

Instance-based generalization for human judgments about uncertainty
- PMID: 29864122
- PMCID: PMC6002126
- DOI: 10.1371/journal.pcbi.1006205
Instance-based generalization for human judgments about uncertainty
Abstract
While previous studies have shown that human behavior adjusts in response to uncertainty, it is still not well understood how uncertainty is estimated and represented. As probability distributions are high dimensional objects, only constrained families of distributions with a low number of parameters can be specified from finite data. However, it is unknown what the structural assumptions are that the brain uses to estimate them. We introduce a novel paradigm that requires human participants of either sex to explicitly estimate the dispersion of a distribution over future observations. Judgments are based on a very small sample from a centered, normally distributed random variable that was suggested by the framing of the task. This probability density estimation task could optimally be solved by inferring the dispersion parameter of a normal distribution. We find that although behavior closely tracks uncertainty on a trial-by-trial basis and resists an explanation with simple heuristics, it is hardly consistent with parametric inference of a normal distribution. Despite the transparency of the simple generating process, participants estimate a distribution biased towards the observed instances while still strongly generalizing beyond the sample. The inferred internal distributions can be well approximated by a nonparametric mixture of spatially extended basis distributions. Thus, our results suggest that fluctuations have an excessive effect on human uncertainty judgments because of representations that can adapt overly flexibly to the sample. This might be of greater utility in more general conditions in structurally uncertain environments.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
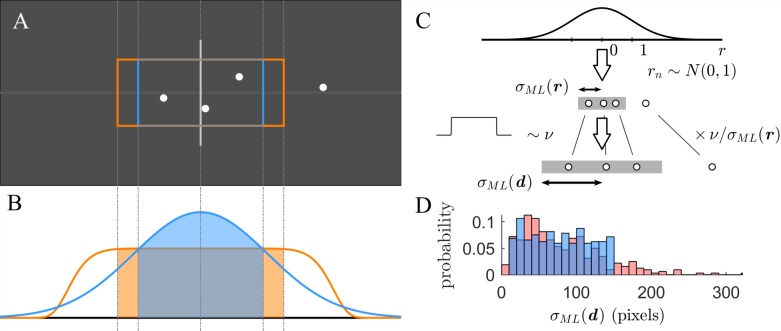
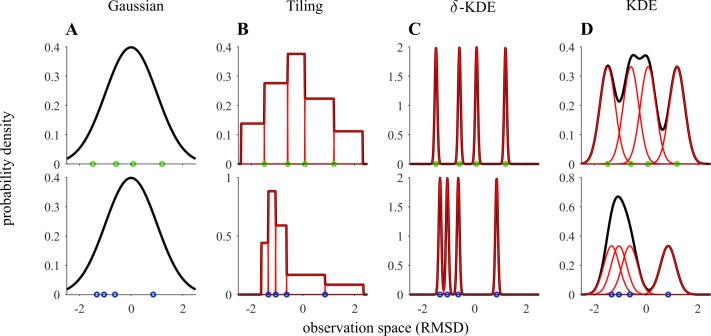
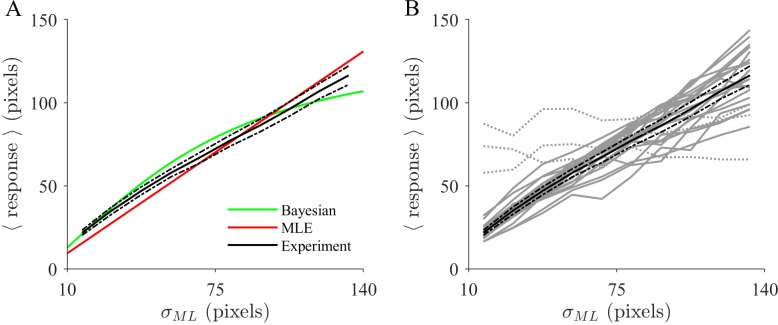
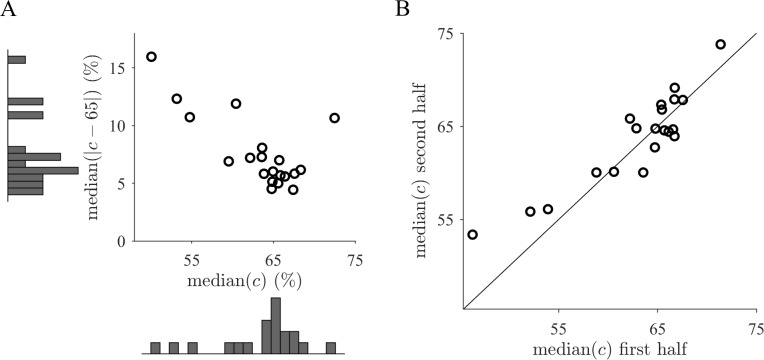
Similar articles
-
Human confidence judgments reflect reliability-based hierarchical integration of contextual information.Nat Commun. 2019 Nov 28;10(1):5430. doi: 10.1038/s41467-019-13472-z. Nat Commun. 2019. PMID: 31780659 Free PMC article.
-
Sources of uncertainty in intuitive physics.Top Cogn Sci. 2013 Jan;5(1):185-99. doi: 10.1111/tops.12009. Top Cogn Sci. 2013. PMID: 23335579
-
The Sense of Confidence during Probabilistic Learning: A Normative Account.PLoS Comput Biol. 2015 Jun 15;11(6):e1004305. doi: 10.1371/journal.pcbi.1004305. eCollection 2015 Jun. PLoS Comput Biol. 2015. PMID: 26076466 Free PMC article.
-
Nonparametric analysis of statistic images from functional mapping experiments.J Cereb Blood Flow Metab. 1996 Jan;16(1):7-22. doi: 10.1097/00004647-199601000-00002. J Cereb Blood Flow Metab. 1996. PMID: 8530558 Review.
-
Probabilistic population codes and the exponential family of distributions.Prog Brain Res. 2007;165:509-19. doi: 10.1016/S0079-6123(06)65032-2. Prog Brain Res. 2007. PMID: 17925267 Review.
Cited by
-
A confirmation bias in perceptual decision-making due to hierarchical approximate inference.PLoS Comput Biol. 2021 Nov 29;17(11):e1009517. doi: 10.1371/journal.pcbi.1009517. eCollection 2021 Nov. PLoS Comput Biol. 2021. PMID: 34843452 Free PMC article.
-
Human representation of multimodal distributions as clusters of samples.PLoS Comput Biol. 2019 May 14;15(5):e1007047. doi: 10.1371/journal.pcbi.1007047. eCollection 2019 May. PLoS Comput Biol. 2019. PMID: 31086374 Free PMC article.
-
Human confidence judgments reflect reliability-based hierarchical integration of contextual information.Nat Commun. 2019 Nov 28;10(1):5430. doi: 10.1038/s41467-019-13472-z. Nat Commun. 2019. PMID: 31780659 Free PMC article.
References
-
- Kalman RE. A New Approach to Linear Filtering and Prediction Problems. J Basic Eng. 1960;82: 35–45. doi: 10.1115/1.3662552 - DOI
-
- Pouget A, Beck JM, Ma WJ, Latham PE. Probabilistic brains: knowns and unknowns. Nat Neurosci. 2013;16: 1170–1178. doi: 10.1038/nn.3495 - DOI - PMC - PubMed
-
- Ma WJ, Jazayeri M. Neural Coding of Uncertainty and Probability. Annu Rev Neurosci. 2014;37: 205–220. doi: 10.1146/annurev-neuro-071013-014017 - DOI - PubMed
-
- Kording KP, Wolpert DM. Bayesian integration in sensorimotor learning. Nature. 2004;427: 244–247. doi: 10.1038/nature02169 - DOI - PubMed
-
- Trommershäuser J, Gepshtein S, Maloney LT, Landy MS, Banks MS. Optimal Compensation for Changes in Task-Relevant Movement Variability. J Neurosci. 2005;25: 7169–7178. doi: 10.1523/JNEUROSCI.1906-05.2005 - DOI - PMC - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
