

Automatically identifying, counting, and describing wild animals in camera-trap images with deep learning
- PMID: 29871948
- PMCID: PMC6016780
- DOI: 10.1073/pnas.1719367115
Automatically identifying, counting, and describing wild animals in camera-trap images with deep learning
Abstract
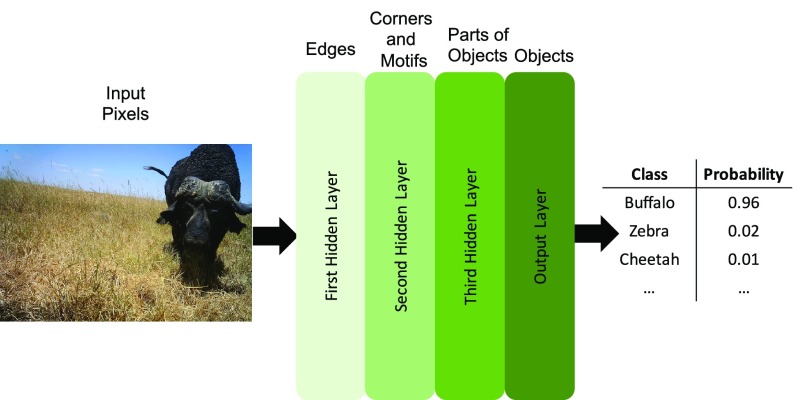
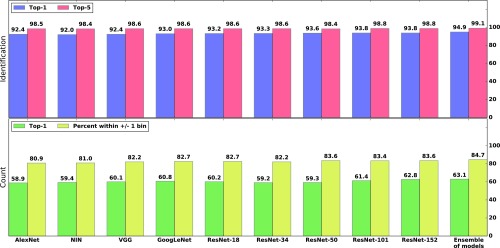
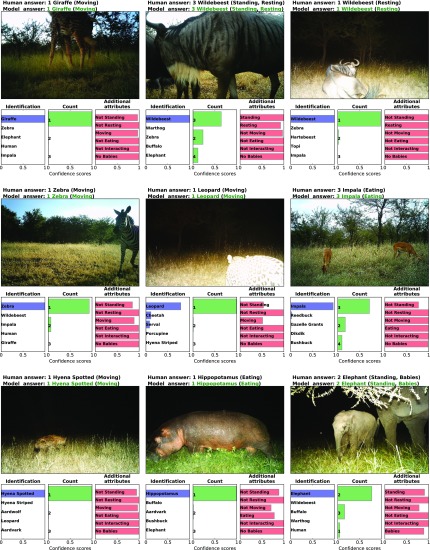
Having accurate, detailed, and up-to-date information about the location and behavior of animals in the wild would improve our ability to study and conserve ecosystems. We investigate the ability to automatically, accurately, and inexpensively collect such data, which could help catalyze the transformation of many fields of ecology, wildlife biology, zoology, conservation biology, and animal behavior into "big data" sciences. Motion-sensor "camera traps" enable collecting wildlife pictures inexpensively, unobtrusively, and frequently. However, extracting information from these pictures remains an expensive, time-consuming, manual task. We demonstrate that such information can be automatically extracted by deep learning, a cutting-edge type of artificial intelligence. We train deep convolutional neural networks to identify, count, and describe the behaviors of 48 species in the 3.2 million-image Snapshot Serengeti dataset. Our deep neural networks automatically identify animals with >93.8% accuracy, and we expect that number to improve rapidly in years to come. More importantly, if our system classifies only images it is confident about, our system can automate animal identification for 99.3% of the data while still performing at the same 96.6% accuracy as that of crowdsourced teams of human volunteers, saving >8.4 y (i.e., >17,000 h at 40 h/wk) of human labeling effort on this 3.2 million-image dataset. Those efficiency gains highlight the importance of using deep neural networks to automate data extraction from camera-trap images, reducing a roadblock for this widely used technology. Our results suggest that deep learning could enable the inexpensive, unobtrusive, high-volume, and even real-time collection of a wealth of information about vast numbers of animals in the wild.
Keywords: artificial intelligence; camera-trap images; deep learning; deep neural networks; wildlife ecology.
Copyright © 2018 the Author(s). Published by PNAS.
Conflict of interest statement
The authors declare no conflict of interest.
Figures




References
-
- Harris G, Thompson R, Childs JL, Sanderson JG. Automatic storage and analysis of camera trap data. Bull Ecol Soc Am. 2010;91:352–360.
-
- O’Connell AF, Nichols JD, Karanth KU. Camera Traps in Animal Ecology: Methods and Analyses. Springer; Tokyo: 2010.
-
- Silveira L, Jacomo AT, Diniz-Filho JAF. Camera trap, line transect census and track surveys: A comparative evaluation. Biol Conserv. 2003;114:351–355.
-
- Bowkett AE, Rovero F, Marshall AR. The use of camera-trap data to model habitat use by antelope species in the Udzungwa mountain forests, Tanzania. Afr J Ecol. 2008;46:479–487.
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
