

A computational framework for complex disease stratification from multiple large-scale datasets
- PMID: 29843806
- PMCID: PMC5975674
- DOI: 10.1186/s12918-018-0556-z
A computational framework for complex disease stratification from multiple large-scale datasets
Abstract
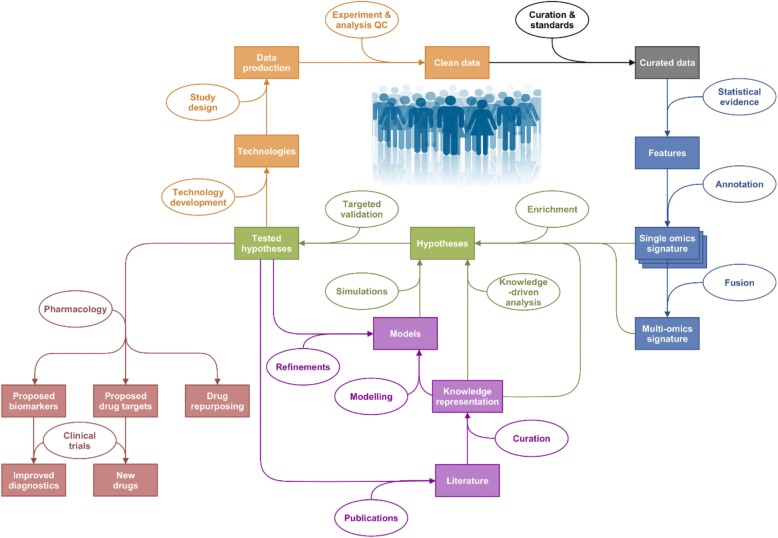
Background: Multilevel data integration is becoming a major area of research in systems biology. Within this area, multi-'omics datasets on complex diseases are becoming more readily available and there is a need to set standards and good practices for integrated analysis of biological, clinical and environmental data. We present a framework to plan and generate single and multi-'omics signatures of disease states.
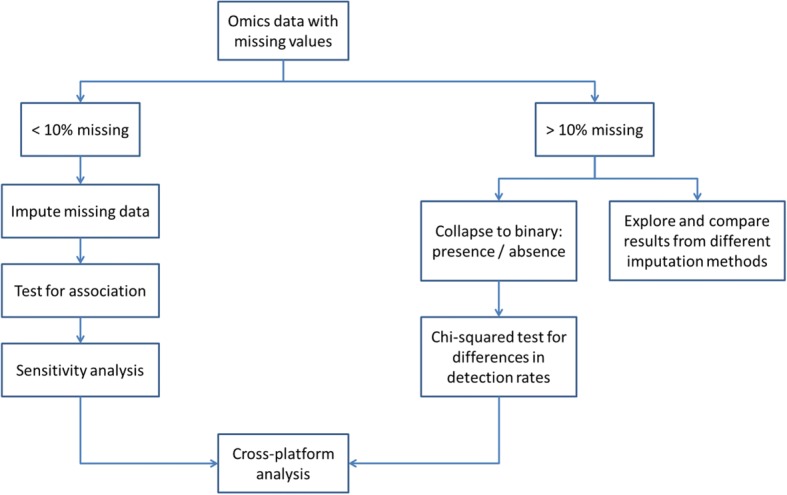
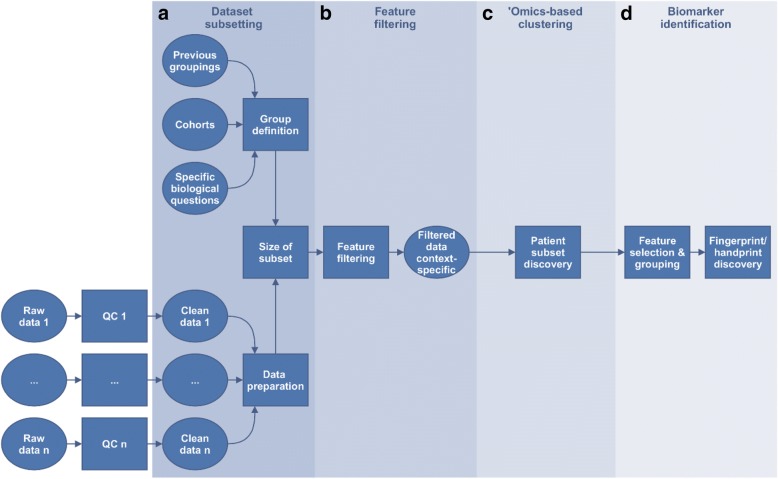
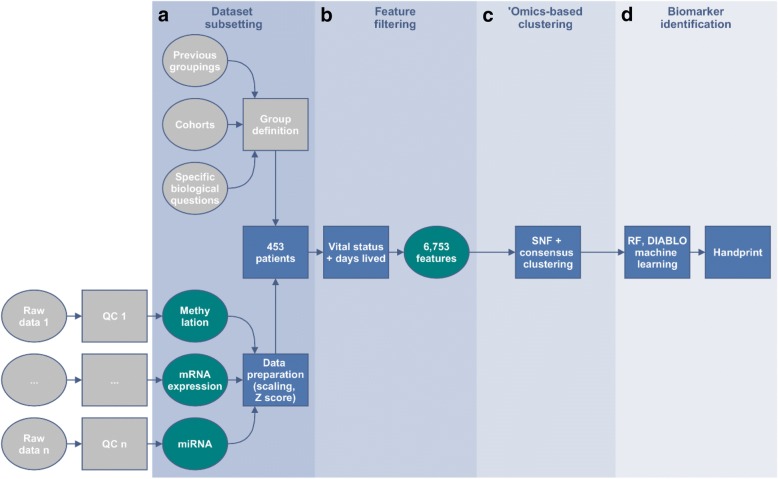
Methods: The framework is divided into four major steps: dataset subsetting, feature filtering, 'omics-based clustering and biomarker identification.
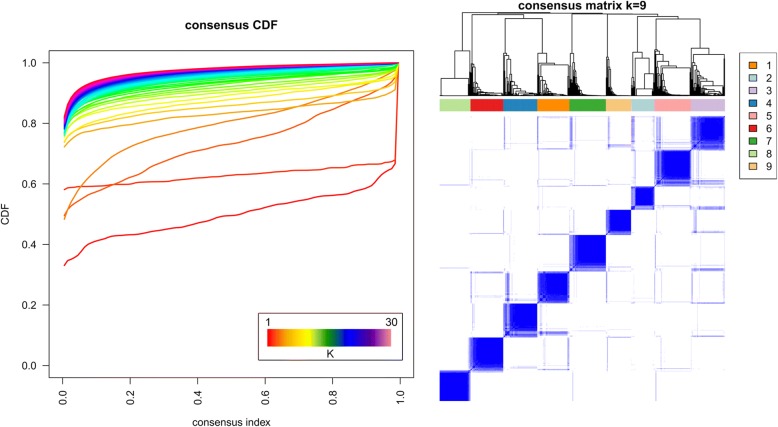
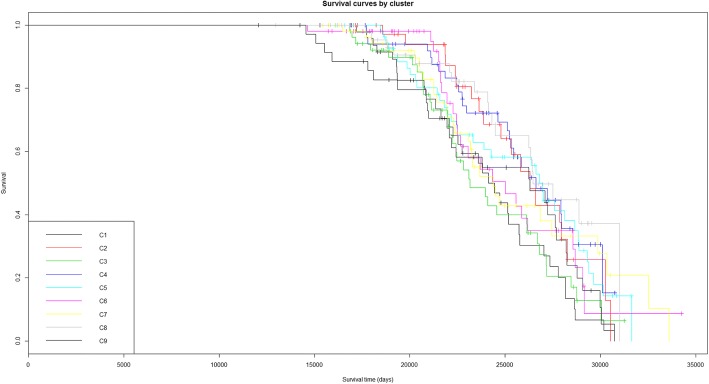
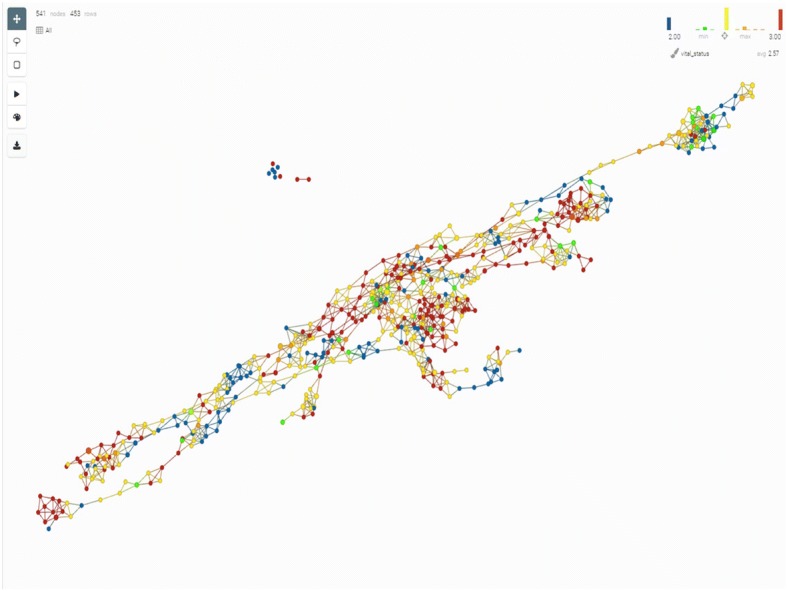
Results: We illustrate the usefulness of this framework by identifying potential patient clusters based on integrated multi-'omics signatures in a publicly available ovarian cystadenocarcinoma dataset. The analysis generated a higher number of stable and clinically relevant clusters than previously reported, and enabled the generation of predictive models of patient outcomes.
Conclusions: This framework will help health researchers plan and perform multi-'omics big data analyses to generate hypotheses and make sense of their rich, diverse and ever growing datasets, to enable implementation of translational P4 medicine.
Keywords: Molecular signatures; Stratification; Systems medicine; ‘Omics data.
Conflict of interest statement
Ethics approval and consent to participate
Not applicable
Consent for publication
Not applicable
Competing interests
ATB received fees from Acclarogen Ltd. KK received fees from UCB Celltech Ltd. JvE received fees from UCB Pharma S.A. AB received fees from Roche Products Ltd. TD received fees from Janssen R & D High Wycombe Ltd. PD received fees from AstraZeneca Ltd. CL received fees from GSK Ltd. JC received fees from Areteva R & D Ltd. AMan received fees from Roche Diagnostics GmbH, AR received fees from Janssen R & D High Wycombe Ltd. FB received fees from Janssen R & D Springhouse LLC.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Figures
References
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
