

Age affects reinforcement learning through dopamine-based learning imbalance and high decision noise-not through Parkinsonian mechanisms
- PMID: 29778803
- PMCID: PMC5993631
- DOI: 10.1016/j.neurobiolaging.2018.04.006
Age affects reinforcement learning through dopamine-based learning imbalance and high decision noise-not through Parkinsonian mechanisms
Abstract
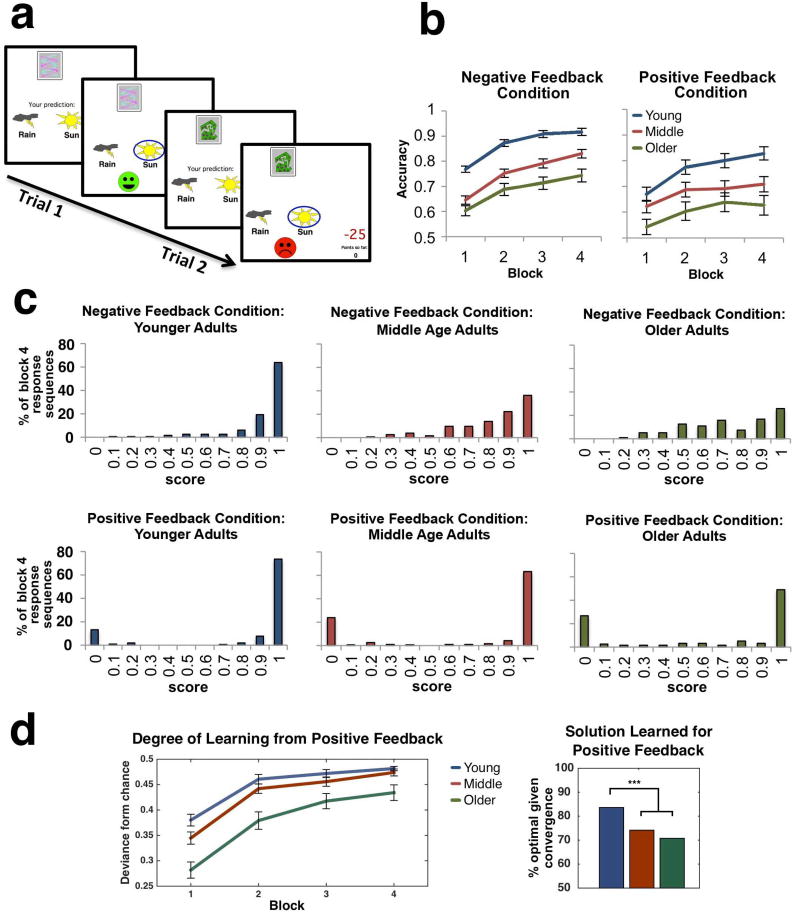
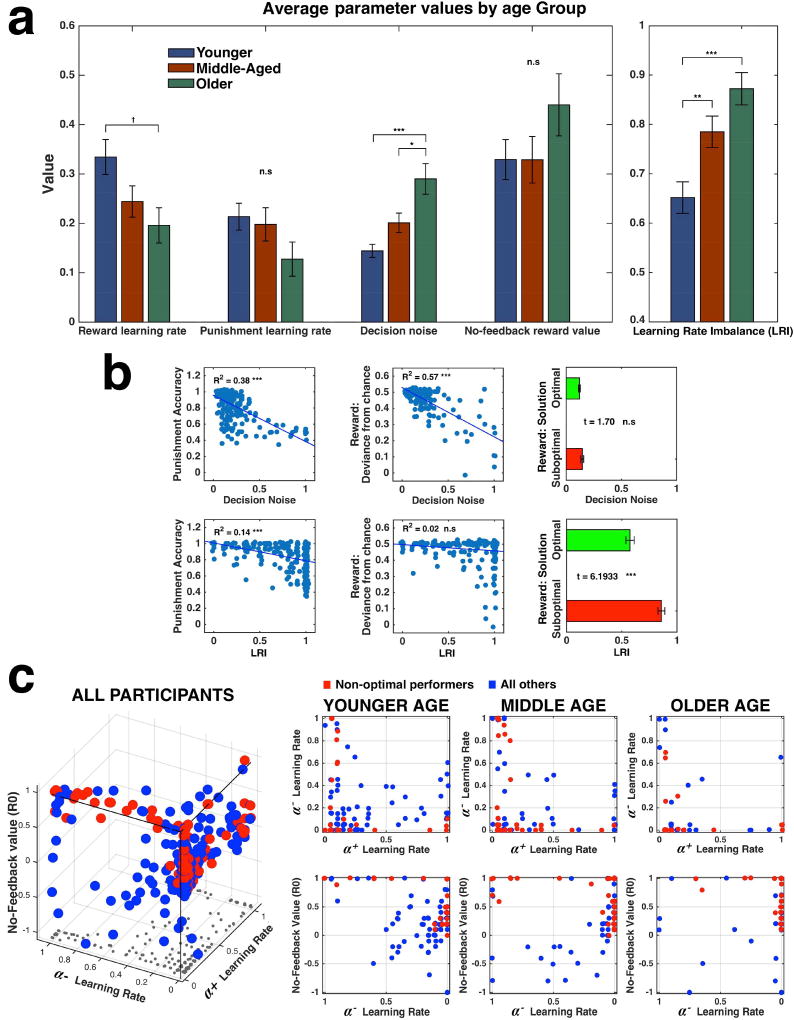
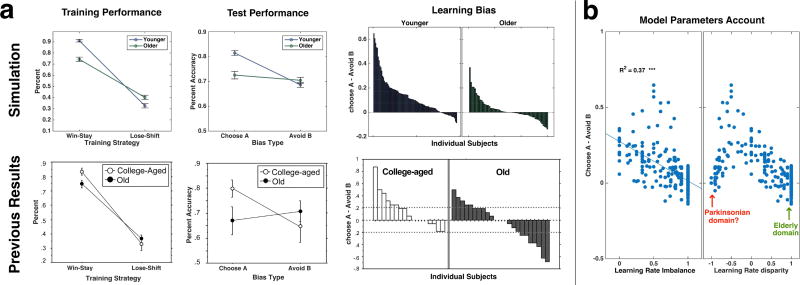
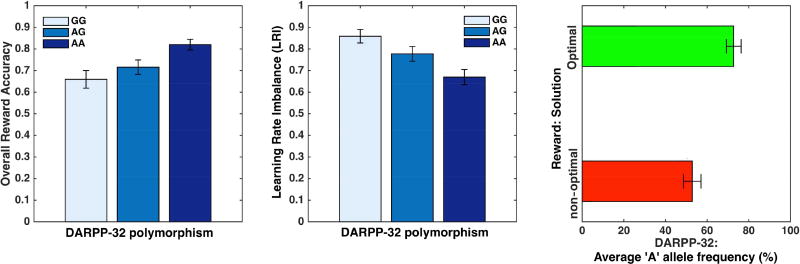
Probabilistic reinforcement learning declines in healthy cognitive aging. While some findings suggest impairments are especially conspicuous in learning from rewards, resembling deficits in Parkinson's disease, others also show impairments in learning from punishments. To reconcile these findings, we tested 252 adults from 3 age groups on a probabilistic reinforcement learning task, analyzed trial-by-trial performance with a Q-reinforcement learning model, and correlated both fitted model parameters and behavior to polymorphisms in dopamine-related genes. Analyses revealed that learning from both positive and negative feedback declines with age but through different mechanisms: when learning from negative feedback, older adults were slower due to noisy decision-making; when learning from positive feedback, they tended to settle for a nonoptimal solution due to an imbalance in learning from positive and negative prediction errors. The imbalance was associated with polymorphisms in the DARPP-32 gene and appeared to arise from mechanisms different from those previously attributed to Parkinson's disease. Moreover, this imbalance predicted previous findings on aging using the Probabilistic Selection Task, which were misattributed to Parkinsonian mechanisms.
Keywords: Aging; Dopamine; Parkinson's disease; Q-learning; Reinforcement learning.
Copyright © 2018 Elsevier Inc. All rights reserved.
Conflict of interest statement
The authors confirm that there are no known conflicts of interest associated with the publication of this manuscript.
Figures

Comment in
-
How age affects reinforcement learning.Aging (Albany NY). 2018 Nov 12;10(12):3630-3631. doi: 10.18632/aging.101649. Aging (Albany NY). 2018. PMID: 30418934 Free PMC article. No abstract available.
References
-
- Backman L, Nyberg L, Lindenberger U, Li S-C, Farde L. The correlative triad among aging, dopamine, and cognition. Neurosci. Biobehav. Rev. 2006;3:791–807. - PubMed
-
- Calabresi P, Gubellini P, Centonze D, Picconi B, Bernardi G, Chergui K, Svenningsson P, Fienberg AA, Greengard P. Dopamine and cAMP-regulated phosphoprotein 32 kDa controls both striatal and long-term depression and long-term potentiation, opposing forms of synaptic plasticity. J. Neurosci. 2000;22:8443–8451. - PMC - PubMed
-
- Cavanagh J, Masters SE, Bath K, Frank MJ. Conflict acts as an implicit cost in reinforcement learning. Nature Communications. 2014;5 Article 5394. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
