

Association of Pathological Fibrosis With Renal Survival Using Deep Neural Networks
- PMID: 29725651
- PMCID: PMC5932308
- DOI: 10.1016/j.ekir.2017.11.002
Association of Pathological Fibrosis With Renal Survival Using Deep Neural Networks
Abstract
Introduction: Chronic kidney damage is routinely assessed semiquantitatively by scoring the amount of fibrosis and tubular atrophy in a renal biopsy sample. Although image digitization and morphometric techniques can better quantify the extent of histologic damage, we need more widely applicable ways to stratify kidney disease severity.
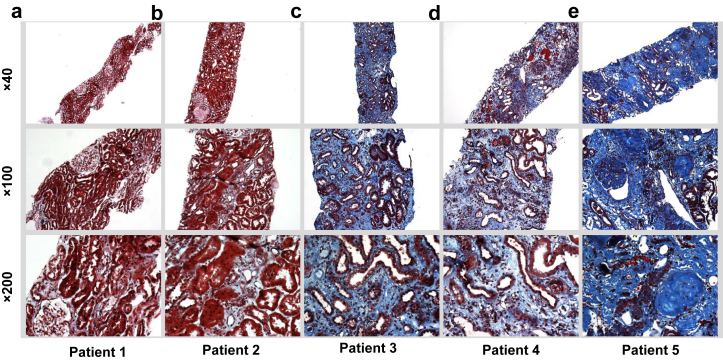
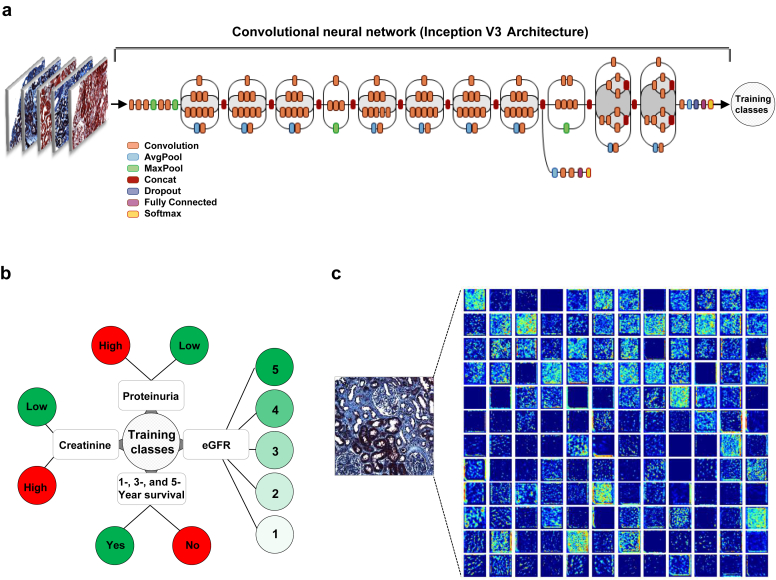
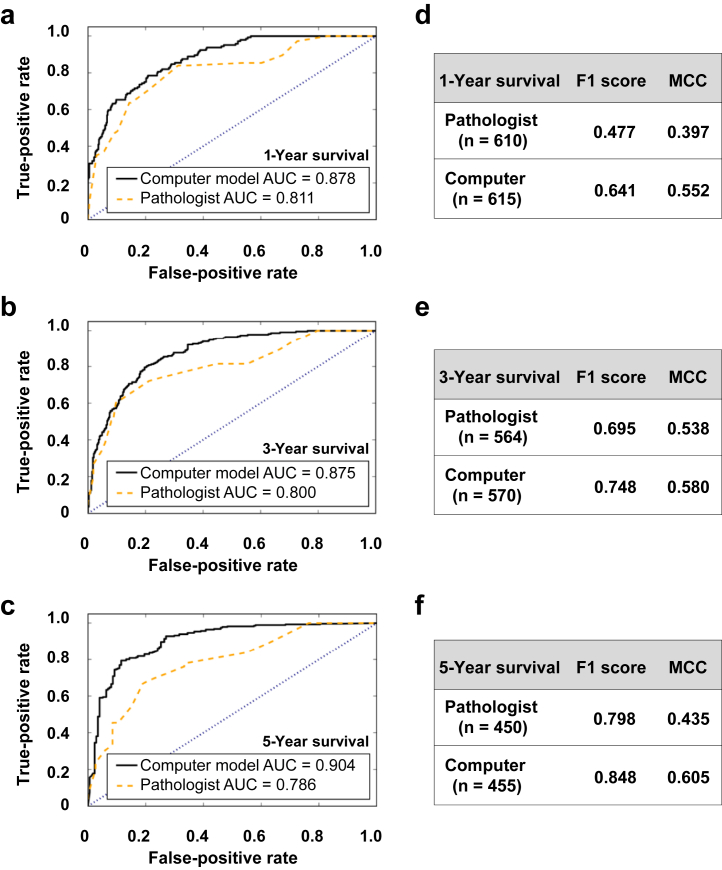
Methods: We leveraged a deep learning architecture to better associate patient-specific histologic images with clinical phenotypes (training classes) including chronic kidney disease (CKD) stage, serum creatinine, and nephrotic-range proteinuria at the time of biopsy, and 1-, 3-, and 5-year renal survival. Trichrome-stained images processed from renal biopsy samples were collected on 171 patients treated at the Boston Medical Center from 2009 to 2012. Six convolutional neural network (CNN) models were trained using these images as inputs and the training classes as outputs, respectively. For comparison, we also trained separate classifiers using the pathologist-estimated fibrosis score (PEFS) as input and the training classes as outputs, respectively.
