

A Data Colocation Grid Framework for Big Data Medical Image Processing: Backend Design
- PMID: 29887668
- PMCID: PMC5991614
- DOI: 10.1117/12.2293694
A Data Colocation Grid Framework for Big Data Medical Image Processing: Backend Design
Abstract
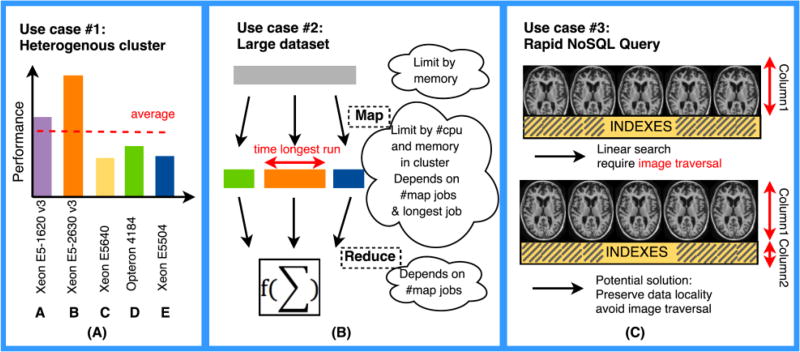
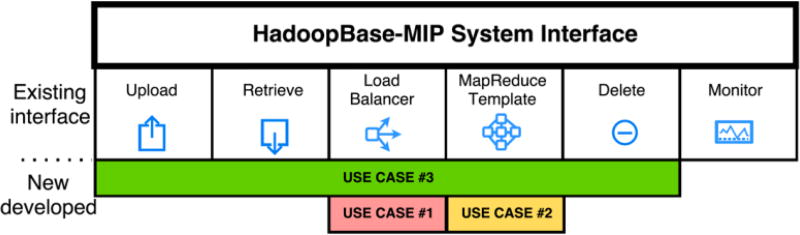
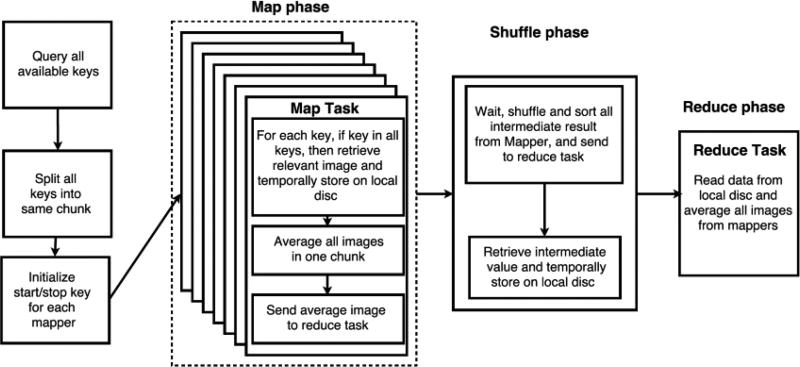
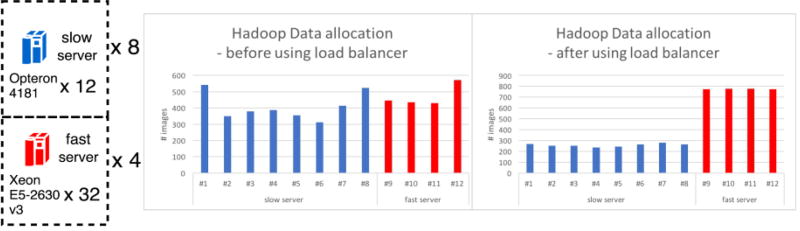
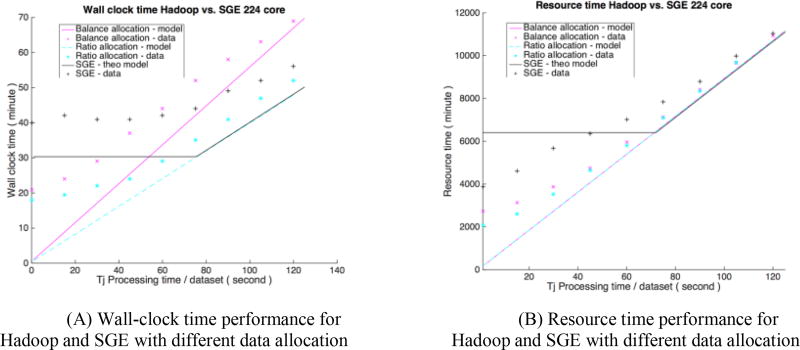
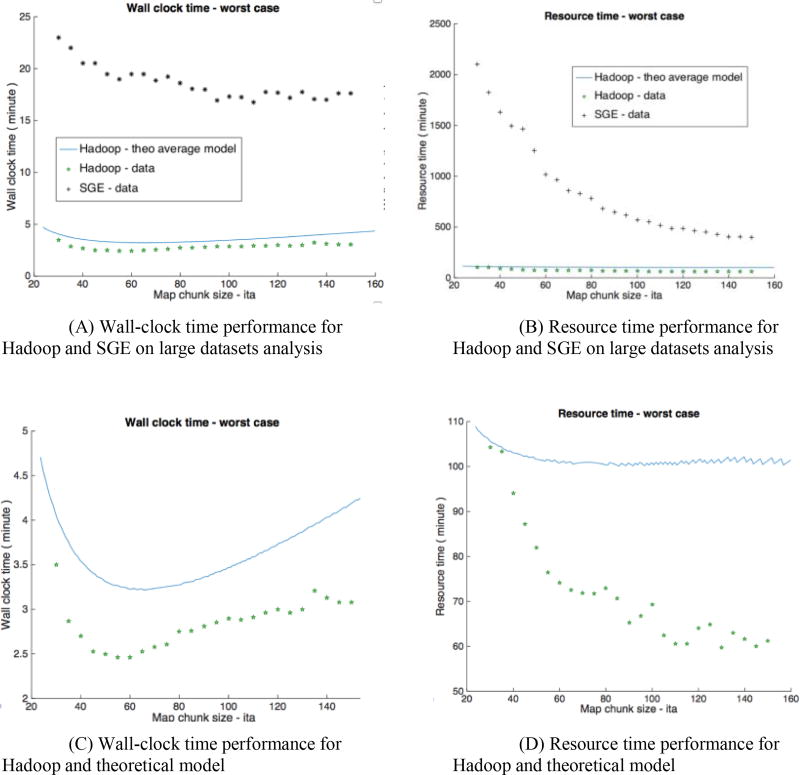
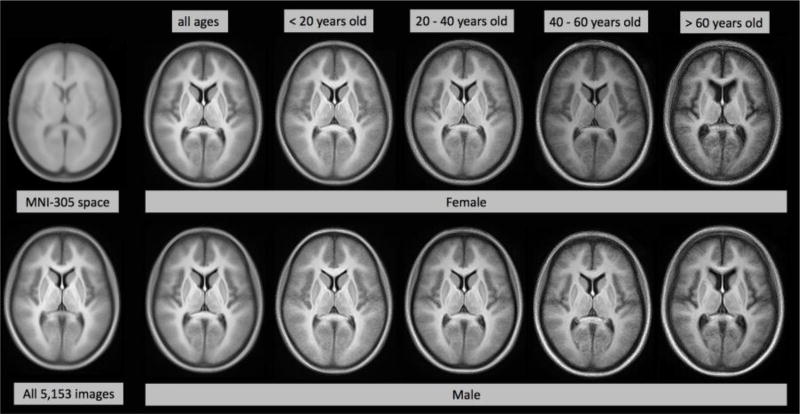
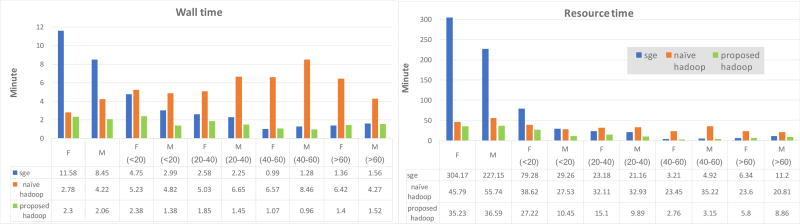
When processing large medical imaging studies, adopting high performance grid computing resources rapidly becomes important. We recently presented a "medical image processing-as-a-service" grid framework that offers promise in utilizing the Apache Hadoop ecosystem and HBase for data colocation by moving computation close to medical image storage. However, the framework has not yet proven to be easy to use in a heterogeneous hardware environment. Furthermore, the system has not yet validated when considering variety of multi-level analysis in medical imaging. Our target design criteria are (1) improving the framework's performance in a heterogeneous cluster, (2) performing population based summary statistics on large datasets, and (3) introducing a table design scheme for rapid NoSQL query. In this paper, we present a heuristic backend interface application program interface (API) design for Hadoop & HBase for Medical Image Processing (HadoopBase-MIP). The API includes: Upload, Retrieve, Remove, Load balancer (for heterogeneous cluster) and MapReduce templates. A dataset summary statistic model is discussed and implemented by MapReduce paradigm. We introduce a HBase table scheme for fast data query to better utilize the MapReduce model. Briefly, 5153 T1 images were retrieved from a university secure, shared web database and used to empirically access an in-house grid with 224 heterogeneous CPU cores. Three empirical experiments results are presented and discussed: (1) load balancer wall-time improvement of 1.5-fold compared with a framework with built-in data allocation strategy, (2) a summary statistic model is empirically verified on grid framework and is compared with the cluster when deployed with a standard Sun Grid Engine (SGE), which reduces 8-fold of wall clock time and 14-fold of resource time, and (3) the proposed HBase table scheme improves MapReduce computation with 7 fold reduction of wall time compare with a naïve scheme when datasets are relative small. The source code and interfaces have been made publicly available.
Figures
References
-
- Apache Hadoop Project Team. The Apache Hadoop Ecosystem
-
- Apache HBase Team. Apache hbase reference guide
-
- Dean J, Ghemawat S. MapReduce: simplified data processing on large clusters. Communications of the ACM. 2008;51(1):107–113.
-
- Jiang J, Lu J, Zhang G, et al. Scaling-up item-based collaborative filtering recommendation algorithm based on hadoop; 2011 IEEE Word Congress; pp. 490–497.
-
- Walunj SG, Sadafale K. Proceedings of the 2013 annual conference on Computers and people research. ACM; 2013. An online recommendation system for e-commerce based on apache mahout framework; pp. 153–158.
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources