

Computational mechanisms underlying cortical responses to the affordance properties of visual scenes
- PMID: 29684011
- PMCID: PMC5933806
- DOI: 10.1371/journal.pcbi.1006111
Computational mechanisms underlying cortical responses to the affordance properties of visual scenes
Abstract
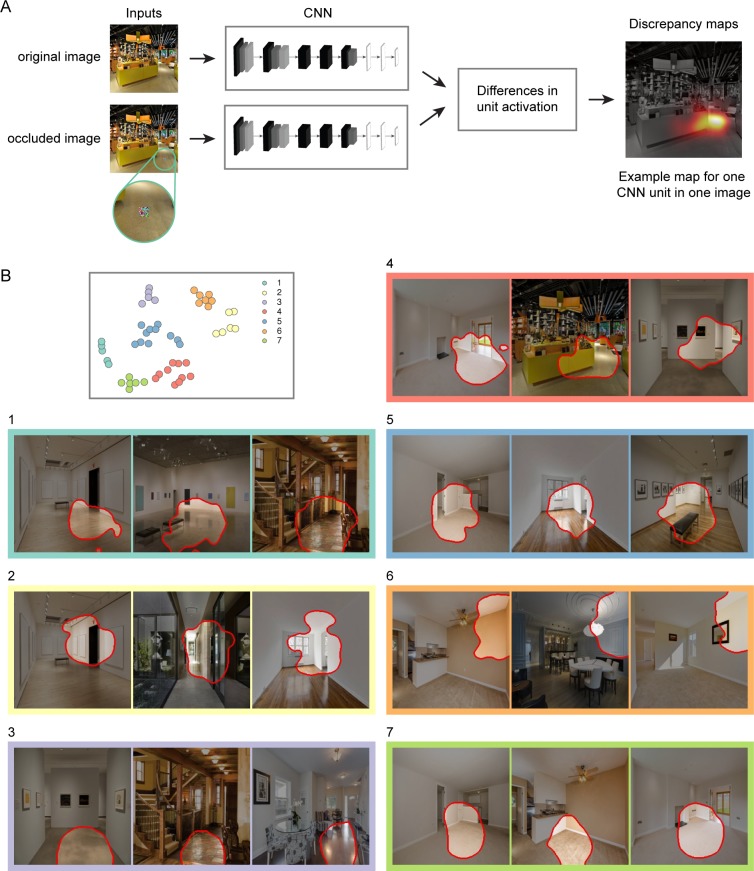
Biologically inspired deep convolutional neural networks (CNNs), trained for computer vision tasks, have been found to predict cortical responses with remarkable accuracy. However, the internal operations of these models remain poorly understood, and the factors that account for their success are unknown. Here we develop a set of techniques for using CNNs to gain insights into the computational mechanisms underlying cortical responses. We focused on responses in the occipital place area (OPA), a scene-selective region of dorsal occipitoparietal cortex. In a previous study, we showed that fMRI activation patterns in the OPA contain information about the navigational affordances of scenes; that is, information about where one can and cannot move within the immediate environment. We hypothesized that this affordance information could be extracted using a set of purely feedforward computations. To test this idea, we examined a deep CNN with a feedforward architecture that had been previously trained for scene classification. We found that responses in the CNN to scene images were highly predictive of fMRI responses in the OPA. Moreover the CNN accounted for the portion of OPA variance relating to the navigational affordances of scenes. The CNN could thus serve as an image-computable candidate model of affordance-related responses in the OPA. We then ran a series of in silico experiments on this model to gain insights into its internal operations. These analyses showed that the computation of affordance-related features relied heavily on visual information at high-spatial frequencies and cardinal orientations, both of which have previously been identified as low-level stimulus preferences of scene-selective visual cortex. These computations also exhibited a strong preference for information in the lower visual field, which is consistent with known retinotopic biases in the OPA. Visualizations of feature selectivity within the CNN suggested that affordance-based responses encoded features that define the layout of the spatial environment, such as boundary-defining junctions and large extended surfaces. Together, these results map the sensory functions of the OPA onto a fully quantitative model that provides insights into its visual computations. More broadly, they advance integrative techniques for understanding visual cortex across multiple level of analysis: from the identification of cortical sensory functions to the modeling of their underlying algorithms.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
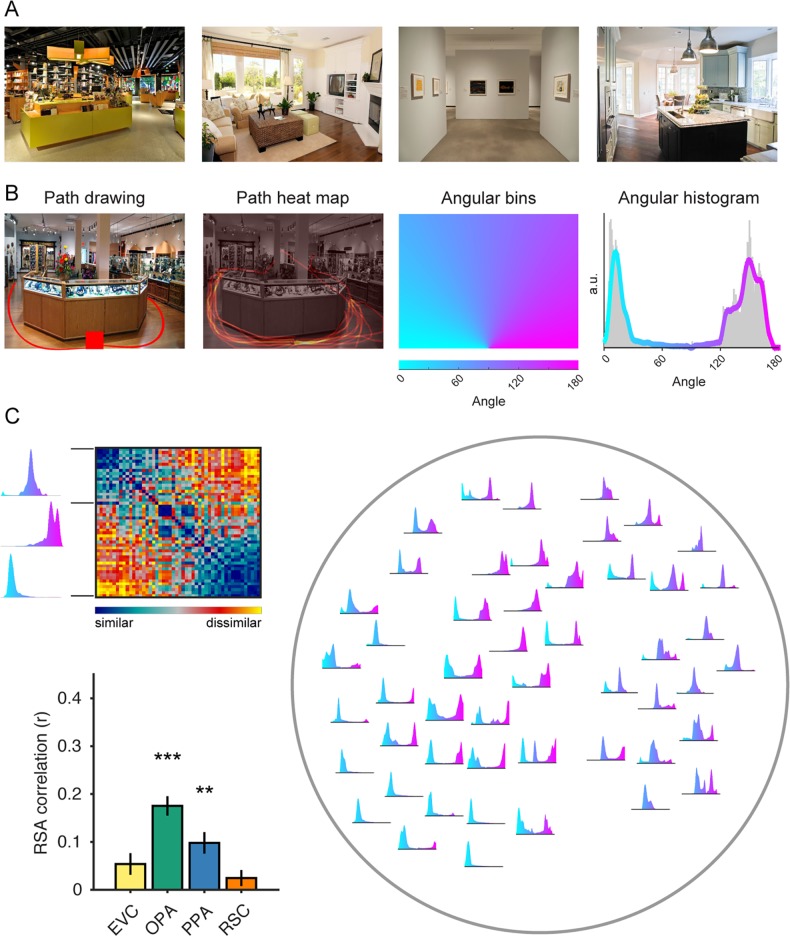

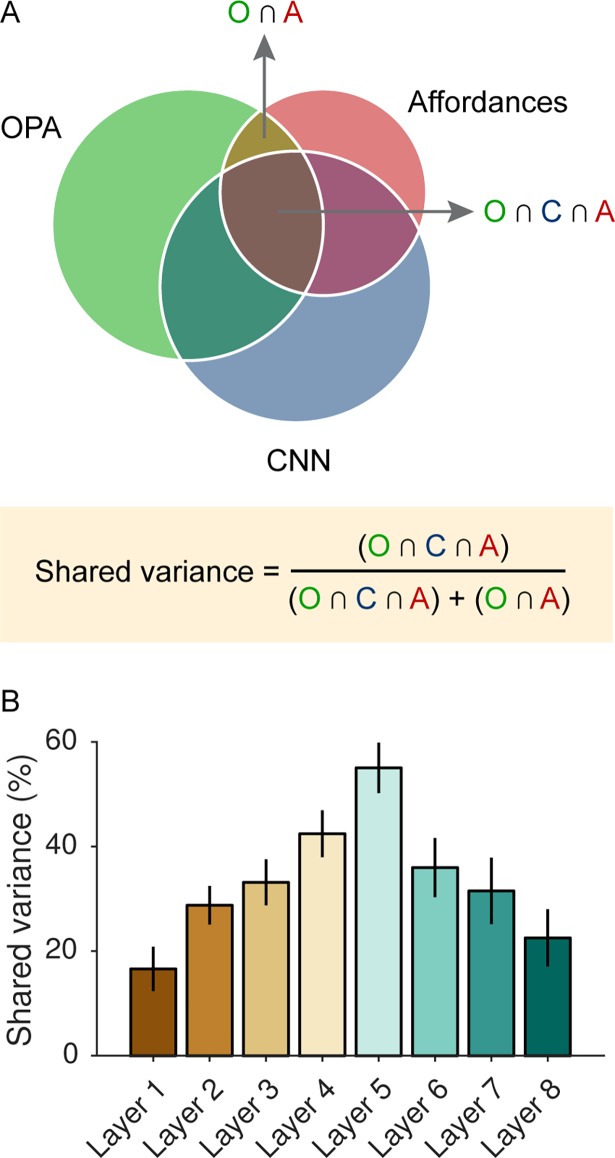
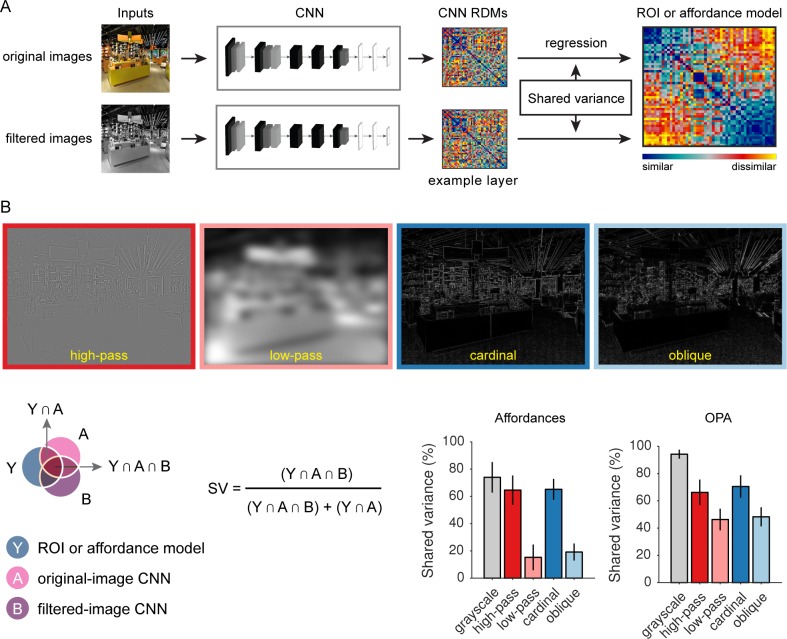
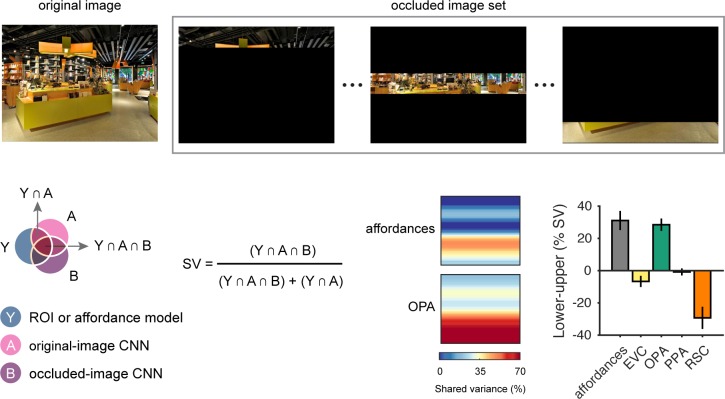

References
-
- LeCun Y, Bengio Y, Hinton G. Deep learning. Nature. 2015;521(7553):436–44. doi: 10.1038/nature14539 - DOI - PubMed
-
- Krizhevsky A, Sutskever I, Hinton GE. Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems 2012. p. 1097–105.
-
- Zhou B, Lapedriza A, Xiao J, Torralba A, Oliva A. Learning deep features for scene recognition using places database. Advances in neural information processing systems 2014. p. 487–95.
-
- Rawat W, Wang Z. Deep convolutional neural networks for image classification: a comprehensive review. Neural Comput. 2017. Epub June 09, 2017. doi: 10.1162/NECO_a_00990 . - DOI - PubMed
-
- Agrawal P, Stansbury D, Malik J, Gallant JL. Pixels to voxels: modeling visual representation in the human brain. arXiv preprint arXiv:14075104. 2014.
Publication types
MeSH terms
Associated data
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
