

The Selective Labels Problem: Evaluating Algorithmic Predictions in the Presence of Unobservables
- PMID: 29780658
- PMCID: PMC5958915
- DOI: 10.1145/3097983.3098066
The Selective Labels Problem: Evaluating Algorithmic Predictions in the Presence of Unobservables
Abstract
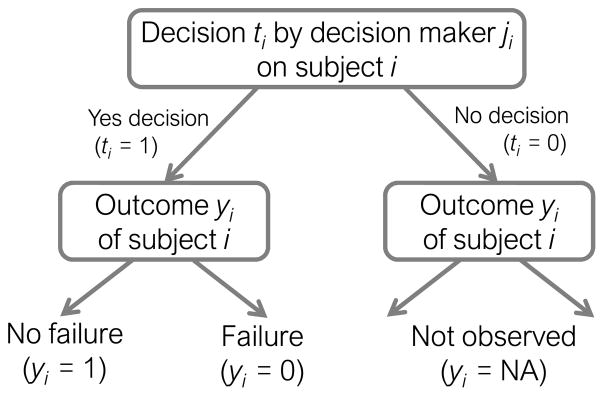
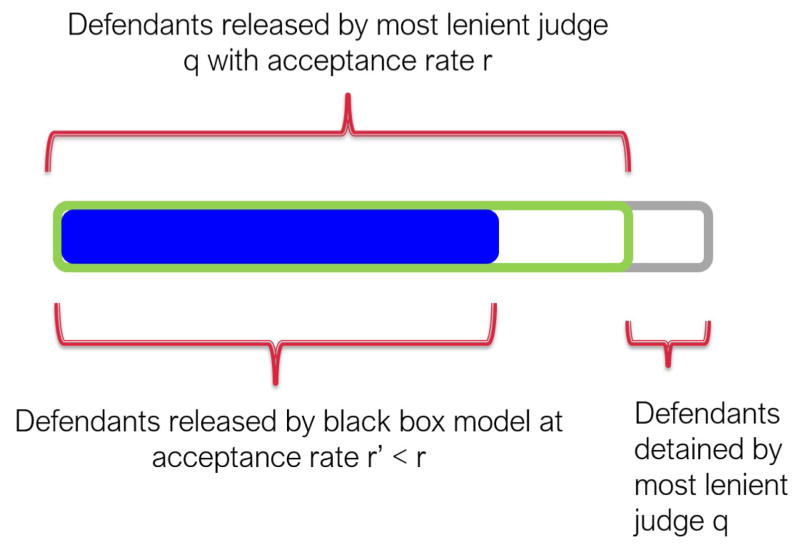
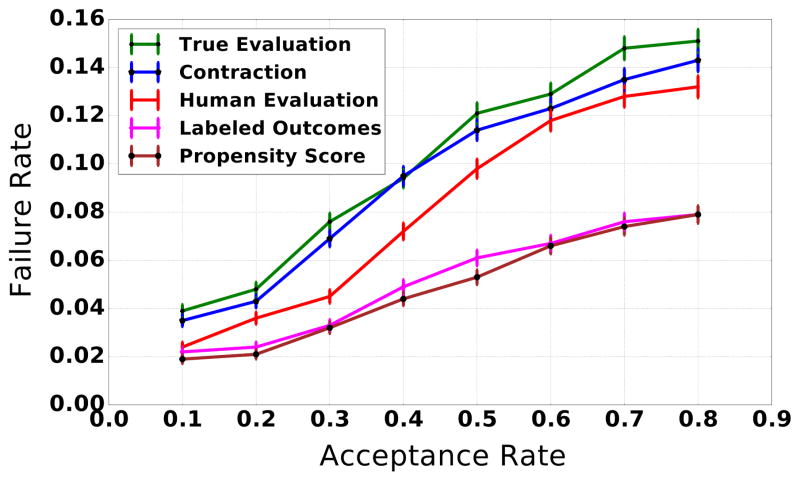
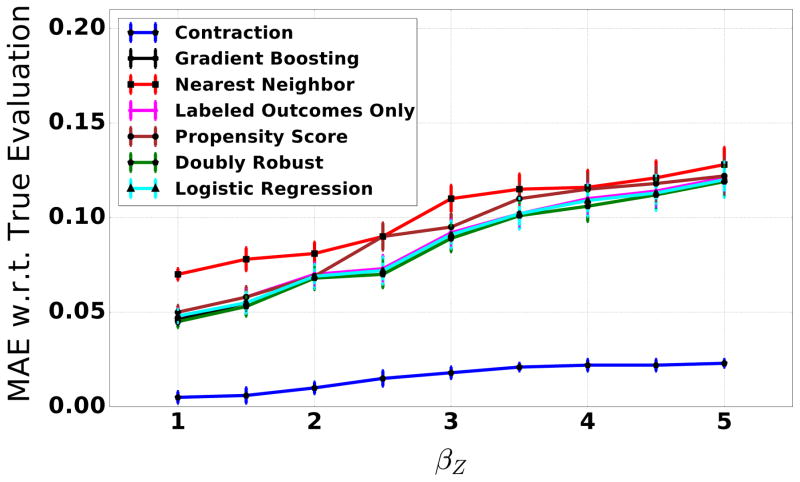
Evaluating whether machines improve on human performance is one of the central questions of machine learning. However, there are many domains where the data is selectively labeled in the sense that the observed outcomes are themselves a consequence of the existing choices of the human decision-makers. For instance, in the context of judicial bail decisions, we observe the outcome of whether a defendant fails to return for their court appearance only if the human judge decides to release the defendant on bail. This selective labeling makes it harder to evaluate predictive models as the instances for which outcomes are observed do not represent a random sample of the population. Here we propose a novel framework for evaluating the performance of predictive models on selectively labeled data. We develop an approach called contraction which allows us to compare the performance of predictive models and human decision-makers without resorting to counterfactual inference. Our methodology harnesses the heterogeneity of human decision-makers and facilitates effective evaluation of predictive models even in the presence of unmeasured confounders (unobservables) which influence both human decisions and the resulting outcomes. Experimental results on real world datasets spanning diverse domains such as health care, insurance, and criminal justice demonstrate the utility of our evaluation metric in comparing human decisions and machine predictions.
Figures


References
-
- Allison PD. Missing data: Quantitative applications in the social sciences. British Journal of Mathematical and Statistical Psychology. 2002;55(1):193–196.
-
- Angrist JD, Imbens GW, Rubin DB. Identification of causal effects using instrumental variables. JASA. 1996;91(434):444–455.
-
- Angrist JD, Pischke J-S. Mostly harmless econometrics: An empiricist’s companion. Princeton university press; 2008.
-
- Bang H, Robins JM. Doubly robust estimation in missing data and causal inference models. Biometrics. 2005;61(4):962–973. - PubMed
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources