

Development of sEMG sensors and algorithms for silent speech recognition
- PMID: 29855428
- PMCID: PMC6168082
- DOI: 10.1088/1741-2552/aac965
Development of sEMG sensors and algorithms for silent speech recognition
Abstract
Objective: Speech is among the most natural forms of human communication, thereby offering an attractive modality for human-machine interaction through automatic speech recognition (ASR). However, the limitations of ASR-including degradation in the presence of ambient noise, limited privacy and poor accessibility for those with significant speech disorders-have motivated the need for alternative non-acoustic modalities of subvocal or silent speech recognition (SSR).
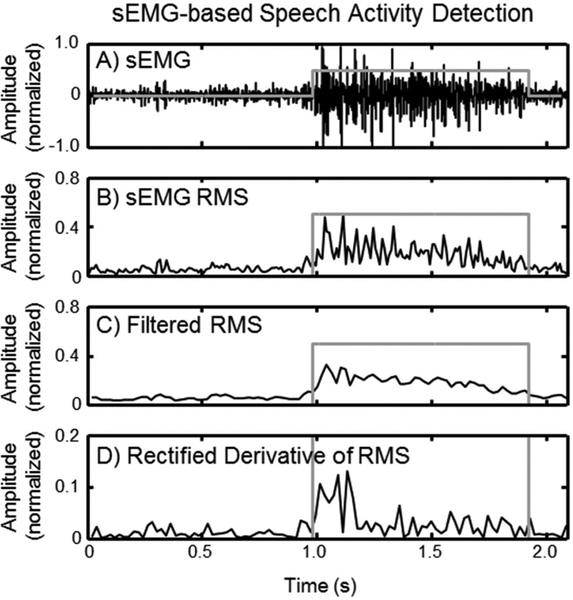
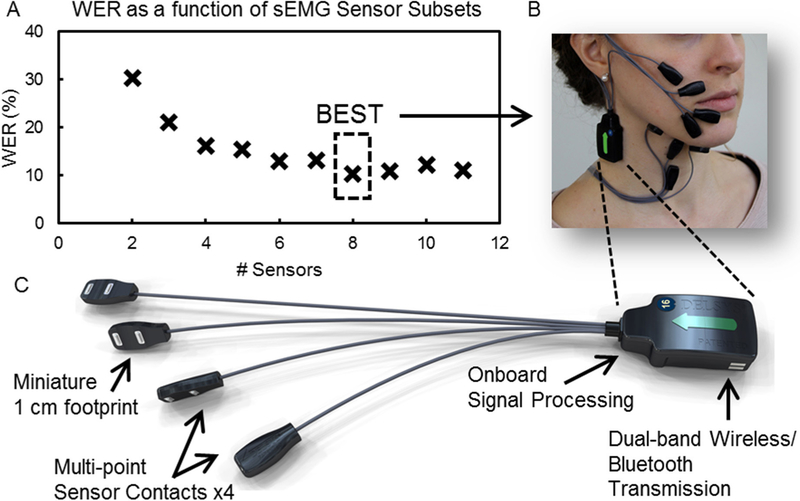
Approach: We have developed a new system of face- and neck-worn sensors and signal processing algorithms that are capable of recognizing silently mouthed words and phrases entirely from the surface electromyographic (sEMG) signals recorded from muscles of the face and neck that are involved in the production of speech. The algorithms were strategically developed by evolving speech recognition models: first for recognizing isolated words by extracting speech-related features from sEMG signals, then for recognizing sequences of words from patterns of sEMG signals using grammar models, and finally for recognizing a vocabulary of previously untrained words using phoneme-based models. The final recognition algorithms were integrated with specially designed multi-point, miniaturized sensors that can be arranged in flexible geometries to record high-fidelity sEMG signal measurements from small articulator muscles of the face and neck.
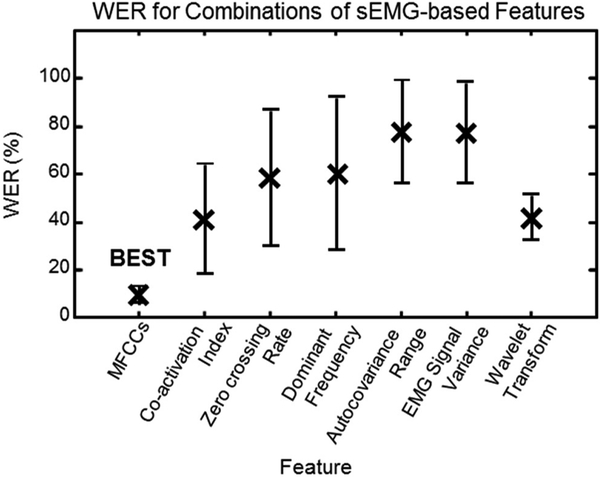
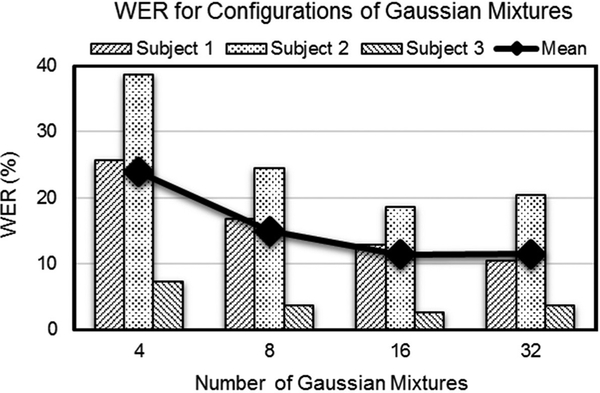
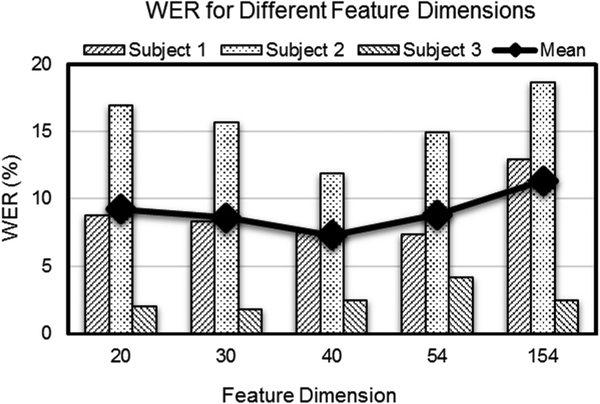
Main results: We tested the system of sensors and algorithms during a series of subvocal speech experiments involving more than 1200 phrases generated from a 2200-word vocabulary and achieved an 8.9%-word error rate (91.1% recognition rate), far surpassing previous attempts in the field.
Significance: These results demonstrate the viability of our system as an alternative modality of communication for a multitude of applications including: persons with speech impairments following a laryngectomy; military personnel requiring hands-free covert communication; or the consumer in need of privacy while speaking on a mobile phone in public.
Figures

References
-
- Betts B and Jorgensen C 2005. Small vocabulary recognition using surface electromyography in an acoustically harsh environment NASA TM-2005–21347 pp 1–16 (https://ntrs.nasa.gov/archive/nasa/casi.ntrs.nasa.gov/20050242013.pdf)
-
- Chan AD, Englehart K, Hudgkins B and Lovely DF 2001. Myoelectric signals to augment speech recognition Med. Biol. Eng. Comput 39 500–4 - PubMed
-
- EnglishSpeak 2017. Most common 1000 English phrases (www. englishspeak.com/en/english-phrases)
-
- Farooq O and Datta S 2001. Mel filter-like admissible wavelet packet structure for speech recognition IEEE Signal Process. Lett. 8 196–8
-
- Garofolo JS, Lamel LF, Fisher WM, Fiscus JG, Pallett DS, Dahlgren NL and Zue V 1993. TIMIT Acoustic-Phonetic Continuous Speech Corpus LDC93S1 Web Download (Philadelphia, PA: Linguistic Data Consortium; )
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources