

A Dynamic Connectome Supports the Emergence of Stable Computational Function of Neural Circuits through Reward-Based Learning
- PMID: 29696150
- PMCID: PMC5913731
- DOI: 10.1523/ENEURO.0301-17.2018
A Dynamic Connectome Supports the Emergence of Stable Computational Function of Neural Circuits through Reward-Based Learning
Abstract
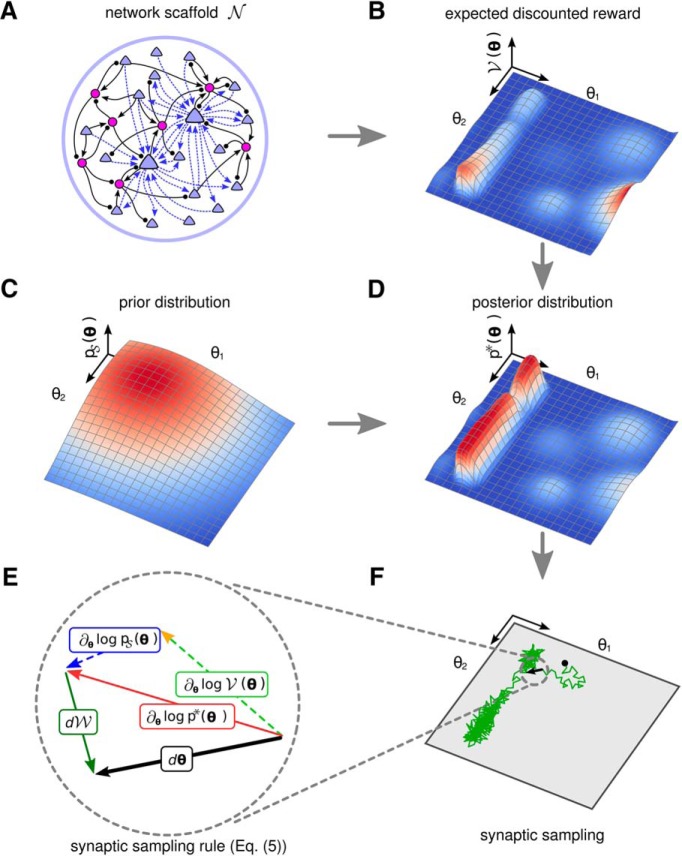
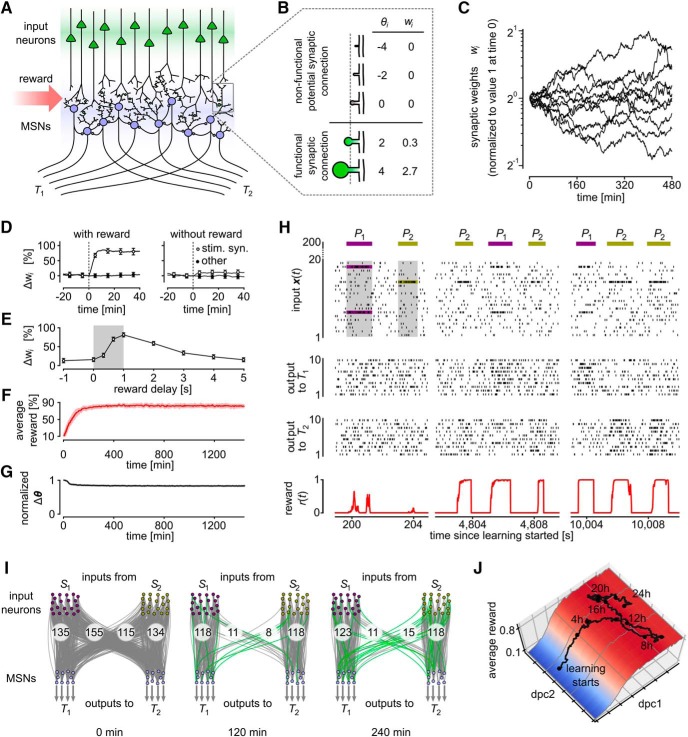
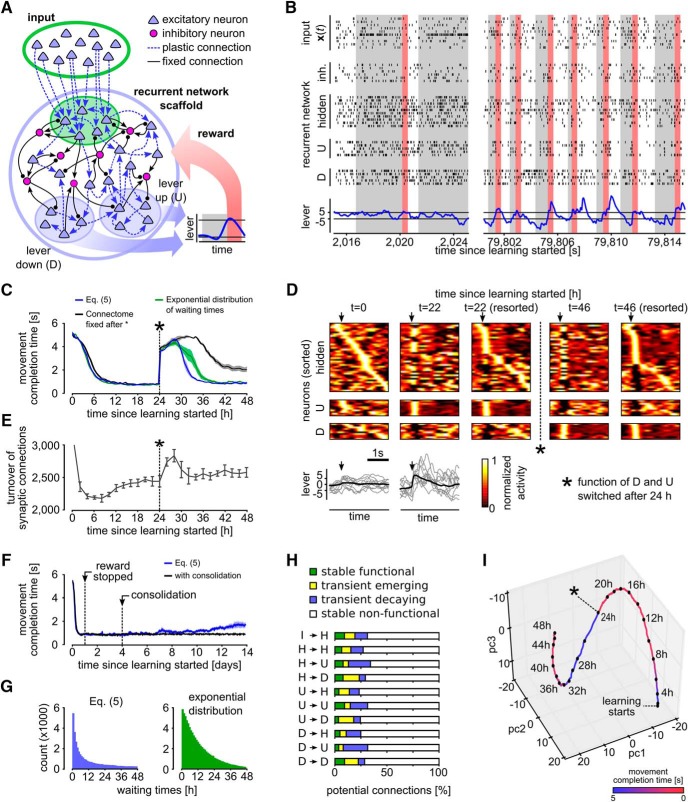
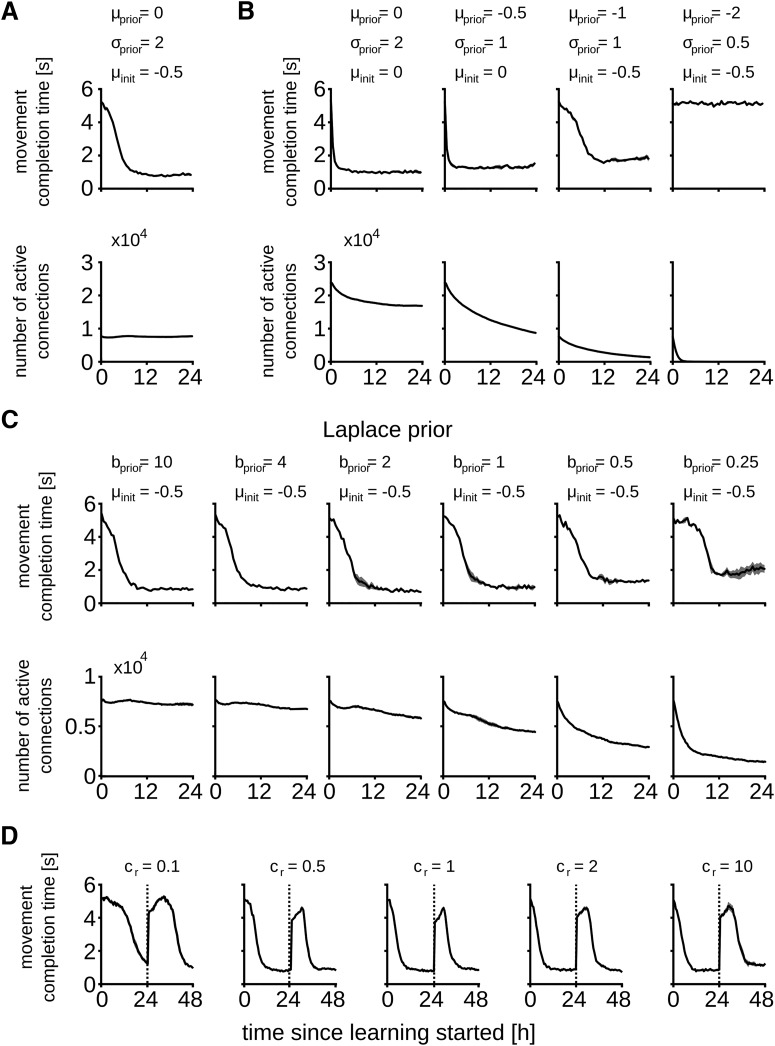
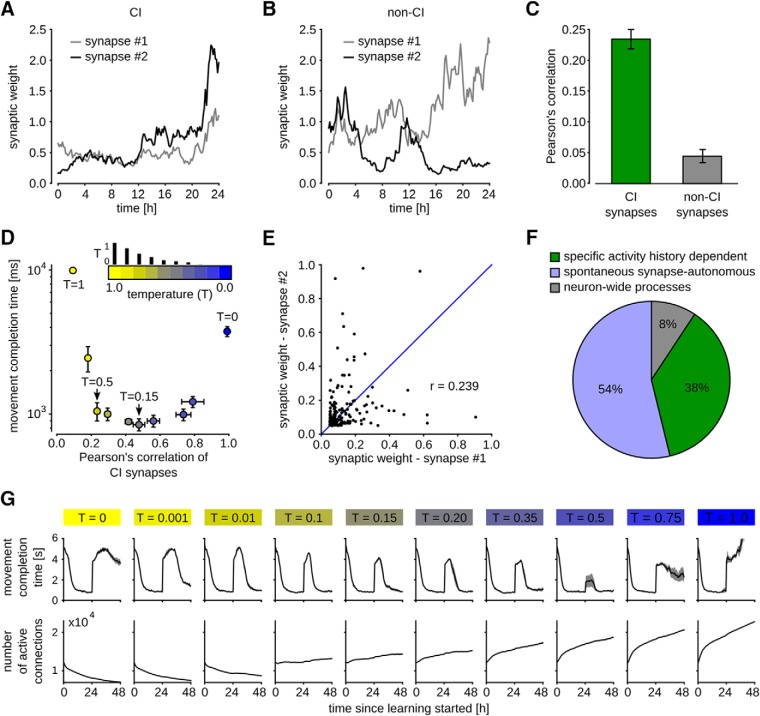
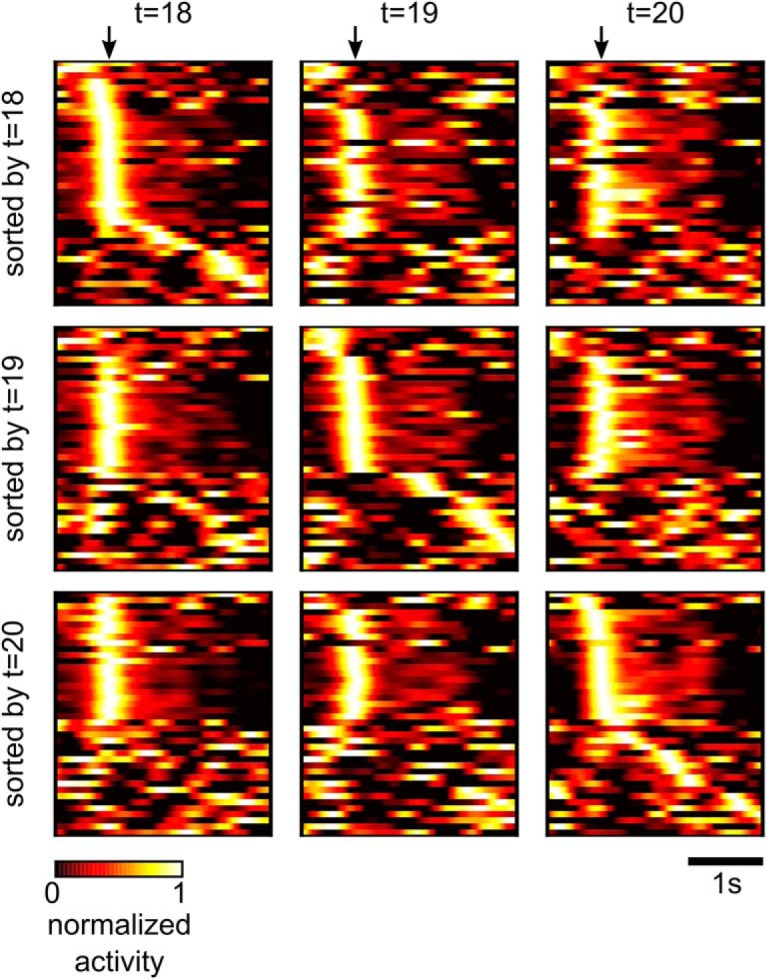
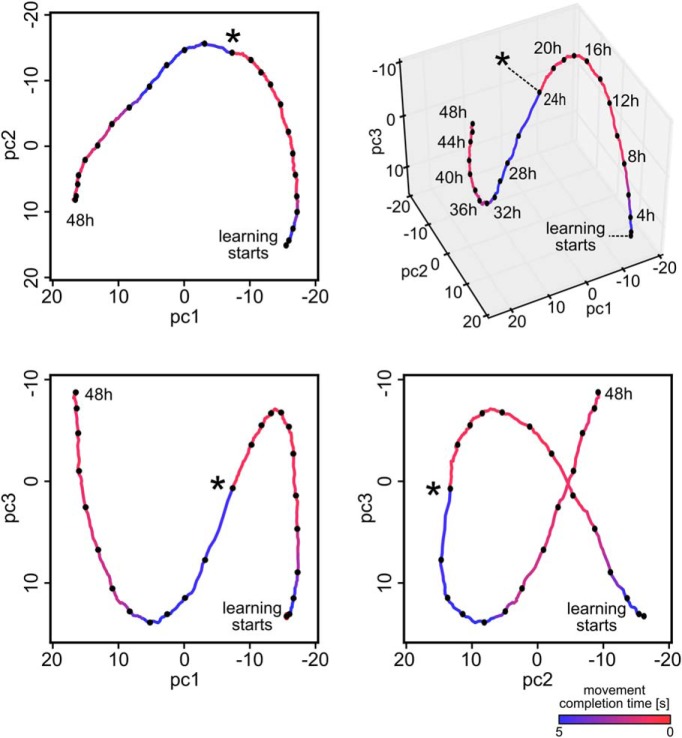
Synaptic connections between neurons in the brain are dynamic because of continuously ongoing spine dynamics, axonal sprouting, and other processes. In fact, it was recently shown that the spontaneous synapse-autonomous component of spine dynamics is at least as large as the component that depends on the history of pre- and postsynaptic neural activity. These data are inconsistent with common models for network plasticity and raise the following questions: how can neural circuits maintain a stable computational function in spite of these continuously ongoing processes, and what could be functional uses of these ongoing processes? Here, we present a rigorous theoretical framework for these seemingly stochastic spine dynamics and rewiring processes in the context of reward-based learning tasks. We show that spontaneous synapse-autonomous processes, in combination with reward signals such as dopamine, can explain the capability of networks of neurons in the brain to configure themselves for specific computational tasks, and to compensate automatically for later changes in the network or task. Furthermore, we show theoretically and through computer simulations that stable computational performance is compatible with continuously ongoing synapse-autonomous changes. After reaching good computational performance it causes primarily a slow drift of network architecture and dynamics in task-irrelevant dimensions, as observed for neural activity in motor cortex and other areas. On the more abstract level of reinforcement learning the resulting model gives rise to an understanding of reward-driven network plasticity as continuous sampling of network configurations.
Keywords: reward-modulated STDP; spine dynamics; stochastic synaptic plasticity; synapse-autonomous processes; synaptic rewiring; task-irrelevant dimensions in motor control.
Figures

Similar articles
-
Reward-dependent learning in neuronal networks for planning and decision making.Prog Brain Res. 2000;126:217-29. doi: 10.1016/S0079-6123(00)26016-0. Prog Brain Res. 2000. PMID: 11105649 Review.
-
A learning theory for reward-modulated spike-timing-dependent plasticity with application to biofeedback.PLoS Comput Biol. 2008 Oct;4(10):e1000180. doi: 10.1371/journal.pcbi.1000180. Epub 2008 Oct 10. PLoS Comput Biol. 2008. PMID: 18846203 Free PMC article.
-
Rewiring the connectome: Evidence and effects.Neurosci Biobehav Rev. 2018 May;88:51-62. doi: 10.1016/j.neubiorev.2018.03.001. Epub 2018 Mar 11. Neurosci Biobehav Rev. 2018. PMID: 29540321 Free PMC article. Review.
-
Reinforcement learning through modulation of spike-timing-dependent synaptic plasticity.Neural Comput. 2007 Jun;19(6):1468-502. doi: 10.1162/neco.2007.19.6.1468. Neural Comput. 2007. PMID: 17444757
-
Self-tuning of neural circuits through short-term synaptic plasticity.J Neurophysiol. 2007 Jun;97(6):4079-95. doi: 10.1152/jn.01357.2006. Epub 2007 Apr 4. J Neurophysiol. 2007. PMID: 17409166
Cited by
-
Training a spiking neuronal network model of visual-motor cortex to play a virtual racket-ball game using reinforcement learning.PLoS One. 2022 May 11;17(5):e0265808. doi: 10.1371/journal.pone.0265808. eCollection 2022. PLoS One. 2022. PMID: 35544518 Free PMC article.
-
A stable sensory map emerges from a dynamic equilibrium of neurons with unstable tuning properties.Cereb Cortex. 2023 Apr 25;33(9):5597-5612. doi: 10.1093/cercor/bhac445. Cereb Cortex. 2023. PMID: 36418925 Free PMC article.
-
Unraveling the mysteries of dendritic spine dynamics: Five key principles shaping memory and cognition.Proc Jpn Acad Ser B Phys Biol Sci. 2023;99(8):254-305. doi: 10.2183/pjab.99.018. Proc Jpn Acad Ser B Phys Biol Sci. 2023. PMID: 37821392 Free PMC article.
-
Self-organized reactivation maintains and reinforces memories despite synaptic turnover.Elife. 2019 May 10;8:e43717. doi: 10.7554/eLife.43717. Elife. 2019. PMID: 31074745 Free PMC article.
-
Geometric framework to predict structure from function in neural networks.Phys Rev Res. 2022 Jun-Aug;4(2):023255. doi: 10.1103/physrevresearch.4.023255. Epub 2022 Jun 22. Phys Rev Res. 2022. PMID: 37635906 Free PMC article.
References
-
- Baxter J, Bartlett PL (2000) Direct gradient-based reinforcement learning. Proceedings of the 200 IEEE International Symposium on Circuits and Systems, 3:271–274.
-
- Bellec G, Kappel D, Maass W, Legenstein R (2017) Deep rewiring: training very sparse deep networks. arXiv arXiv:1711.05136.
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources