

Belief state representation in the dopamine system
- PMID: 29760401
- PMCID: PMC5951832
- DOI: 10.1038/s41467-018-04397-0
Belief state representation in the dopamine system
Abstract
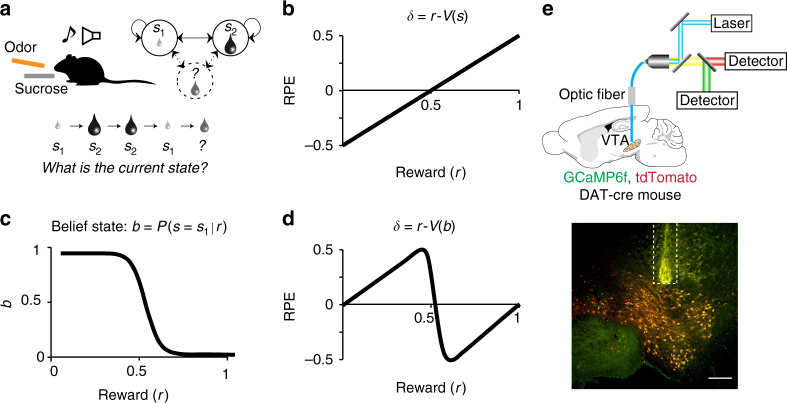
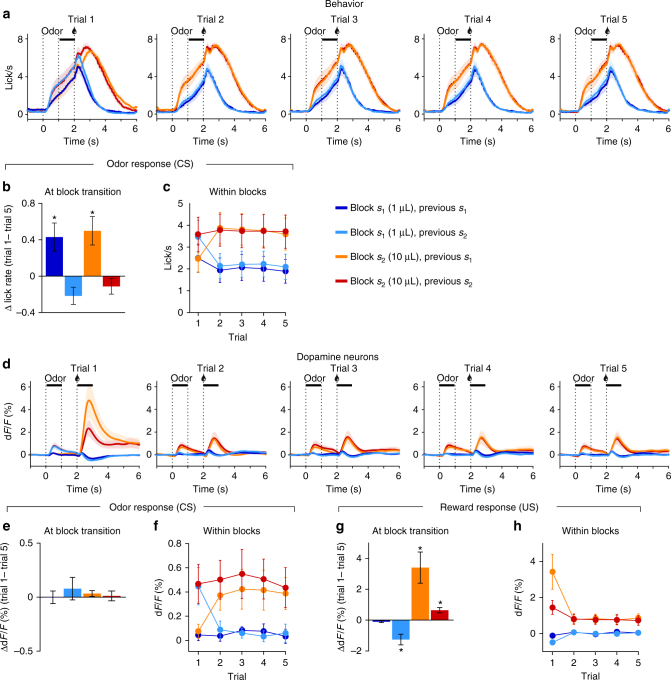
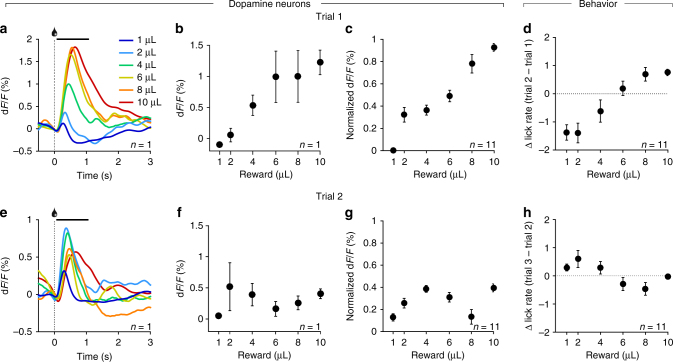
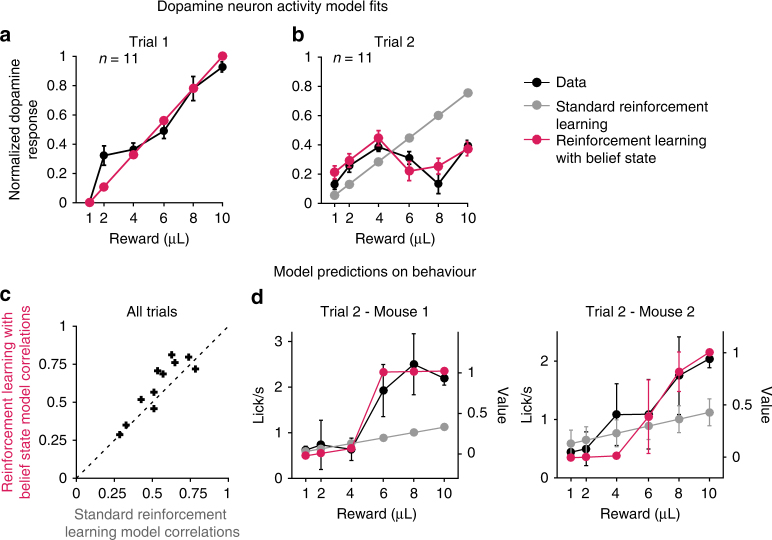
Learning to predict future outcomes is critical for driving appropriate behaviors. Reinforcement learning (RL) models have successfully accounted for such learning, relying on reward prediction errors (RPEs) signaled by midbrain dopamine neurons. It has been proposed that when sensory data provide only ambiguous information about which state an animal is in, it can predict reward based on a set of probabilities assigned to hypothetical states (called the belief state). Here we examine how dopamine RPEs and subsequent learning are regulated under state uncertainty. Mice are first trained in a task with two potential states defined by different reward amounts. During testing, intermediate-sized rewards are given in rare trials. Dopamine activity is a non-monotonic function of reward size, consistent with RL models operating on belief states. Furthermore, the magnitude of dopamine responses quantitatively predicts changes in behavior. These results establish the critical role of state inference in RL.
Conflict of interest statement
The authors declare no competing interests.
Figures
References
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
