform Decis Mak. 2021 Dec 23;21(1):360. doi: 10.1186/s12911-021-01705-5. BMC Med Inform Decis Mak. 2021. PMID: 34949186 Free PMC article.
-
A laminar augmented cascading flexible neural forest model for classification of cancer subtypes based on gene expression data.BMC Bioinformatics. 2021 Oct 2;22(1):475. doi: 10.1186/s12859-021-04391-2. BMC Bioinformatics. 2021. PMID: 34600466 Free PMC article.
-
A Cascade Flexible Neural Forest Model for Cancer Subtypes Classification on Gene Expression Data.Comput Intell Neurosci. 2021 Oct 5;2021:6480456. doi: 10.1155/2021/6480456. eCollection 2021. Comput Intell Neurosci. 2021. PMID: 34650605 Free PMC article.
-
Breast cancer cell nuclei classification in histopathology images using deep neural networks.Int J Comput Assist Radiol Surg. 2018 Feb;13(2):179-191. doi: 10.1007/s11548-017-1663-9. Epub 2017 Aug 31. Int J Comput Assist Radiol Surg. 2018. PMID: 28861708 Review.
-
Reviewing ensemble classification methods in breast cancer.Comput Methods Programs Biomed. 2019 Aug;177:89-112. doi: 10.1016/j.cmpb.2019.05.019. Epub 2019 May 20. Comput Methods Programs Biomed. 2019. PMID: 31319964 Review.
Cited by
-
Comparing biological information contained in mRNA and non-coding RNAs for classification of lung cancer patients.BMC Cancer. 2019 Dec 3;19(1):1176. doi: 10.1186/s12885-019-6338-1. BMC Cancer. 2019. PMID: 31796020 Free PMC article.
-
Hope4Genes: a Hopfield-like class prediction algorithm for transcriptomic data.Sci Rep. 2019 Jan 23;9(1):337. doi: 10.1038/s41598-018-36744-y. Sci Rep. 2019. PMID: 30674955 Free PMC article.
-
Machine learning in the prediction of cardiac surgery associated acute kidney injury with early postoperative biomarkers.Front Surg. 2023 Feb 7;10:1048431. doi: 10.3389/fsurg.2023.1048431. eCollection 2023. Front Surg. 2023. PMID: 36824496 Free PMC article.
-
Kernel principal components based cascade forest towards disease identification with human microbiota.BMC Med Inform Decis Mak. 2021 Dec 23;21(1):360. doi: 10.1186/s12911-021-01705-5. BMC Med Inform Decis Mak. 2021. PMID: 34949186 Free PMC article.
-
Multi-modality deep forest for hand motion recognition via fusing sEMG and acceleration signals.Int J Mach Learn Cybern. 2023;14(4):1119-1131. doi: 10.1007/s13042-022-01687-4. Epub 2022 Nov 1. Int J Mach Learn Cybern. 2023. PMID: 36339898 Free PMC article.
References
-
- Bianchini G, Iwamoto T, Qi Y, Coutant C, Shiang CY, Wang B, Santarpia L, Valero V, Hortobagyi GN, Symmans WF, et al. Prognostic and therapeutic implications of distinct kinase expression patterns in different subtypes of breast cancer. Cancer Res. 2010;70(21):8852–8862. doi: 10.1158/0008-5472.CAN-10-1039. - DOI - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
