

Interrogation of Mammalian Protein Complex Structure, Function, and Membership Using Genome-Scale Fitness Screens
- PMID: 29778836
- PMCID: PMC6152908
- DOI: 10.1016/j.cels.2018.04.011
Interrogation of Mammalian Protein Complex Structure, Function, and Membership Using Genome-Scale Fitness Screens
Abstract
Protein complexes are assemblies of subunits that have co-evolved to execute one or many coordinated functions in the cellular environment. Functional annotation of mammalian protein complexes is critical to understanding biological processes, as well as disease mechanisms. Here, we used genetic co-essentiality derived from genome-scale RNAi- and CRISPR-Cas9-based fitness screens performed across hundreds of human cancer cell lines to assign measures of functional similarity. From these measures, we systematically built and characterized functional similarity networks that recapitulate known structural and functional features of well-studied protein complexes and resolve novel functional modules within complexes lacking structural resolution, such as the mammalian SWI/SNF complex. Finally, by integrating functional networks with large protein-protein interaction networks, we discovered novel protein complexes involving recently evolved genes of unknown function. Taken together, these findings demonstrate the utility of genetic perturbation screens alone, and in combination with large-scale biophysical data, to enhance our understanding of mammalian protein complexes in normal and disease states.
Keywords: fitness correlations; genetic perturbation screens; mammalian SWI/SNF; protein complexes; shRNA and CRISPR/Cas9-based genetic screens.
Copyright © 2018 The Authors. Published by Elsevier Inc. All rights reserved.
Figures

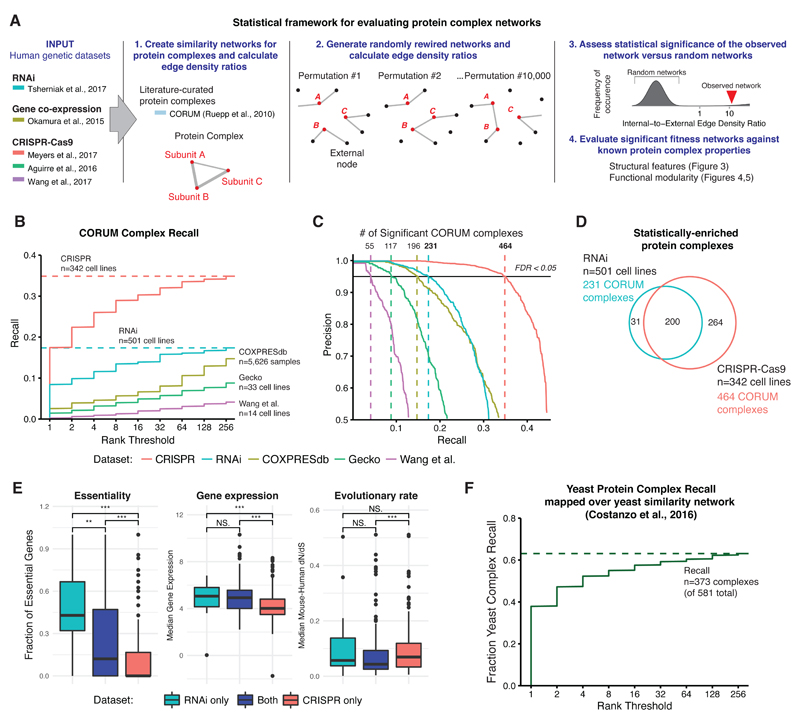
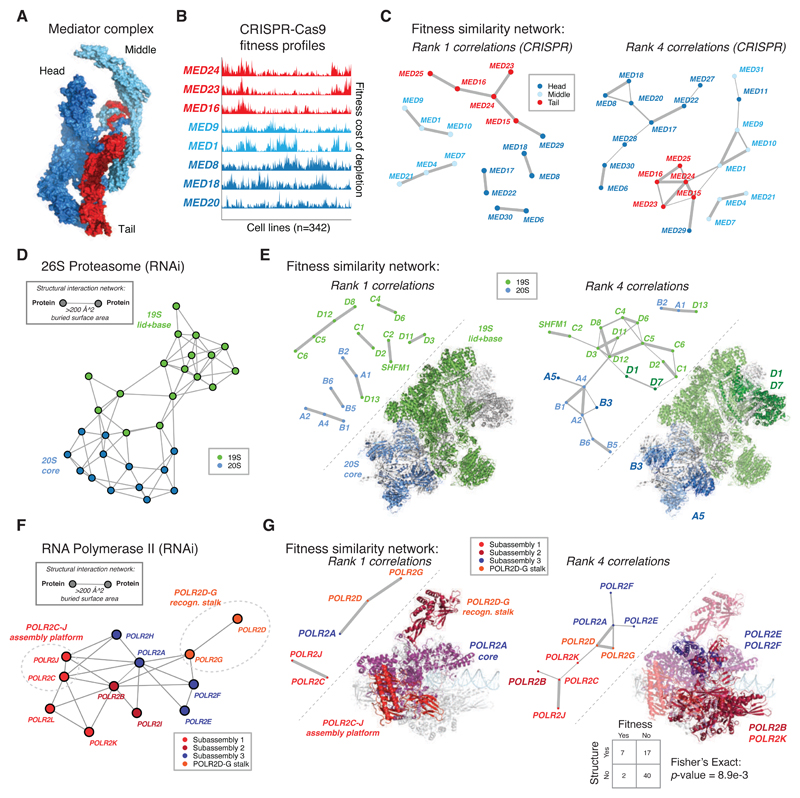

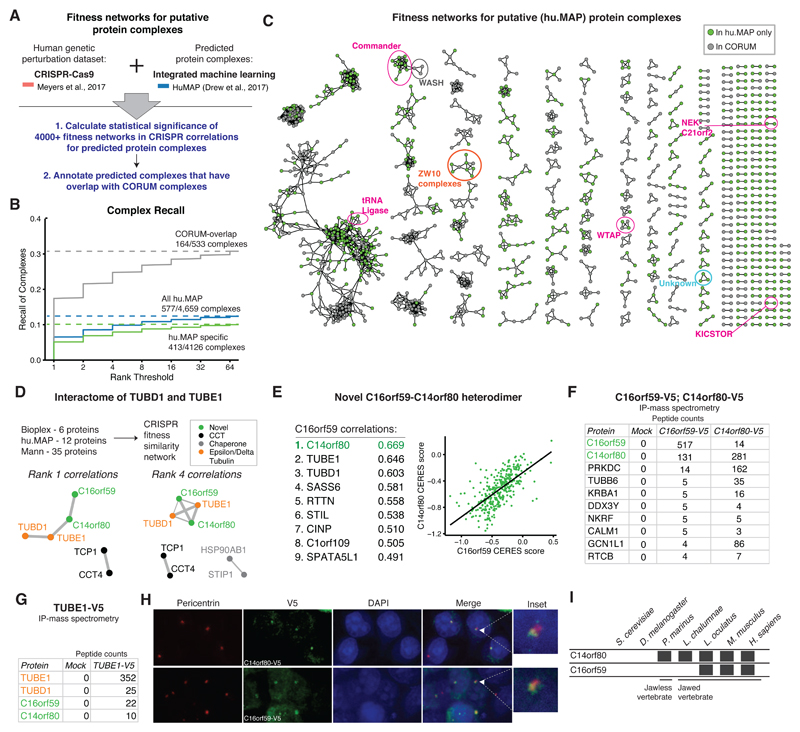
References
-
- Ahnert SE, Marsh JA, Hernandez H, Robinson CV, Teichmann SA. Principles of assembly reveal a periodic table of protein complexes. Science. 2015;350:aaa2245. - PubMed
-
- Baliga NS, Björkegren J, Boeke JD, Boutros M, Crawford N, Dudley AM, Farber CR, Jones A, Levey AI, Lusis AJ, et al. The State of Systems Genetics in 2017. Cell Systems. 2017;4:7–15. - PubMed
-
- Baryshnikova A, Costanzo M, Myers CL, Andrews B, Boone C. Genetic interaction networks: toward an understanding of heritability. Annual review of genomics and human genetics. 2013;14:111–133. - PubMed
Publication types
MeSH terms
Substances
Associated data
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
