

The MR-Base platform supports systematic causal inference across the human phenome
- PMID: 29846171
- PMCID: PMC5976434
- DOI: 10.7554/eLife.34408
The MR-Base platform supports systematic causal inference across the human phenome
Abstract
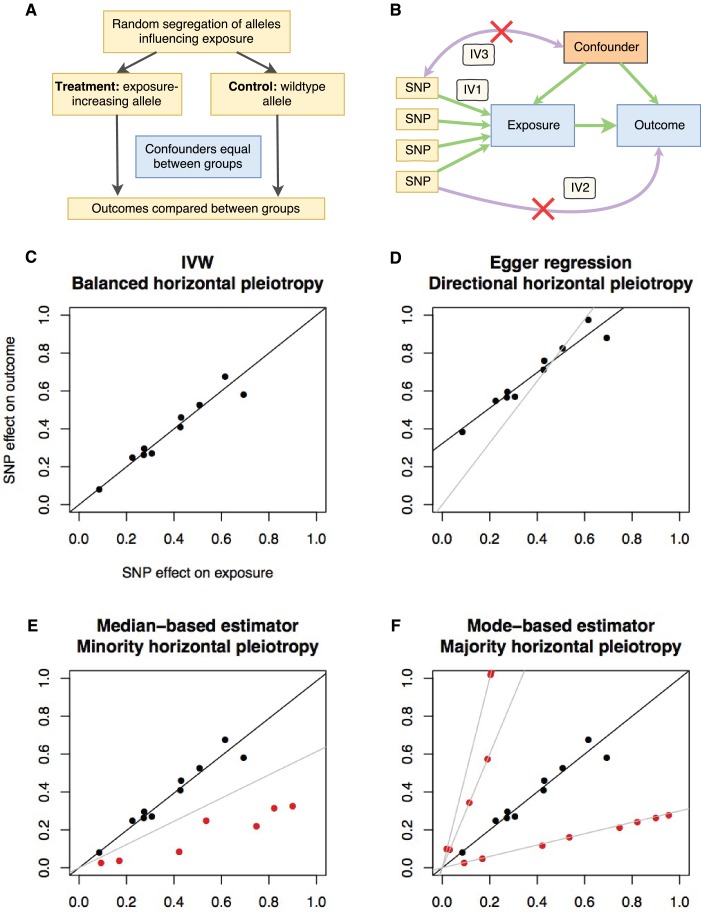
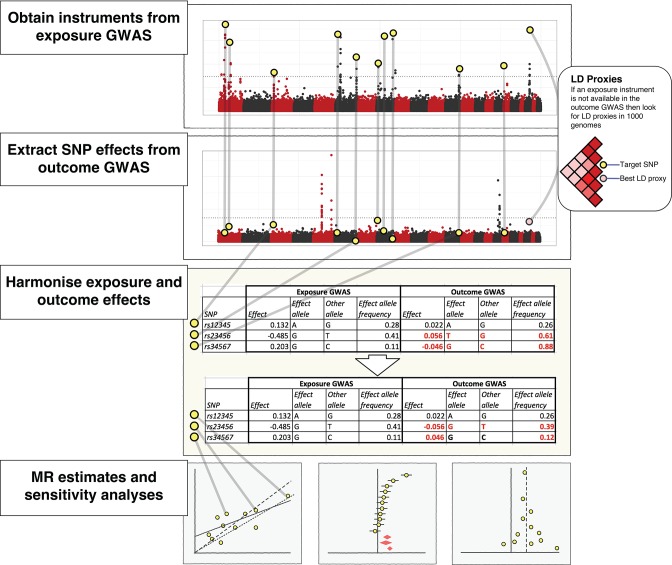
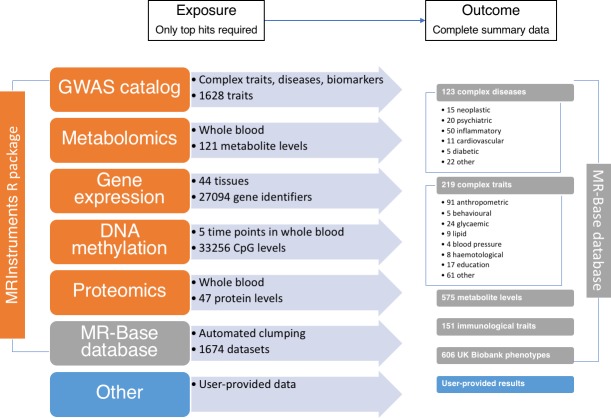
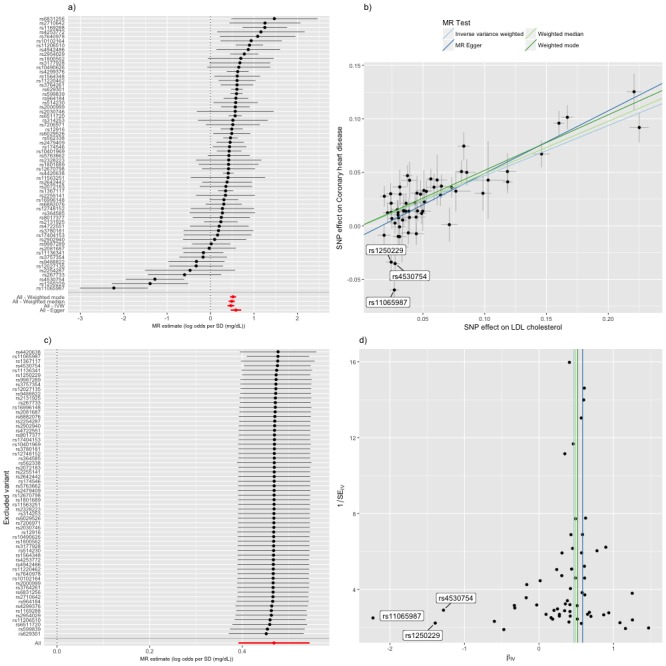
Results from genome-wide association studies (GWAS) can be used to infer causal relationships between phenotypes, using a strategy known as 2-sample Mendelian randomization (2SMR) and bypassing the need for individual-level data. However, 2SMR methods are evolving rapidly and GWAS results are often insufficiently curated, undermining efficient implementation of the approach. We therefore developed MR-Base (<ext-link ext-link-type="uri" xlink:href="http://www.mrbase.org">http://www.mrbase.org</ext-link>): a platform that integrates a curated database of complete GWAS results (no restrictions according to statistical significance) with an application programming interface, web app and R packages that automate 2SMR. The software includes several sensitivity analyses for assessing the impact of horizontal pleiotropy and other violations of assumptions. The database currently comprises 11 billion single nucleotide polymorphism-trait associations from 1673 GWAS and is updated on a regular basis. Integrating data with software ensures more rigorous application of hypothesis-driven analyses and allows millions of potential causal relationships to be efficiently evaluated in phenome-wide association studies.
Keywords: GWAS; Mendelian randomization; causal inference; computational biology; human; human biology; medicine; systems biology.
© 2018, Hemani et al.
Conflict of interest statement
GH, JZ, BE, KW, VH, DB, CL, SB, JB, RL, VT, JY, HS, NT, DE, CR, RM, GD, TG, PH No competing interests declared
Figures
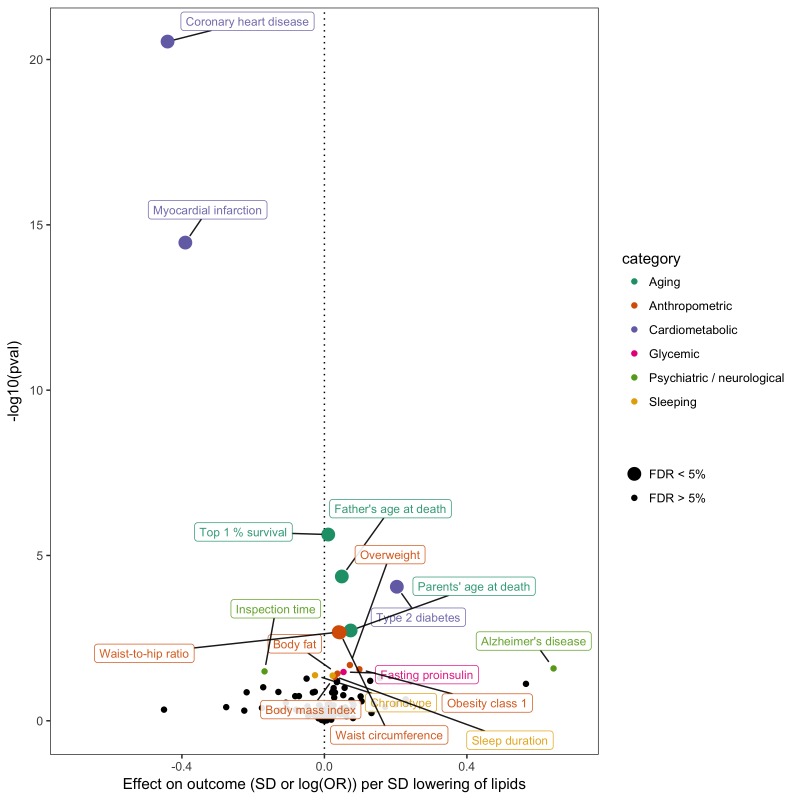
References
-
- Angrist JD, Krueger AB. Estimating the Payoff to Schooling Using the Vietnam-Era Draft Lottery. [February 1, 2018];1992 www.nber.org/papers/w4067
-
- Angrist JD, Krueger AB. Split-sample instrumental variables estimates of the return to schooling. Journal of Business & Economic Statistics. 1995;13:225–235.
Publication types
MeSH terms
Substances
Grants and funding
- 19169/CRUK_/Cancer Research UK/United Kingdom
- MC_UU_12013/3/MRC_/Medical Research Council/United Kingdom
- Population Research Postdoctoral Fellowship, C52724/A20138/CRUK_/Cancer Research UK/United Kingdom
- MR/L003120/1/MRC_/Medical Research Council/United Kingdom
- MC_UU_00002/7/MRC_/Medical Research Council/United Kingdom
- MC_UU_12013/4/MRC_/Medical Research Council/United Kingdom
- 20138/CRUK_/Cancer Research UK/United Kingdom
- MR/N501906/1/MRC_/Medical Research Council/United Kingdom
- 202802/Z/16/Z/WT_/Wellcome Trust/United Kingdom
- MC_UU_12013/8/MRC_/Medical Research Council/United Kingdom
- MC_UU_12013/2/MRC_/Medical Research Council/United Kingdom
- RG/13/13/30194/BHF_/British Heart Foundation/United Kingdom
- MC_UU_00011/2/MRC_/Medical Research Council/United Kingdom
- Methodology Research Fellowship, MR/N501906/1/MRC_/Medical Research Council/United Kingdom
- 208806/Z/17/Z/WT_/Wellcome Trust/United Kingdom
- MC_UU_12013/1/MRC_/Medical Research Council/United Kingdom
- C18281/A19169/CRUK_/Cancer Research UK/United Kingdom
- 204623/Z/16/Z/WT_/Wellcome Trust/United Kingdom
- MC_UU_00011/4/MRC_/Medical Research Council/United Kingdom
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