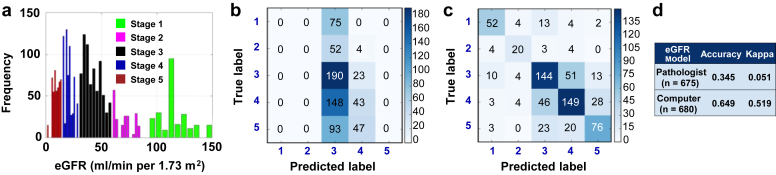
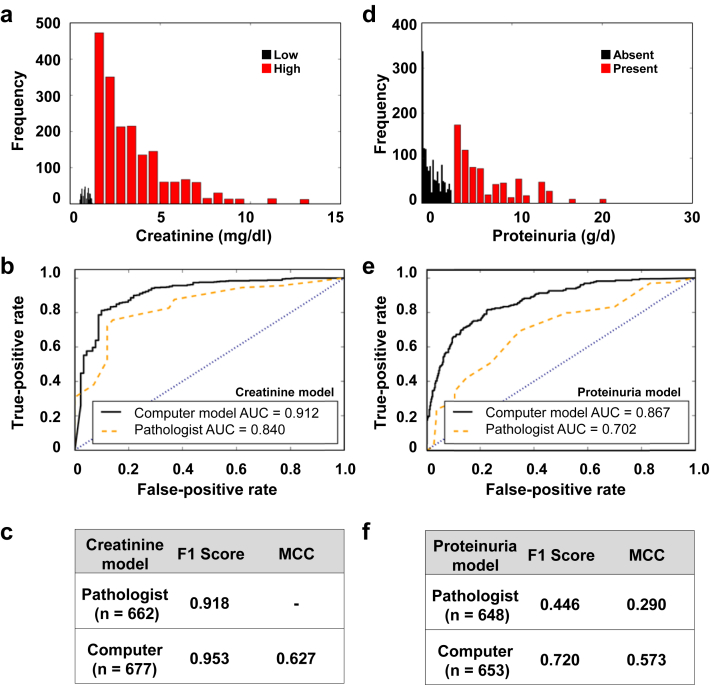
Results: CNN models outperformed PEFS across the classification tasks. Specifically, the CNN model predicted the CKD stage more accurately than the PEFS model (κ = 0.519 vs. 0.051). For creatinine models, the area under curve (AUC) was 0.912 (CNN) versus 0.840 (PEFS). For proteinuria models, AUC was 0.867 (CNN) versus 0.702 (PEFS). AUC values for the CNN models for 1-, 3-, and 5-year renal survival were 0.878, 0.875, and 0.904, respectively, whereas the AUC values for PEFS model were 0.811, 0.800, and 0.786, respectively.
Conclusion: The study demonstrates a proof of principle that deep learning can be applied to routine renal biopsy images.
Keywords: histology; machine learning; renal fibrosis; renal survival.
Figures
References
-
- Darcy A.M., Louie A.K., Roberts L.W. Machine learning and the profession of medicine. JAMA. 2016;315:551–552. - PubMed
-
- Kang J., Schwartz R., Flickinger J., Beriwal S. Machine learning approaches for predicting radiation therapy outcomes: a clinician's perspective. Int J Radiat Oncol Biol Phys. 2015;93:1127–1135. - PubMed
-
- Waljee A.K., Higgins P.D. Machine learning in medicine: a primer for physicians. Am J Gastroenterol. 2010;105:1224–1226. - PubMed
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
